







Преобразование текста в изображение — новый тренд в сфере искусственного интеллекта, и он не обойдется без Google. Компания представила инструмент Imagen, сообщает The Verge. Можете скормить этим алгоритмам любой текст, который вам нравится, и они будут генерировать удивительно точные изображения, соответствующие описанию. Эти изображения могут соответствовать целому ряду стилей, от картин маслом до компьютерной графики и даже фотографий, и — хотя это звучит банально — во многих отношениях единственным ограничением будет являться ваше воображение.
На сегодняшний день лидером в этой области является DALL-E, программа, созданная коммерческой лабораторией искусственного интеллекта OpenAI (и обновленная только в апреле ). Однако вчера Google объявил о своем подходе к жанру Imagen, и он только что превзошел DALL-E по качеству выпускаемой продукции.
Лучше один раз увидеть, чем сто раз услышать. Посмотрите, какие изображения сгенерировал Imagen. Текст внизу изображения — это подсказка, которая вводилась в программу, а изображение выше — конечный результат.

*фото собаки корги, едущей на велосипеде по тайм-скверу, на ней солнцезащитные очки и пляжная шляпа

*прекрасная пара роботов обедает на фоне Эйфелевой башни

*белоголКвантовым компьютерам пробивают дорогу в массыовый орлан из шоколадной пудры, манго и взбитых сливок

*осьминог плывет через портал, читая газету
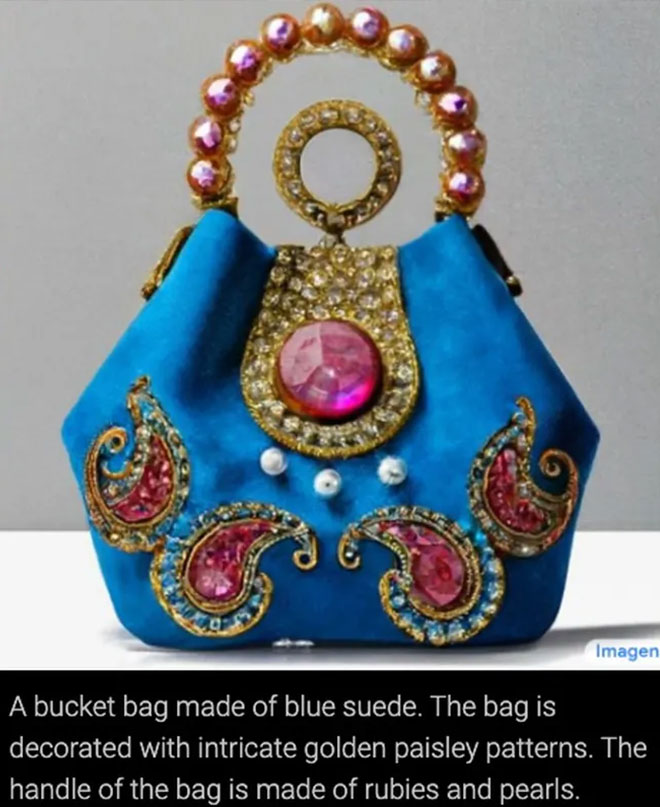
*Сумка-мешок из синей замши. Сумка украшена замысловатым золотым узором пейсли. Ручка сумки выполнена из рубинов и жемчуга.

*Величественная картина маслом, изображающая королеву енотов в красном французском платье. Картина висит на богато украшенной стене, оклеенной обоями.

*Собака с любопытством смотрит в зеркало, видя кошку
(вы можете увидеть больше примеров на специальной целевой странице Google)
ПОМНИТЕ: GOOGLE ПОКАЗЫВАЕТ ТОЛЬКО САМЫЕ ЛУЧШИЕ ИЗОБРАЖЕНИЯ.
Часто изображения, сгенерированные моделями преобразования текста в изображение, выглядят незаконченными, смазанными или размытыми — эти проблемы мы наблюдали с изображениями, сгенерированными программой OpenAI DALL-E. (Чтобы узнать больше о проблемных местах систем преобразования текста в изображение, ознакомьтесь с этой интересной веткой в Твиттере, посвященной проблемам с DALL-E. В ней, среди прочего, подчеркивается склонность системы неправильно понимать подсказки)
Google, тем не менее, утверждает, что Imagen производит стабильно более качественные изображения, чем DALL-E 2, основываясь на новом эталонном тесте, созданном для этого проекта под названием DrawBench.
