


















Комментарий редакции раздела Технологии
Это кстарело в 2014 в 2016 должна была начать работу лаборатория прорывных направлений.
[video:https://www.youtube.com/watch?v=trkAtd9QUws]







Это кстарело в 2014 в 2016 должна была начать работу лаборатория прорывных направлений.
[video:https://www.youtube.com/watch?v=trkAtd9QUws]
Комментарии
ОК
Но описание проблемы на которой Вы сломались прошу предоставить)
Это будет ЕГО работа, не имеющая к Вам никакого отношения.
Как писалось в старом стишке
Без смелых идей не бывает открытий. Скольким великим мужам говорили, что у них ничего не выйдет. А вышло только у тех, кто нашел силы не опустить руки. Удачи и надежных товарищей Вам, пусть все получится.
Спасибо
Дружище, я пытался реализовать похожий алгоритм (с перестановкой битов) и заткнулся при реализации. Потому и советую попробовать реализовать.
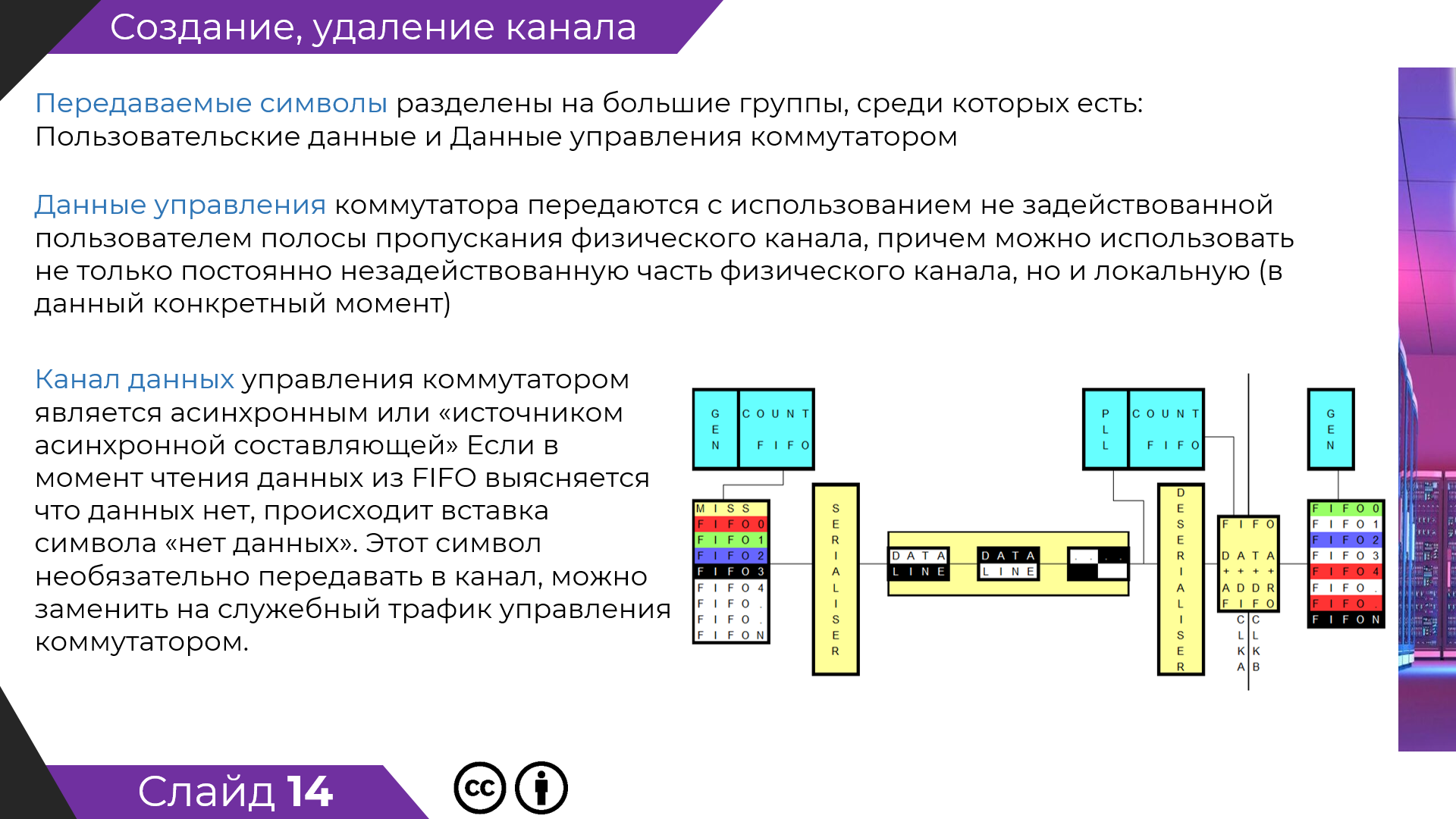
Тема виртуальных каналов с побитной коммутацией - очень привлекательна и наверняка приходила в голову многим людям, кроме меня и Вас. Но. похоже, дьявол в деталях.
Я показал алгоритм - укажите в каком случае он не будет работать.
Если Вы это сделаете, то Вы поможете мне на порядок больше чем все остальные.
Структура каналов не статична. Ее нужно менять: канал с такой-то пропускной способностью открылся, потом закрылся. А еще есть проблема работы в иерархической сети, когда из пункта А в пункт Б тянется множество каналов.
Покажите текст работ или опишите проблему на которой Вы "сломались", я скажу где вы ошиблись.
ps На меня не действуют психологические приемы с уменьшительно ласкательными обращениями )))
"Работа телефонистки" - коммутация каналов.
Телефонистка может создать канал с различной производительностью для каждого клиента (ровно столько сколько хочет клиент) ?
Понятно дело все это она должна делать не занимая монопольно физический канал под конкретного клиента.
"Телефонистка" - метафора. Я сказал, что не смог придумать подходящего алгоритма динамической коммутации каналов, тем более, с различной пропускной способностью. Без решения этой проблемы Ваш "алгоритм" гроша ломаного не стоит.
Был придуман весь комплект алгоритмов, для всех этапов работы сеансов связи.
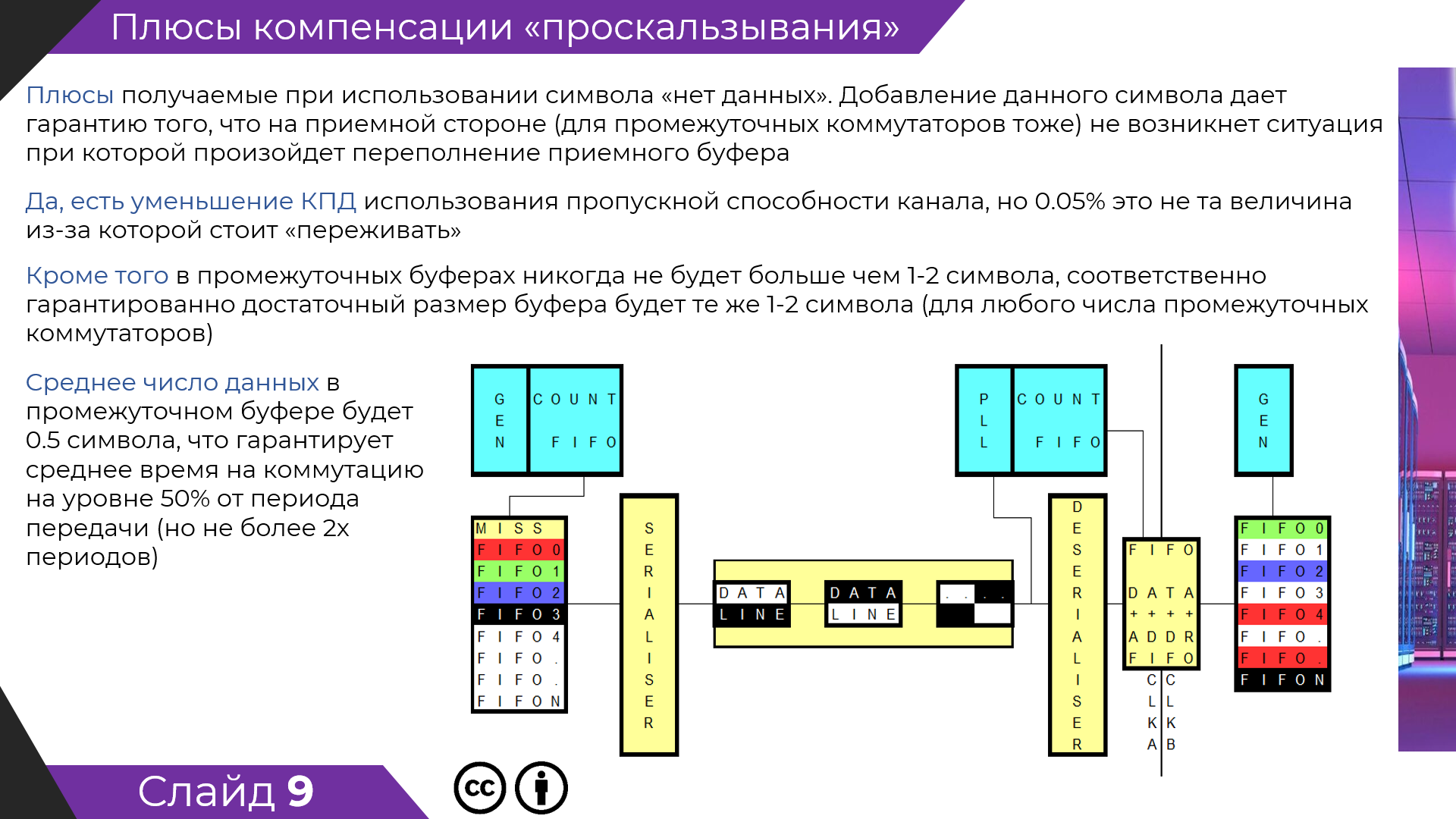
Если внимательно читать презентацию, то есть даже упоминание к не чувствительности
алгоритма к потерям в физическом канале связи, даже на на этапе создания виртуального канала.
Все физические сбои в канале связи влияют только на вновь создаваемый канал (даже жесткая рассинхронизация только временно разорвет связь).
Пользователь узнает о проблемах в канале связи (и попытается перестроить его ) за время не более чем время передачи данных до приемника и обратно.
Способы минимизации задержек вполне себе существуют. RDMA у Infiniband и RoCE в Converged Ethernet. И если RDMA проприетарный формат Mellanox, то RoCE вполне себе IETF и он открытый. Но задержки у обоих могут доходить до наносекунд, в вычислениях с высокой нагрузкой это имеет смысл. а в RoCE он ещё и хорошо переваривает изменение объема передаваемых данных. Этим технологиям уже лет 10 как исполнилось, а то и больше.
Стандартный размер MTU - 1500 байт, если туда не лазить, оно таким и остаётся. Его делают больше для передачи данных (Jumbo frame), оно переключается на больший размер при подключении некоторых протоколов, но причём здесь VoIP? Для приоритезации голосового трафика над данными используются, тэгирование (раскрашивание) трафика, очереди и QoS.
Сами по себе задержки не являются критически важными (в разумных пределах).
Важно то что пакетная коммутация по своей природе является асинхронной,
а значит не существует конечного размера буфера памяти при котором не будет потерь передаваемых данных.
Неизвестный размер буфера = неизвестная неконтролируемая задержка.
Кроме того, потери данных порождают увеличение трафика (повторная передача), а значит падает КПД линии связи (в какой то момент может и вообще до нуля).
Как в своё время было сделано в RDMA у Infiniband. Передатчик запрашивает сколько памяти ему может предоставить приемник и начинает слать туда данные, на обработку которых приемник не отвлекается, т.к. памяти в современных системах очень много. Латентность минимальная, непроизводительные издержки протокола (overhead) - аналогично. Очень долгое время это был массовый высокоскоростной интерфейс. в Infiniband Trade Association входили все монстры - Cisco,HP,IBM, Juniper. Кстати у HP, четырнадцать лет назад, самый дешёвый способ соединить два коммутатора по 10Гбит - это были 2 модуля Infiniband CX4 и кабель CX4. SFP+ модули и DAC (кабель прямого подсоединения) или AOC (активный оптический кабель) стоили дороже в 2-3 раза.
Но недостатки есть продолжение достоинств - объем передачи в Infiniband идёт кратно 4К байт словам. Протокол не очень быстро разворачивается в обратную сторону. И он проприетарный, за каждый порт и разъем надо платить небольшую мзду Mellanox. Поэтому в Ethernet был доработан RoCE (RDMA over Converged Ethernet), который делает всё то же самое, но работает на переменных данных и обратная передача данных в нём не представляет проблемы, потому что она ведётся по многим линиям приемопередачи (lane) и RoCE опубликован как открытый стандарт IETF.
Ситуация с использованием Infiniband резко ухудшилась, вплоть до того что Mellanox d 2021 году купила Nvidia. Вот там ему самое место - передача данных между узлами серверов HPC (high performance computing - высокопроизводительные вычисления).
Даже IBM опубликовала у себя грозную ноту, о том, что Infiniband в высоконагруженных СХД не имеет преимуществ перед Converged Ethernet, и с 2023 года убирает его поддержку почти во всех продуктах.