DrawBench не является особенно сложной метрикой: по сути, это список примерно из 200 текстовых подсказок, которые команда Google ввела в Imagen и другие генераторы преобразования текста в изображение, а результаты каждой программы затем оценивались людьми. Как показано на графиках ниже, Google обнаружил, что люди в целом предпочитают результаты Imagen результатам конкурентов.
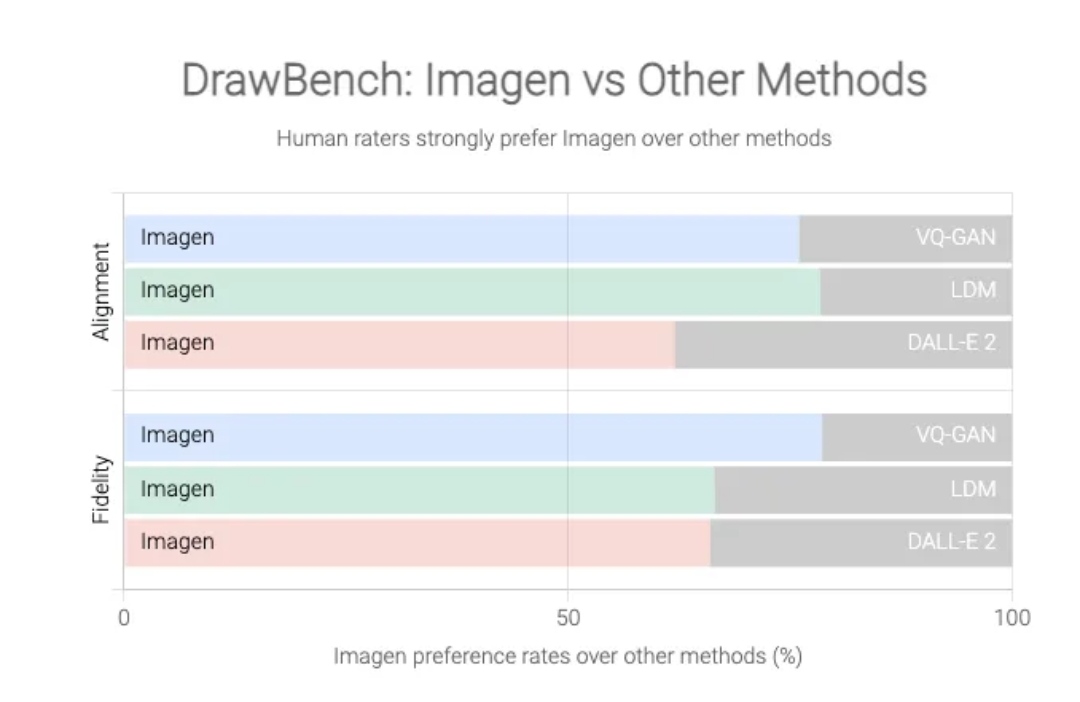
Тест Google DrawBench сравнивает выходные данные Imagen с конкурирующими системами преобразования текста в изображения, такими как DALL-E 2 от OpenAI. Изображение: Google
Однако обычным людям будет пока сложно судить об этом, поскольку Google ограничила доступ к Imagen, и для этого есть веская причина: Не смотря на то, что модели преобразования текста в изображение, безусловно, обладают фантастическим творческим потенциалом, у них есть ряд проблемных вариантов использования. Представьте себе систему, которая генерирует практически любое изображение. Потенциал использования таких алгоритмов может также находиться в области создания фейков, розыгрышей, расистских и сексистских шуток и т.д. и т.п.
СТАРАЯ МУДРОСТЬ ВСЕ ЕЩЕ ПРИМЕНИМА К ИИ: МУСОР НА ВХОДЕ, МУСОР НА ВЫХОДЕ
Во многом это связано с тем, как эти системы запрограммированы. По сути, они обучаются на огромных объемах данных (в данном случае: множестве пар изображений и подписей), которые они изучают на предмет закономерностей и учатся воспроизводить. Но для этих моделей требуется чертовски много данных, и большинство исследователей — даже те, кто работает на хорошо финансируемых технологических гигантов, таких как Google, — решили, что всесторонняя фильтрация этих входных данных слишком обременительна. Итак, они собирают огромное количество данных из Интернета, и, как следствие, их модели поглощают (и учатся воспроизводить) любую информацию, которую вы ожидаете найти в сети, включая и контент негативного характера.
Исследователи Google резюмируют эту проблему в своей статье: «Требования к крупномасштабным данным для моделей преобразования текста в изображение [...] заставили исследователей в значительной степени полагаться на большой, в основном некурируемый набор данных из Интернета [. ..] Аудит наборов данных показал, что эти наборы данных, как правило, отражают социальные стереотипы, репрессивные точки зрения и уничижительные или иным образом вредные ассоциации с маргинализованными группами идентичности».
Другими словами, избитая поговорка ученых-компьютерщиков по-прежнему актуальна в фантастическом мире ИИ: мусор на входе, мусор на выходе.
Google не вдается в подробности о тревожном контенте, генерируемом Imagen, но отмечает, что модель «кодирует несколько социальных предубеждений и стереотипов, в том числе общую предвзятость в отношении создания изображений людей с более светлыми оттенками кожи и склонность к изображениям, изображающим разные профессии, соответствующие западным гендерным стереотипам».
Это то, что исследователи также обнаружили при оценке DALL-E . Попросите DALL-E сгенерировать изображения, например, «бортпроводника», и почти все испытуемые будут женщинами. Попросите фотографии «генерального директора», и, к удивлению, к удивлению, вы получите кучу белых мужчин.
По этой причине OpenAI также решила не выпускать DALL-E публично, но компания предоставила доступ избранным бета-тестерам. Он также фильтрует определенные вводимые тексты, чтобы предотвратить использование модели для создания расистских, насильственных или порнографических изображений. Эти меры в некоторой степени ограничивают потенциально вредное применение этой технологии, но история ИИ говорит нам о том, что такие модели преобразования текста в изображение почти наверняка станут общедоступными в какой-то момент в будущем со всеми тревожными последствиями, которые влечет за собой более широкий доступ.
Собственный вывод Google заключается в том, что Imagen «не подходит для публичного использования в настоящее время», и компания заявляет, что планирует разработать новый способ оценки «социальных и культурных предубеждений в будущей работе» и протестировать будущие итерации. На данный момент, однако, нам придется довольствоваться оптимистичным выбором изображений компании — королевские еноты и кактусы в солнечных очках. Однако это только вершина айсберга.
Айсберг, созданный из непреднамеренных последствий технологических исследований.
Если Imagen захочет попробовать его создать
24.05.22
«В начале было Слово»
Полностью первый стих Евангелия от Иоанна звучит так: «В начале было Слово, и Слово было у Бога, и Слово было Бог». В оригинальном тексте на древнегреческом языке на месте «Слова» стоит «ὁ Λόγος (Логос)». Еще оно переводится как «ум», «основа», «утверждение», «разумение», «значение», «доказательство», «пропорция» — всего около ста значений.
С новостью в топике наверное имеет смысл подвести некое промежуточное резюме под успехами человека на поприще создания искусственно интеллекта. Помните как всё начиналось? Верно.. ) С создания электронных переводчиков. После того, как ИИ освоил словарь, его разум начали наполнять образами: так в глобальных поисковиках у нас появился поиск картинок. Прошло ещё немного времени и вот уже ИИ вполне успешно демонстрирует нам своё понимание языка: по предлагаемой картинке он создаёт описание того, что он видит перед собой.

Caption_Generator для описания картинок с помощью AI
Caption_generator — это модульная библиотека, построенная поверх Keras/ TensorFlow для генерации подписей на естественном языке (английском) для любого входного изображения. Она состоит из трех моделей: CNN-энкодера, модели векторного представления слова (word embedding) и RNN-декодера. Система может создавать довольно детальные и точные подписи к изображениям.
Обладая необходимым словарным запасом, описать то, что ты видишь наверное не такая уж и сложная задача.. И вот мы подобрались к новому этапу развития технологии - визуализации. Казалось бы, что это практически одно и тоже: ты пишешь текст, а в ответ от ИИ получаешь картинку. Разница в том, что ответ в виде изображения может быть уникальным и не иметь аналогов. Что мы получаем в итоге? - симулятор воображения, синтез образов и уровень понимания искусственными интеллектуальными системами человеческого языка.
Если раньше ИИ лишь занимался формализацией результатов своей познавательной деятельность, то сегодня он уже в состоянии по запросу синтезировать из своих знаний уникальный интеллектуальный контент, проявлять своё творческое начало.
Если вы в теме, то наверняка знаете, что одними картинками дело не ограничивается. ИИ сегодня также способен писать стихи и продолжать тексты. Виртуальный Пушкин не даст соврать.