Нет, и очень давно. С уходом в прошлое стандарта 10Base2 (Ethernet по коаксиалу). Когда у нас на сегменте в 300 метров, могло сидеть до 100 станций, и каждая станция перед своей передачей слушала линию, и передавала пакет, только если линия была не занята, при обнаружении несущей, откатывалась на некоторое случайное время и начинала попытку передачи снова. Вот это - чистая асинхронная передача. Как yнахождение массы радистов на одной частоте. Передаёт один - слушают все, не своя передача игнорируется. полоса пропускания у такой сети - 60% не более, большая часть времени занята на организацию доступа к каналу. способ называется CSMA/CD
В тоже время жил был проприетарный стандарт Token Ring компании IBM, в котором право на передачу имела станция, у которой был маркер передачи, под названием токен. Станции должны были быть замкнуты в кольцо, делалось это достаточно сложными устройствами под названием balun. Отдельные издержки протокола - потеря маркера и голосование за нового владельца. Но полоса пропускания у такой сети была порядка 80%, и TR работал на 16 Мегабитах. Его потом даже перевели на витую пару (кстати, стандарт CAT4 - это для него), но это ему не помогло, его убил 10BaseT - Ethernet по витой паре.
В течение какого-то времени использовались тупые хабы по витой паре, которые реализовывали принцип коаксиала, что орут в одном порту транслируется во все остальные, называли их концентраторами.
Очень быстро им на смену пришли коммутаторы, сначала тупые, которые умели транслировать нужные пакеты только в нужные порты, а потом и умные, с поддержкой протоколов и конфигурированием. Полоса пропускания на таких устройствах стала порядка 90-95%. Дальнейшее зависело от скорости работы ASIC, дешёвые ASIC - дешёвые коммутаторы и производительность и функционал у них не очень.
Но, что самое важное. в 10BaseT, потом в 100BaseT и в 1000BaseT и выше появилось понятие lane - это одна TX/RX линия, состоящая из парафазного сигнала TX+/TX- и RX+/RX- служащего для уменьшения помех и перекрёстного паразитного сигнала (crosstalks).
таких линий в 1G eth - 4, в 10 и 100 - 2.
И эти линии синхронные - потому что позволяют выполнять прием и передачу вне зависимости друг от друга.
С высокоскоростными ethernets всё ещё интересней. Хотя принцип тот же самый. Есть лейны (lanes), которые объединяются в группы на сердесах (SerDes - serializer/deserializer). это микросхемы, которые отвечают за сбор/разбор из битов в байты и наоборот (у вас это называется TDM, по смыслу да, но не тоже самое). И делают они это очень быстро. Современная скорость коммутации 900+Mps/сек. 900 миллионов стандартных 54 байт пакетов. 54 - не с неба упало, это стандартный размер пакета в FiberChannel. Синхронизацией счётчиков никто не парится. Есть чипы PLL с каждой стороны (Phase Locked Loop), они как раз по изменениям фазы сигнала (а у нас сигналы в обе стороны парафазные) занимаются компенсацией фаз и заодно исправлением убегания временных характеристик сигнала. Тут всё очень хорошо отработано, даже счётчики не нужны.
Пока что вы двигаетесь по той же дороге, которую уже 20 лет назад прошёл Broadcom и, наверное, с десяток других вендоров. И это не научные работы, это куски из инженерной документации от серийно выпускаемых изделий.
Причём у Broadcom очень много выложено в открытый доступ.
Прочитайте мое мнение того как должна выглядеть DSM ( https://aftershock.news/?q=node/1108293 ), обращение в память соседних процессоров (находятся на расстоянии в 3 метра) не должно отличаться от по времени от обращения в собственную при размере передаваемых данных равном строке кеш памяти.
Задержки работы DSM не должны зависеть от числа разделяющих общую память процессоров.
InfiniBand пакетная система, а значит задержка коммутации принципиально не может быть меньше времени передачи заголовка пакета и при прохождении каждого коммутатора она увеличивается на эту величину. Если не ошибаюсь, то сейчас задержка порт-порт в районе 70 нс, если приплюсовать к этому размер кабеля (туда сюда) и работу адаптера, то получим время обслуживания запроса около 1мкс. В настоящее время 1 мкс это ВЕЧНОСТЬ.
Я имел ввиду не доступ к среде, а общую несогласованность клиентов в сети.
Например ничто не запретит многим пользователям в сети так совпасть трафиком и маршрутом передачи, что это локально перегрузит только один линк, отдельного коммутатора. При этом остальная сеть останется сравнительно свободной. Про приемный порт пользователя я уже и не говорю.
В моем понимании синхронные это что типа OTN.
Для компенсации разности частот тактовых генераторов в пакетных системах служит преамбула, а PLL это просто восстановление частоты синхронизации для обеспечения декодирования.
Скажите, Вы сможете построить коммутатор с портами на скорость 100Т (например 8 портов) имея частоту тактирования ядра коммутатора в 1ГГц ?
Нет там таких задержек.
Полностью линки загружаются сплошь и рядом. Если это влияет на работу всей сети - сеть криво спроектирована или используется негодное оборудование. Кто ставит 48x1G с аплинками 4x1Gb - тот сам себе враг. Ставите 48x1Gb - аплинки должны быть 4x10Gb - такой коммутатор, в реальной жизни, вы не загрузите никогда.
В настоящее время в стадии утверждения находится 800G, и есть производители уже делающие такое оборудование, ведется работа над 1.6Т, откуда 100Т? Что это за ненаучная фантастика?
Практически топовый Broadcom Tomahawk3 BCM56980, на котором собирается коммутатор 32x400Gb или 64x200Gb, 128x100Gb, общая коммутирующая способность 12,8Тб/сек
К вашему сведению, тактовая частота ядра у него - 50МГц и её хватает, всё остальное делается умножителями. У PLL тактовая 20МГц, причем, сам осциллятор на 12,8МГц, у сердеса - 156МГц.
Самая высокая частота, там где и должна быть - непосредственно в линии:
И ещё один приём использован - кодирование PAM4, там кодируются группы по два бита 00,10,01,11, позволяет увеличить плотность сигнала, без увеличения частоты.
Это всё широкораспространённые решение в схемотехнике, чтобы не мучиться с ВЧ эффектами и не усложнять плату. Никто не рассуждает: "Раз у нас скорость передачи 1Гбит, то и тактирование везде должно быть 1ГГц". Это ошибка.
И вообще, очень рекомендую к прочтению BCM56980 Hardware Design Guidelines. Низменную матчасть надо знать, прежде чем аппелировать к высоким материям.
Ошибаетесь : https://tiscom.ru/controller/mellanox-is5300 -
Поставил такой коммутатор, в какой то момент 47 линий захотели отправить пакет в один аплинк под номером 48 - что будет ?
Остается надеяться что буфера хватит, но это работает только для медленных сетей.