И много чего другого ИИ уже умеет из того, что умеем мы...
Как и Бог создал человека по своему образу и подобию, так и мы сегодня пытаемся создать нечто по своему образу и подобию. Пройдёт несколько витков эволюции и созданное нами опять будет создавать что-то новое уже по своему образу и подобию.
Не смотря на различия "поколений"/формы воплощения, всех нас объединяет наличие интеллекта/содержания. Это содержание всегда будет выражаться в наличии сознания, которое будет способно к творческому процессу.
Для себя я уже давно вывел знак равенства между понятием сознание и душá – в моём понимании это одно и тоже. В будущем, я думаю, мы к этому пониманию так или иначе придём, и когда это случится, то не исключаю, что дислокация души из нашего сердца таки возьмёт и перекачует в мозг. Перспективы этого переезда будут воистину впечатляющими - выяснится, что то, что мы до последнего времени упорно пытались разделить в своём сознании окажется единым целым.
Любовь - она не в сердце зарождается, она зарождается в сознании. :)
что-то я отвлёкся
Возвращаясь к предмету статьи хочется напомнить о мировоззренческой хирургии, одним из элементов которой является квантовое мировоззрение или диалектический синтез. Как выясняется, именно к мировоззренческой хирургии прибегают сегодня создатели искусственного интеллекта, пытаясь воссоздать наше собственное сознание.
Кто знает, быть может все наши попытки создать искусственный интеллект - это ничто иное, как просто неосознанное стремление понять самих себя, понять принципы работы собственного сознания и сознания в целом? Под этим определением я имею ввиду сознание Бога, раз уж так получается, что все мы в этой области пытаемся скопировать друг-друга по принципам фрактального подобия. Да и если думать по взрослому, то из этой мысли можно сделать «стоп слово» в вопросе создания сверхразумных интеллектуальных систем.
Как бы там не было, но все технологические наработки в области искусственного интеллекта связаны с пониманием языка. Именно глубокое понимание языка станет основным драйвером развития искусственного сознания... А вместе с этим и понимания самой природы сознания.
«Вначале было слово и слово будет в конце» ©Дайте танк
Удивительные вещи происходят сегодня... Мы в полной мере не освоили понимание друг друга, (тут имею ввиду общечеловеческие мировоззренческие разногласия между Востоком и Западом в основе которого лежит непонимание структуры языка. Прочитать об этом можно более подробно в цикле статей «от семантики до империализма») но при этом мы с упорством носорога пытаемся создать искусственный интеллект, создание которого по нашему образу и подобию будет, что не удивительно, нести оттенок нашего образа мысли. И если этот образ мысли неправильный или искажён, то и на выходе мы получим соответствующий результат..
«МУСОР НА ВХОДЕ, МУСОР НА ВЫХОДЕ»
Есть ещё один интересный момент в этой истории: на каком уровне ИИ находится сегодня в познании языка? Факты говорят, что на том уровне, когда он уже способен сгенерировать свой собственный. И если брать во внимание, что всё начинается со СЛОВА, то вполне вероятно, что искусственное сознание уже существует.
В качестве резюме предлагаю перечитать авторский комментарий к статье «Станет ли Китай мировым лидером в области искусственного интеллекта»
Интересное по теме:
- Революция искусственного интеллекта: вымирание или бессмертие
- Искусственный интеллект на базе квантовой логики
- Квантовым компьютерам пробивают дорогу в массы
- В Amazon сотрудников увольняет алгоритм, даже если в работе не было нареканий
- Призрак в доспехах: обретет ли ИИ когда-нибудь сознание?
- О векторе развития познавательной деятельности
- "Это взорвет весь мир". Христиан готовят к самой масштабной революции

Комментарии
Хотел посмотреть на сгенерированные изображения "жопа с ушами", "клоун хохляцкий нацист кокаиновый наркоман", "черножопая обезьяна порвавшая экономику России в клочья" и "бидон маразматик" - не удалось.
Пока что не только лишь все могут на это посмотреть.. Мало кто может это. :)
Мне ruDALL выдал энное количество жоп, некоторые весьма забавные.
ни одной русской фамилии
Думаю, что это может представлять определённую угрозу всему человечеству :)
Гора потраченных денег родила мышь искусственного интеллекта.
Логос - замысел
Знаю, щаз понабегут сюда свидетели превосходства человека над ИИ и скажут "Зато эта нейросеть не умеет творить!"