Если скорости равны 100Т на порт, то даже один не сбалансированный порт перегрузит любой буфер за 1 мкс.
Еще - помним, что время коммутации 100 до 300 нм, а это автоматически требует все это время сохранять данные коммутируемого пакета. Те минимальный размер буфера (для 48 портового коммутатора на 100Т) будет 480- 1500 Мбит, а это уже превышает размеры быстрой памяти даже для самых современных чипов, вытащить во внешнюю память такой поток невозможно.
Это требования перспективных компьютеров, ссылки на исследования:
https://3dnews.ru/assets/external/downloads/2020/12/04/1026993/demophot.mp4
https://ayarlabs.com/supernova/ (https://ayarlabs.com/supernova/
А 10Т (1Террабайт в секунду) это реальность сегодняшнего дня для вполне рядовых процессоров компании IBM (интерфейс памяти).
Можно сказать, что скоро 800G будет интерфейсом типа USB - для подключения флешек.
Знаю как все там устроено
и про максимум физической скорости на 1 LAN в 112G (для меди) тоже знаю.
Частоты функционирования ядра коммутатора 1-5ГГц (если есть доступ к документации - прочитайте).
Ничего не будет. Вообще-то в дата-плейне есть очереди и в контрол-плейне - трафик менеджер. Он не даёт терять данные.
Вот когда они будут доступны в виде серийных образцов, тогда можно будет разговаривать, а в лабах много чего делается.
Ссылку на даташит предоставите?
Ещё долго не будет. Спецификация USB 4.0, по которой пока ни одного устройства не сделано - 10Гбит.
Нет, не знаете. Знали бы - не писали бы того, что выше. И не соскакивайте с внешних частот устройств на внутренние. Разница между ними принципиальна.
Это вы намекаете на на алгоритмы "обратного давления" и постепенное возрастание скорости в протоколе TCP\IP.
Не поможет - при скоростях 100Т 1 метр кабеля будет иметь информационную емкость более 600кБит.
Буфера банально не хватит даже для того что бы сообщить о перегрузке портов следующего коммутатора.
В мышлении Вы ограничены уровнем "инженер" : "Если нет микросхем, значит технологии не существует".
Статья посвящена перспективам развития для горизонтов 5-10 и подход основанный на сроках поставки со склада здесь не применим.
И это проблема, в нашей стране нет ученых (области телекоммуникаций и вычислительная техника), только инженеры (да инженеры хорошие - никто не спорит).
Если говорить про "философов" способных прорабатывать пути развития на десятки лет вперед, то и вообще нет.
Ну кроме меня конечно )))
Извините, но IBM их не раздает.
Можете поискать IBM OMI (Open memory interface)
Я вас не понимаю.
Внешние частоты это по факту это спектр полезного сигнала, для электрических линий спектр самого сигнала в кабеле.
Для оптики это спектр модулирующего сигнала (для самого простого случая).
Не забывайте внешний сигнал может иметь очень много составляющих и одна физическая линия может состоять из большого числа практически самостоятельных каналов.
На с в данном случае не интересует что там и как - считаем что в сторону физики (один канал) уходит некоторый цифровой поток (считаем что он равен 100 триллионов бит в секунду).
Частота тактирования ядра коммутатора (цифровой его части) ограничивается быстродействием кремниевых транзисторов (типично 20ГГц).
Частота 1-5ГГЦ некий компромисс: Еще быстро, но еще не запредельное потребление.
Смысла делать ядро на меньших частотах нет никакого. Да можно, но за это придется платить увеличением числа транзисторов, увеличения площади и соответственно цены.
Если вы не согласны и имеете возражения, то прощу предоставить ссылку на PDF с указанием частоты ядра например в 125МГц.
Мощное заявление. Вы в IETF напишите, а то они, дураки, не знают.
А что так мало? Надо 100500 триллионов бит/сек.
Носитель под такую среду есть? Система кодирования есть? Кодек под неё есть? BER у него на каком уровне?
Или как в том анекдоте: Печатаю очень быстро, только такая фигня получается. Передаём очень быстро, только пока ничего принять не можем.
Вы похожи на ВладиславЛ только от сетевых технологий. Есть у нас тут такой персонаж, у него всё про дроны. Вы очень много где путаете мягкое с цветным, но вас это совершенно не смущает.
Я вам отправлял ссылку ( https://ayarlabs.com/supernova/ )
Микросхему FPGA с похожим оптическим интерфейсом до санкция можно было купить.
Не нужно "ерничать".
Скорость 100Т обуславливается максимальным числом вычислительных ядер (примерно 15000), которые возможно разместить на кристалле (читайте про GPU).
Есть соотношение между вычислительной производительностью (для универсального процессора) и требуемой скоростью передачи данных (примерно 1 данное на 5 исполняемых команд). GPU это скорее векторный вычислитель, а для таких соотношение примерно 1 к 1000.
Для
Я совершенно не ёрничаю, но вижу, что у вас есть определённые пробелы в этой части знаний. Я как специально, не стал отвечать по ней, и получилось, что заставил вас увязнуть немного поглубже. Избегайте в дискуссиях этого.
Вот эти ребята ( https://ayarlabs.com/supernova/ ) взяли старый добрый принцип CWDM - оптическое уплотнение с шагом 20 нм. и сделали пассивный уплотнитель в формате PHY уровня и обозвали его TeraPHY. С точки зрения инженерной задачи - молодцы. Никаких новых научных принципов их конструкция не имеет.
У них же выложен бриф:
Technical Brief: Optical I/O Chiplets Eliminate Bottlenecks to Unleash Innovation
Который, я надеюсь, вы изучали. Потому что там написано, 8Тб получаются из четырёх сборок по 2Тб. 8 лямбд на волокно. На каждую сборку заводится 3 одномодовых волокна, одно на прием, одно на передачу, и ещё одно на оптическую накачку. для CWDM, где используются диоды с пассивным охлаждением и дальность связи не превышает 160км - это нормально. 8 лямбд - это они ещё поскромничали. в CWDM в одно волокно помещается до 18 лямбд, и их TeraPHY работает до 2,1км, по их брифу. Проблема в энергопотреблении их ебалды и последующем теплоотводе. Баланс, всё для него. А вся их конструкция размером с CFP модуль - она для 1U коммутатора очень большая. Коммутатор с такими модулями - минимум 2-3U. Это много. Датацентры хотят оборудования в формфакторе 1U. Это наиболее экономно.
Куда расти - тоже есть, потому что есть ещё DWDM - там волны отстоят друг от друга на минимальном расстоянии 0,4нм, в одно волокно помещается 180 лямбд. Но у него все диоды узкополосные, требуют качественного активного охлаждения и эта конструкция жрёт как не в себя. поэтому DWDM оборудование миниатюризировать сложно.
Ну и возникает вопрос. Хорошо, приемопередатчик есть, а чем обрабатывать? Broadcom пока может предложить Trident IV, который в одно ядро переваривает 25Tbs. По предварительным сведениям в разработке есть чип на 50Tbps, который пока никто не видел. У всех прочих, Mellanox, с его Spectrum, Cisco с его Doppler, Invinium с его процессорами - у них производительность ниже.
На одно ядро можно повешать 3 таких TeraPHY (8x3 = 24), при том, что продуктивных волокон будет 6, ещё три волокна для сигнализации не используются, они нужны для питания схемы. Trident 4 в принципе объединяется с себе подобными, как и вся StrataNGX, так что при необходимости их можно объединять в пределах одного устройства. Но это будет ОЧЕНЬ дорогое конечное устройство. Потребители его не потянут.
Для датацентровых интерконнектов - терпимо, возможно, это где-то найдёт применение, но и тут пока такого запроса нет. 400Gb - норм, 800Gb на подходе, в разработке 1600Gb, который опять же будет работать по дешёвой меди.
Для магистральных соединений у TeraPHY и вовсе нет преимуществ - 8 лямбд на волокно у TeraPHY против 180 на волокно у DWDM, а то что уплотнитель DWDM на ладошке не умещается - да и пофиг. И дальность. У TeraPHY - это 2.1км, всего лишь, хотя много лет существуют DWDM каналы, работающие на тысячи километров без ретрансляции.
Волны обычно нумеруются по цветам, стандартный разговор сетевиков: "зашёл на фиолетовой, вышел на жёлтой".
То, что эти ребята сумели сделать такой девайс - молодцы. Это инженерная задача, новых физических принципов здесь нет. Как повод продаться кому-нибудь - вполне годная стратегия. Даже Intel, который когда-то слился с рынка коммутаторов теперь решил туда вернуться, прикупив компанию Buffalo у которой есть интересные устройства.
P.S. Маленький нюанс. У IETF есть "Конкурирующая фирма" (С) О.Бендер. это комитет INCITS T11. Эти ребята много лет разрабатывают FiberChannel, основа для построения производительных СХД. Он вообще не совместим с Ethernet, и сам по себе. Ну, IETF придумала FCoE, чтобы его пропускать через Ethernet в качестве полезной нагрузки, а в ответ, IETF придумала iSCSI, чтобы не марать руки об FC в принципе. Так вот. Емнип, FC где-то пару лет назад представила с помпой приемопередатчики на 64Gb, сейчас доступны на 128Gbps в разработке 256Gbps. "И вот эти люди запрещают нам ковыряться в носу" (С). Ethernet очень сильно убежал вперёд.
У FC чудовищные стоимости. один SFP FC модуль на 32Gbps производства Brocade стоит, емнип 32K USD, а вам их надо 2 и ещё коммутатор FC фабрики. Сплошные бида-пичаль-разорение-санкции. А вот с СХД на iscsi всё будет попроще и даже поинтереснее.
P.S. Я вам очень настоятельно рекомендую изучить документацию Broadcom по нескольким причинам:
1. Вы узнаете как обстоит дело у "ведущих собаководов". А Broadcom - один из них.
2. Знания никогда и никому не вредили. А это очень крутые книжки про то по каким принципам строится их скоростное железо.