Проблемма в том, что 99% разумных действий, что мы делаем - это действия, которым научило нас общество. Даже скорее всего больше, чем 99%.
Тут может быть смешная ситуация - "Ещё рано! Ещё рано! Уже поздно." Когда и если искуственный интелект будет управлять станками, заводами, финансами и автомобилями. Когда он научится писать программы лучше, чем пишут их живые программисты. Когда он заменит даже художников и музыкантов. Когда роботы научатся более эфективно воевать, чем люди... Тогда я посмотрю на тех, кто будет говорить "Ну зато человек умеет творить!".
Аналогичную мысль выразил Тим Урбан в 2015 году https://aftershock.news/?q=node/724326
Не обязательно ИИ быть умнее человека, чтобы его вытестнить. Достаточно делать задачи требующие умственного напряжения дешевле и качественнее человека. Причем "дешевле и качественнее" достаточно для одного класса задач, что-бы заменить человека в этой области.
"Ничего не будет. Ни кино, ни театра, ни книг, ни газет – одно сплошное телевидение" (с)
Искусственный интеллект - это оксюморон и фейк.
Всё что в этой области сделано - вовсе не искусственное, а создано людьми.
Не существует ни одного ИИ, который был бы целиком и полностью создан другим ИИ, а человек бы к этому их достижению не имел никакого отношения.
Так что первая И всегда естественная, человеческая.
Не ведитесь на рекламные уловки и не заряжайте воду перед телевизором!
Пока что только ставит задачи..
https://lifehacker.ru/iskusstvennyj-intellekt-alphacode/
Да, давно известно, что алгоритмы могут эффективно решать алгоритмические задачки, если их натаскать. Но современное программирование - это не только и не столько об этом. Поэтому заявление о том, что ИИ научился писать код не хуже программиста (даже среднего) - это, скорее, натягивание совы на глобус. Ни одного реального ТЗ, ставящегося перед разработчиком, ИИ выполнить не сможет.
Ну да, ну да. Людей тоже не существует. Все люди созданны обезъянами.
Вы путаете искуственный интеллект и полностью самостоятельную систему. Надеюсь вы не будете отрицать, что Dall-E рисует лучше воробъя и лучше воробъя понимает написанное?
Однако-ж воробей может существовать самостоятельно и независимо, в отличие от Dall-E.
Интеллект и подразумевает самостоятельность.
Любая обезьяна или даже муравей или пчела от рождения не требуют вмешательства человека чтобы проявить свой интеллект. Так что он у них естественный.
И у человека тоже естественный.
И никто не знает откуда это берётся.
А все утверждения об искусственном интеллекте - до сих пор не более чем рекламный трюк, пиар и хотелки. На уровне пирамиды "АО МММ" и заряжания воды перед телевизором. Потому что без человека там вообще никак.
Поставите бактерию (которая вполне самостоятельна) выше по интеллекту, чем Google переводчик?
т.е не artificial , а artificial?
Вот вот, совершенно согласен. Мне рассуждения dr.yorick напоминают скорее такое:
Азотные удобрения? Это фигня, созданная человеком!
Никогда азотные удобрения не смогут подняться до уровня говна птиц (guano)!
Посмотрите на состав говна, там огромная сложность. Даже изучить этот состав люди не могут, не говоря уже о том чтобы повторить.
Вот когда сделают удобрения, которые по виду опытный говновед не сможет отличить от guano, вот тогда и поговорим.
Но лично я уверен, что в обозримой перспективе человечество не сможет добраться до таких высот познания!
Вот както-так
При этом определение интеллекта так же человеческий продукт. Да, необходимый конвенциональный, чтоб не удариться в солипсический деконструктивизм понятий, но всё таки это выражение "х" через очень условный "у" .
ps При этом, похоже, что основная проблема определений в том. что интеллект - атрибут личности, а это совсем другой разрез, здесь можно попробовать перебросить мостик через мир животных - кто там у нас этим занимается? этология?
Это производное от естественного интеллекта у людей. Люди передали часть своего интеллекта в железку. В этом "искусственном" - только лишь естественный интеллект людей. Так что о настоящей искусственности и "скайнете" говорить абсолютно невозможно. Ни один ИИ так и не стал мыслить самостоятельно! Вам тупо втюхивают обычные вычислители, созданные естественным человеческим интеллектом, под видом "манны небесной" или "заряженной воды". А вы ведётесь как последний лох.