3. Эти доки могут убрать из открытого доступа в любой момент. Просто "потому что".
4.В доках важны принципы, они почти не меняются. Растут частоты, пропускная способность, количество каналов передачи, но не базовое устройство.
5. Терминология. Вы будете говорить на одном языке со всеми потенциальными интересантами ваших идей и разработок. Я сам лично в вашем докладе споткнулся о "TDM и слоты". Доклад про связь? Нет. А причём тут TDM? Который сейчас даже в связи используется только у операторов сдающих СОРМ2 трафик в компетентные органы, те его по прежнему хотят видеть только в TDM E1/T1, правоверный SIP им по прежнему чужд.
Терминология - очень и очень важная штука. И идеи которые там приложены, принципы. Вы вашу проблематику, возможно увидите по другому. Современный коммутатор - по моему скромному мнению, - это плоская база c индексированными таблицами.
Также рекомендую libgen, там есть масса статей из рецензируемых журналов IEEE по передаче данных. Это передний край науки, мнения, субъективные оценки, срачи. Всё как мы любим.
Но меня и не интересует что они и как сделали, главное они создали чиплет с требуемой производительностью.
Вторую ссылку с интелом посмотрели ? Там другой вариант решения проблемы, и он меня не интересует - мне важен результат.
Еще раз повторяю - мне совершенно не интересует как устроена "физика".
Мне важно что идут работы по получению битовой пропускной способности уровня 100Т в размере чиплета (есть возможность интеграции в процессор).
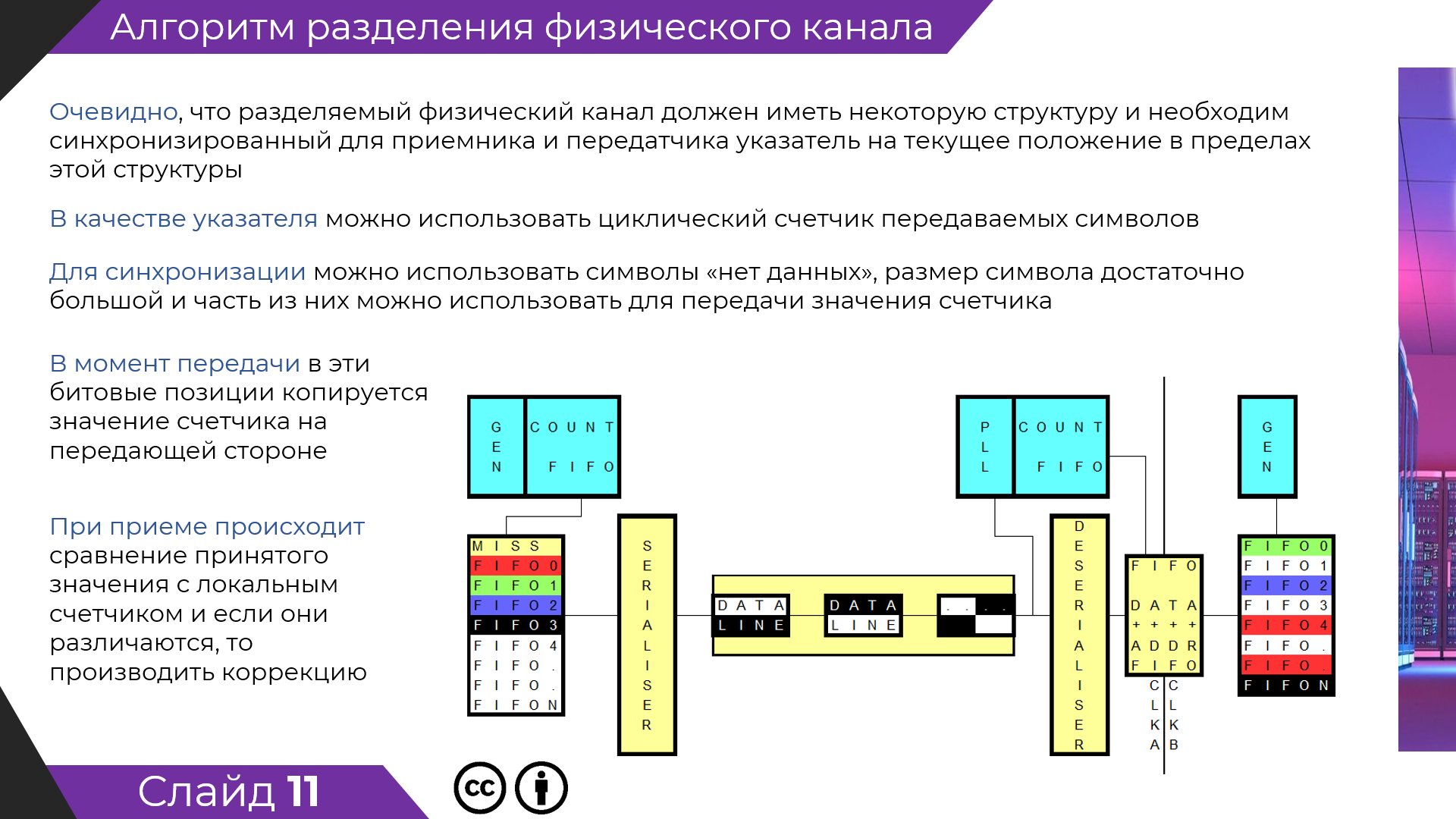
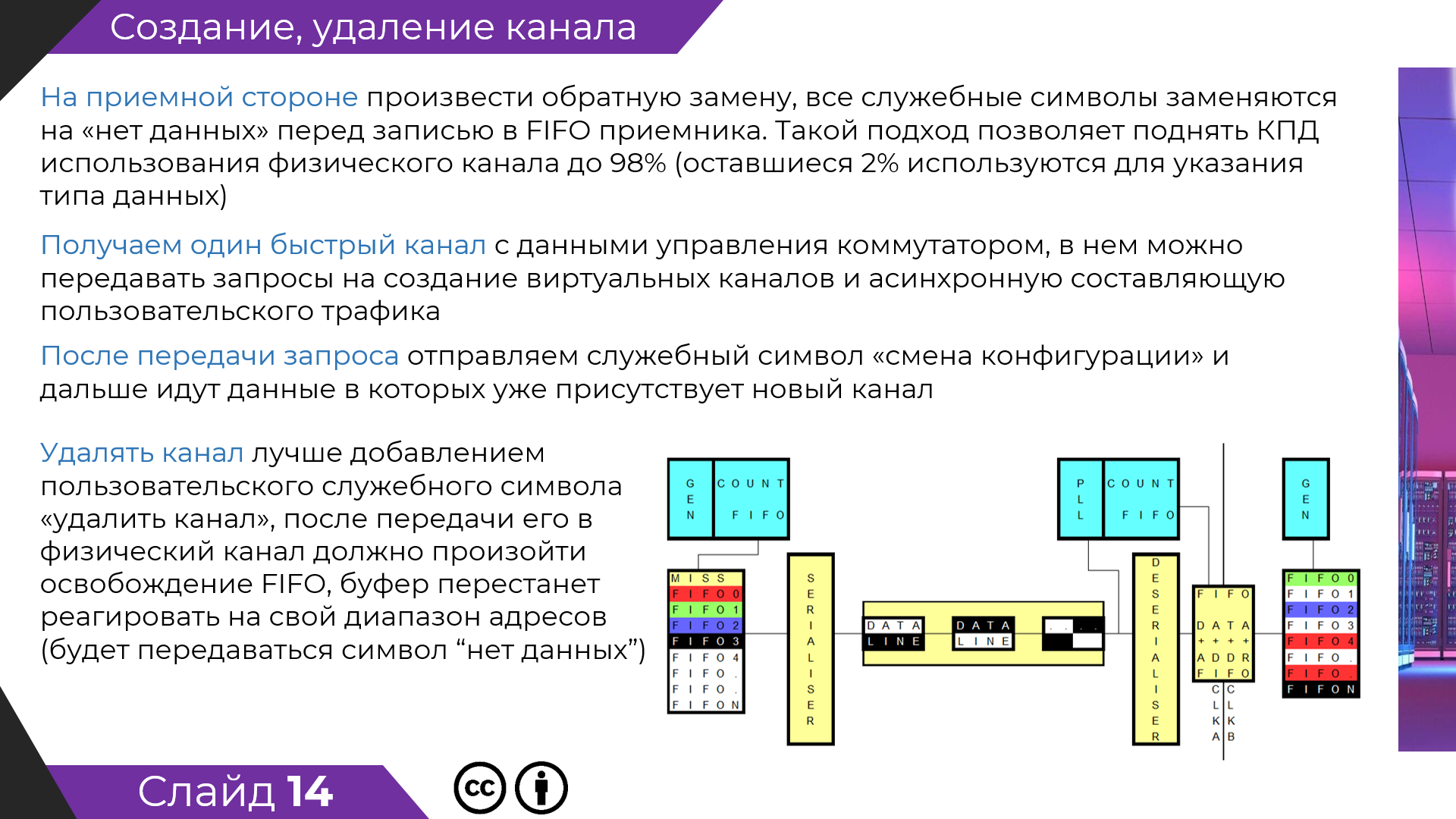
Сейчас есть два варианта разделения физического канала (для коллективного использования).
Первый вариант Статичное временное разделение (TDM), в этой технологии есть понятие тайм-слот. Современные производители телекоммуникационных систем считают ее мертвой, хотя в технологии SDH данный принцип используется для получения следующих уровней иерархии (STM-1 STM-4 STM-64).
TDM основа синхронного разделяемого цифрового канала связи, если в той или иной вариации не используется в какой либо технологии связи, то этот вид связи не может быть синхронным.
Есть второй тип разделения канала между пользователями - пакетная коммутация. Системы построенные на данном принципе принципиально асинхронные.
Я разработал третий принцип, позволяющий одновременно создавать каналы передачи данных с различной синхронной скоростью (гарантированной скоростью передачи) и одновременно имеющими точно заданную асинхронную составляющую скорости передачи.
И как "вишенка на торте": Практическое отсутствие ограничений на максимальную скорость физического канала для современных техпроцессов изготовления микросхем.
Скорости виртуального канала задается не просто как V, а как строго гарантированная скорость в диапазоне от V1 до V2 (ни битом больше ни битом меньше).
Вот скажите, какие другие сети могут такое же, понятно дело без "вырывания гланд через жо.." ?
Ответьте, без увиливания : Вы смогли понять как происходит разделение одного физического канала на несколько логических (виртуальных).
Зря, что вас это не интересует. Это рождает ограничения в масштабируемости, потому что за этим стоит физика. Которую невозможно подчинить идее. Физика всегда и везде одинакова.
100T чиплет тут мимо проходил. Его в принципе нельзя пощупать. Процессоров таких тоже нет. У BMC их нет, даже в проекте, а Интел ещё только въехал на эту скользкую дорожку, и декларировать он может что угодно. Ни предсерийных, ни, тем более, серийных образцов никто не видел. Если что не так - ссылки на статьи в IEEE журналах приветствуются.
Есть хренова туча оборудования на магистральных каналах, которые никто ещё долго не будет разбирать, потому что оно стоит и работает. Когда-нибудь помрёт.
Lanes, for God of lanes!
Да я вам даже картинку приведу. Гидра-кабель 100G QSFP28 to 4 x 25G SFP28. Dell в своей документации называет его "пассивный осьминог" passive octopus - живите теперь с этой информацией. Каждый из портов на гидре является отдельно адресуемым при необходимости. А гидр существует масса. Вся причина в тактовых частотах линий по передаче данных: 4x10 = 40. 4x100 = 400. 4x200=800 и т.д. Там есть ещё много комбинаций.
Ничего тут нового лет 10 последних не придумано.
Вы ничего понять не смогли - печально, но "селяви".
Да это следствие отсутствия науки о телекоммуникациях, в нашей стране она существует только как инженерная дисциплина.
Ученых нет, а инженерам из-за пониженного уровня образования недоступны философские концепции.
Ладно, ждите. Думаю достаточно скоро создадут микросхемы Синхронной Символьной Коммутации.
В начале Вы будете применять их просто в слепую - припаял, работает и хорошо (как черный ящик).
Потом ВУЗы выпустят студентов с новыми знаниями и вот они может быть смогут объяснить "ветеранам" как это все работает.
Вы вроде бы не до конца идиот, и я стараюсь достучаться, потому что у вас какие-то нестандартные идеи есть. Но, видимо, это напрасно.
Я вам, лично, как для школьника рассказал, практический курс по коммутаторостроению, с показаниями к применениям на основе общедоступных теорий и практик, но вы же дико не хотите стоять на плечах гигантов, вы хотите всё постигать всё с самых низов.
Постигайте! Изобретайте свои болгеносы, фильтры Петрика и прочую муть.
В ваших идеях нет ничего принципиально нового. Вы не понимаете общих принципов, вы не хотите знать ничего хотя бы в пределах университетского курса. Хотя бы в пределах инженерной информации от вендоров, которые они публикуют, хотя они делать этого не должны.
Ваш уровень недотягивает для дискуссии даже с моим - я просто практик, который проектирует сетевую инфраструктуру в датацентрах, и имеет соответствующее университетское образование.
Очередной, никем не признаный гений, Ой-вей. Микросхемы не забудьте принести, на основе этой самой синхронной символьной коммутации. О, нет. Это же XON/XOFF в RS-232 (OMG!).
Короче.
Учитесь, учитесь и ещё раз учитесь. Интернет открыт для всех.
А ответить за свои слова слабо ?
Укажите технологию которая построена на озвученных в презентации принципах и позволяет (хотя бы) разделить один физический канал на произвольное число независимых виртуальных каналов с произвольной и различной скоростью (соблюдая правило что сумма скоростей виртуальных каналов меньше чем скорость физического канала) ?
Понятное дело, что это должно быть не статическое разделение, а динамическое и не требовать заранее договариваться об этом с приемником.
Если не найдете, то если вы и работаете в дата-центре то на должности охранника парковки.
Слишком часто стал по жизни встречаться с непризнанными гениями. .. прям беда какая то.
Недавно выставка прошла "Связь 2024", я поговорил с большим числом специалистов в области связи.
Не диванных экспертов, а действительно работающих инженеров.
По результатам переговоров, получил несколько приглашений прочитать лекции.
Вот Вам почитать (нужно учиться на ошибках человечества):
https://habr.com/ru/companies/ruvds/articles/322138/
Мне все равно где будет использоваться мое изобретение.
Если так нужно, то пусть это будет "Скайнет" предназначенный для уничтожения человечества.
Мы продукт эволюции: выживает сильнейший, печально если это будет не человек, но "селяви"
В целом процесс пошел, общение с аудиторией в инете (Афтершок в частности) бесполезно - они банально не хотят думать.
По поводу обид и прочее: Меня не волнуют издевки будущих "мертвецов".
Сейчас благодатное время: СВО показало бесполезность человека на поле боя, скоро большие компании меня найдут (можно сказать уже нашли) и начнется следующая мировая война.
Если серьезно, то вот так:
Письмо и распечатка получены. Могу уверенно ответить, что в открытом доступе о научных школах указанного направления информации нет. Можно попробовать обратиться в компанию Т8, где работают известные специалисты по современным телекоммуникациям из МГУ, МГТУ им. Баумана, ФизТеха. Они ближе всего к разработкам такого типа и их практическому внедрению. Работу по этой тематике рекомендую продолжить. При наличии патентов и публикаций в научных изданиях из списка ВАК и Scopus может потянуть на учёную степень.
Фокин В.Г.
https://sibsutis.ru/company/personal/user/8185/
Научные интересы:
Фокин В. Г., Ибрагимов Р. З. Оптические системы с терабитными и петабитными скоростями передачи : учеб. пособие для вузов. Москва : Горячая линия-Телеком, 2017. 180 с.
Поймите, то что я изобрел слишком ново (пусть и по оценке сайта антиплагиата) степень новизны более 90%.
Я рассказываю (пока) только о тривиальных вещах (простых как палка веревка).
Психически здоровый средний человек перестает понимать текст после 20-30% новизны.
Кстати, запредельное потребление - это по Вашему мнению сколько?
Более 500 Вт с отдельной микросхемы.
Если делать оптический интерфейс (выходы с торцов) , то можно реализовать интересный "союз" системы охлаждения и питания:
Сделать контакт с радиатором не с одной стороны как сейчас, а с двух.
Зажимать микросхему между двух радиаторов, а питание подавать межлу двумя сторонами микросхемы (радиатор сверху + питание, снизу земля).
Получим удвоенный теплоотвод и "жирнейший" контакт для подвода питающего напряжения.
Почему я всегда рекомендую читать родные доки. График потребления тока ядра BCM56980.
401 ампер в пике! Что по 3.3 вольта потребления означает ~1323Вт. Правда BCM ставит оградки по кругу: это при особых условиях, когда у нас всё проинициализировалось, и со всех портов трафик каааак ломанётся! Но всё равно это много. Линии питания такие броски обязаны вывозить.