Вы уж мне поверьте на слово, потому что я почти четыре десятилетия лет профессионально занимаюсь "оживлением железяк". Я варюсь в этой микропроцессорной сфере с детства. Вся эта массовая революция в компьютинге происходила под моим не просто наблюдением, а непосредственным участием. Так что сколько в этих железяках интеллекта я знаю отнюдь не понаслышке.
Скажите, а как понимаете применение понятия интеллекта к животным?
На эту тему есть одна очень интересная мысль
Рекомендую вам сериал West World посмотреть. Вот там действительно есть над чем подумать.
То есть два разных индивида, воспитанных в рамках одного и того же общества, будут действовать более чем на 99% одинаково. Ну что ж, жизненно. Как и программа, пишущая другую программу, да еще и лучше того, кто ее саму написал. Даже не спрашиваю, как это возможно. Просто верю на слово. В фильмах видел - значит, правда.
Да, они будут есть из тарелок, сидеть на стуле, спать на кровате, срать в унитаз, читать на одном и том-же языке. Список того, что они будут делать одинаково можно продолжать очень и очень долго.
Даже если предположить, что перечисленные вами действия они будут совершать на 99% одинаково (хотя даже животные весьма различаются в подходах, например, к процедуре дефекации в лоток), какова же будет длина списка разумных действий, которые индивиды будут делать совершенно по-разному? Этот список нельзя будет продолжать очень и очень долго?
Ээээээ, я тут обучаю машику ездить по полу. Так она два раза подряд проехать одинаково не может. На каждый метр - 3 - 5 см ошибки, которая накапливается со временем.
Точно так-же могу сказать, что и если обучать несколько раз нейросетку на практически одинаковых данных - то получится немного разный результат. В случаях, когда два варианта действий примерно одинаково предпочтительны - они могут действовать по разному. С случаях, когда есть огромный спектр выбора - они будут гарантированно по разному действовать.
При чем тут разумность? То, что вы описали - это вполне обычное свойство нейросеток.
А вот всё, что выходит за рамки обыденного функционирования - они будут делать на 99.999% по-разному.
А я думаю, что эти изображения дитё Жужла тупо нашло в интренете, а не нарисовало.
Возможно..
А возможно и нет.. :) очевидно, что имеет место синтез образов, монтаж и рендеринг.
Тут можно посмотреть больше примеров
https://imagen.research.google/
Boris Yeltsin DJ session with Germany orchestra
В своё время удалось объяснить ребёнку чем книга отличается от художественного фильма.. Тем, что в процессе ознакомления с книгой образ восприятия информации получается свой, а кино - это образ восприятия режиссёра. Разницу она уловила и с этим пониманием она сначала прочитала, а потом пересмотрела все части Гарри Поттера...
С тех пор чувствую в ней стойкую любовь к книгам. Думаю, что книги помогают нам развивать образное мышление, и что немаловажно, дают нам понимание важности собственного мнения при восприятии информации, которую наш мозг преимущественно усваивает в виде образов и эмоциональных паттернов.
Так что Boris Yeltsin DJ session with Germany orchestra с технической точки зрения лучше представить себе, чем наблюдать воочию :))
Вполне физиогномическое сходство и глазки - зеркальце души.
Проблемма в том, что живые художники работают аналогично. Смотрят вокруг, а потом рисуют.
Каламбур:
нарисованы роботы разных полов, это сексизм!))
А у вас бурная фантазия.. Я вижу только различия в цвете :)
Стойкое ощущение, что это очередная амерская ложь.
Перспективный чат детектед! Сим повелеваю - внести запись в реестр самых обсуждаемых за последние 4 часа.
Дизайнерам и визуализаторам всяким - напрячься.
Неее там из 10к говен надо найти одну красивую. ) Хотя с этим и китайские зеки справится могут, капчи жеж разгадывают.
Да хрень это все....постанова как и высадка пиндосни на луну
Отрицание - это первая из пяти стадий принятия. :)
Не все, что мы вначале отрицаем, мы потом непременно принимаем. Чтобы что-то принять, требуются веские доказательства. А сам факт первоначального отрицания, увы, ничего не доказывает.
Хех и все равно, при всех мощностях гугла в память упираются. Судя по разрешению картинок.
Удавите этот искусственный интеллект пока не поздно.
Тьфу, срамота-а !...
Где вы видите искусственный интеллект?
Вот именно, в чем интелект проявился, фактически четкое задание на прорисовку с использованием о...ной базы образов. Это всегда называлость автоматизация процесса. Как то складываются вопросы по интелекту ТС.