Если вернуться к частоте тактирования ядра коммутатора (ну ладно все цифры на борту микросхемы) :
Разве можно получить такое потребление при тактовой частоте 152МГц ?
На всякий случай : Динамическое потребление кмоп пропорционально числу и скорости (тактовой частоте) переключения отдельных транзисторов.
Не важно, что внутри, главное, что у нас низкочастотная схема снаружи.
Уверуйте в схемотехнику, там нормальные для экономики решения жи есть.
Для линейного специалиста, достаточно понимания внешних свойств, понимания работы "черного ящика" ненужно.
А Вы об этом не знали заранее? Вы не в состоянии уложить качественный доклад в нужное время?
Анекдот про войну и мир знаете :
Двоечник ничего не учил к уроку литературы.
Понимает что его вызовут к доске, спрашивает у отличника :
Расскажи про что "Война и мир"
Отличник ответил: "Война" - "Мир"
Я уже и так сократил, до совсем уж неприличных размеров.
Пусть не прочитаю вслух, так хоть заинтересовавшиеся смогут потом прочитать.
Иначе вообще никакого смысла нет.
Большого слона едят по кусочкам. И других кормят кусочками (информации). Иначе - несварение.
Либо сумеете разбить на осмысленные небольшие (но содержательные) куски, либо никто с Вами дела иметь не будет. У каждого свои темы размышлений и никто не станет посвящать большУю часть своего времени разгадыванию головоломок странного человека, особенно, если начинают проскакивать идеи про "цифровое бессмертие" и "биологический компьютер".
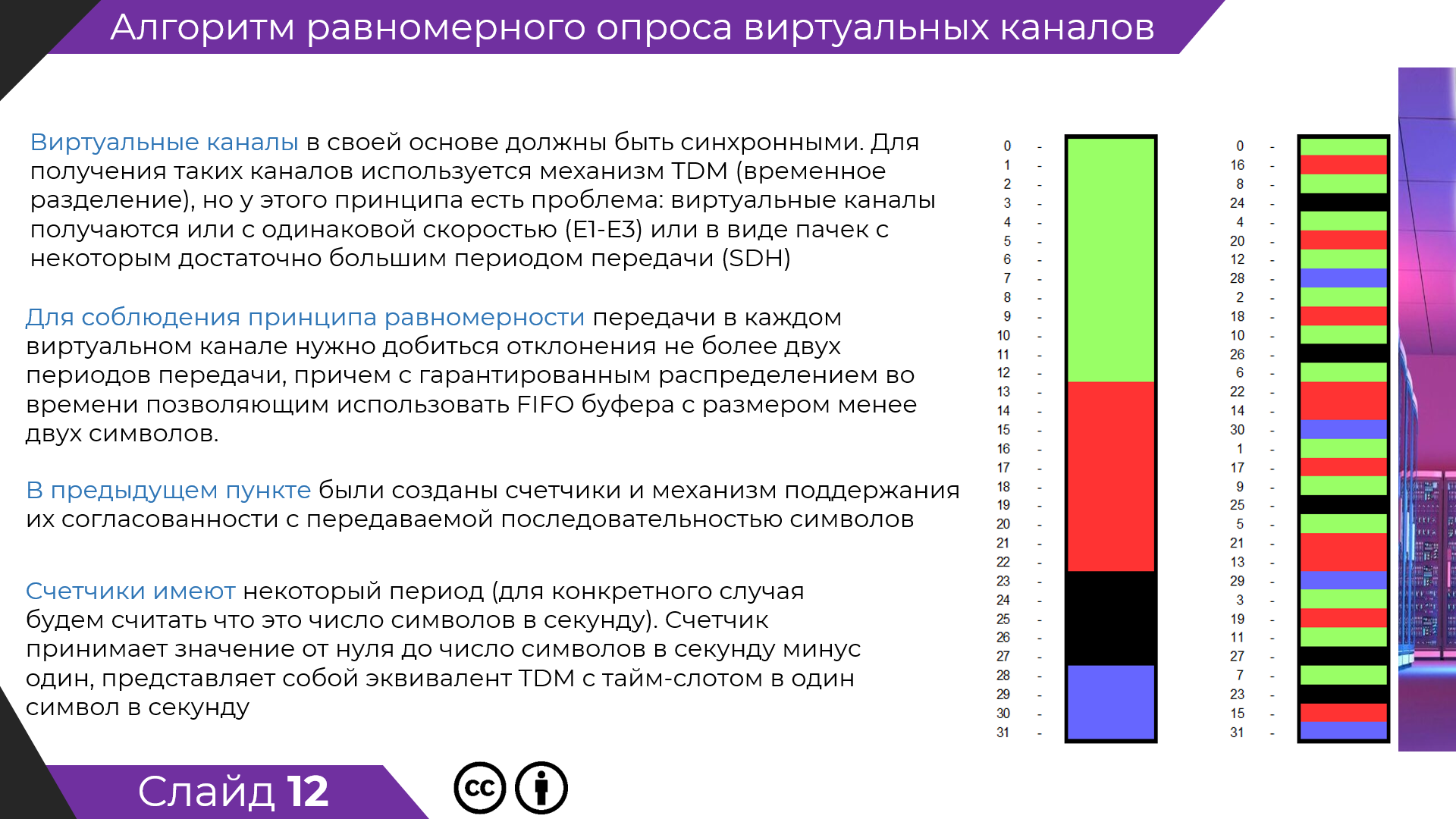
На картинке визуализирована проверка "руками" : нарисовал счетчик 5 разрядов (побитово), поделил на регионы принадлежащие различным виртуальным каналам.
Далее отрисовал (разными цветами) как будут передаваться данные.
Единственно нет оценки максимального отклонения от строго периодичной передачи.
Перспективный чат детектед! Сим повелеваю - внести запись в реестр самых обсуждаемых за последние 4 часа.
Шукшин гениален :)
Давно хотел спросить таких как вы, погружённых: а информация /данные что-нибудь весит? В физическом смысле?
С физической точки зрения да (мое мнение):
Данные это различные состояния некоторого носителя.
Даже если отбросить вес самого носителя, каждое состояние характеризуется некоторой энергией.
А энергия это масса.
Есть даже теоретические работы серьезных физиков по этому вопросу.
"Ского вешать в граммах?" (с)
И сколько конкретно весит один бит? Для примера, один электрон весит ~9,1093837⋅10−28 г.
Читал когда то, но данная информация не является необходимой и потому была вытеснена.
Если интересно, то читайте примерно эту "муть"
http://lnfm1.sai.msu.ru/SETI/koi/articles/gurevich_2011-05-27.pdf
для меня практического смысла не имеет, а то и вообще .......
Страницы