






Форумчанином atorn вот в этой заметке
https://aftershock.news/?q=node/1122005
поднята достаточно интересная проблематика создания инструмента анализа пользовательских комментариев и условного «рейтинга скандальности». На первый взгляд сама идея выглядит привлекательной для реализации, поэтому взял на себя труд формирования концепции этого рейтинга и краткого технического задания на соответствующие программные модули для ядра сайта.
Итак, вычисление рейтинга скандальности (далее - РС) предлагается использовать достаточно эффективный алгоритм анализа текста путем расчета встречаемости N-граммных комбинаций и в частности выбрать для реализации пятиграммы. Предложение о пятиграммах, т.е. отрезках текста из пяти символов, чисто практическое, так как автор этого описания долгое время занимался машинным анализом текстов на естественных языках.
Концепция.
1. Каждый пользовательский комментарий по срабатыванию триггера базы данных о его создании обрабатывается либо движком самой СУБД (если он есть), либо отдельным программным модулем. В результате первичных вычислений для каждого пользовательского комментария формируется 5-мерная матрица с количеством повторений той или другой комбинации из 5 символов текста (включая пробелы и знаки препинания).
2. На втором этапе для 5-мерной матрицы каждого отдельно взятого комментария рассчитываются коэффициенты корреляции с аналогичными матрицами, которые сформированы аналогично первому шагу, но не по данному комментарию, а по одной или нескольким обучающим выборкам (которые могут быть либо однократно созданы при разработке самого модуля обработки, либо автоматизировано или вручную пополняться в процессе его работы). В базу данных пользовательских комментариев записываются коэффициенты корреляции с каждой из настроенных обучающих выборок.
3. Обучающие выборки на самом первом этапе – это просто наиболее характерные пользовательские сообщения, можно выбрать комментарии наиболее одиозных персонажей или наоборот наиболее уважаемых пользователей. Механизм анализа таков, что весьма эффективно учитываются малейшие особенности эмоциональной нагрузки текста – заглавные символы, эмоциональные окончания слов, характерные «истерические» слова и словоформы. Мой многолетний опыт работы показывает, что при обучающих выборках всего от нескольких сотен слов коэффициенты корреляции по разным выборкам становятся очень репрезентативны и по результатам такой обработки можно в полностью автоматическом режиме принимать значительное количество решений.
4. Цель такой обработки заключается в создании для администрации сайта простого и крайне эффективного механизма работы с пользовательскими комментариями и базой самих пользователей.
a. Автоматическое выделение «истерических» и «деловых» комментариев банально по стилистике изложения материала.
b. Подсветка либо цветом, либо размером текста, комментариев с различными классами. Так, в частности, по выбору пользователя истерические комментарии можно либо сильно уменьшить в размере, либо скрыть совсем.
c. Автоматическое выделение пользователей, практикующих эмоциональную накрутку своих комментариев или излишне эмоциональную реакцию на комментарии других пользователей.
d. Формируемая в таком автоматическом режиме система рейтингов отлично отражает как общий тезаурус каждого форумчанина, так и в целом позволяет формировать рейтинги психологической/психической уравновешенности пользователей.
e. В зависимости от получаемых значений этого рейтинга как сами нерепрезентативные комментарии могут автоматически скрываться от индексирующих роботов поисковых машин, так и сами пользователи могут получать как ограничения, так и бонусы при работе с сайтом. В частности, условным истеричкам могут быть ограничены количество ежедневных комментариев, так и доступ в определенные разделы сайта.
f. Подавляющая часть материала, необходимого для работы системы рейтингов на сайте уже накоплена, сейчас достаточно сделать модуль обработки сообщений и продумать варианты использования получаемых рейтингов. Сама метрика по текстам, даже коротким, около 100 символов, достаточно репрезентативна и позволяет в полностью автоматическом режиме вычислять значительное количество показателей после формирования необходимых обучающих выборок.
g. Не только администрация, но и каждый из пользователей сайта получает удобные инструменты управления при прочтении пользовательских комментариев. Это радикальным образом изменяет удобство работы с сайтом и принципиально экономит время наших «деловых» участников при выборе сообщений для ответов.
С точки зрения окупаемости затрат у подобной реализации есть три осноных аспекта:
1. Сам модуль статистической обработки изначально целесообразно делать возможно более гибким с точки зрения входных данных и выдачи результатов. Возможность простыми действиями подключить его к популярным форумным движкам типа phpBB, yaBB или vBulletin длстаточно быстро заинтересует администрацию других ресурсов.
2. Накопленные по живым комментариям обучающие выборки здесь на ресурсе предельно наглядно продемонстрируют эффективность как самой математики/алгоритмики, так и небольшой ручной работы по собственно их созданию. Сами эти выборки являются отличным товаром с большой добавленной стоимостью.
3. В условиях постоянно изменяющейся новостной повестки и методичек у партнеров администрацией (без вариантов) будет осуществляться как доуточнение имеющихся обучающих выборок, так и введение новых параметров в метрики. Сама эта поддержка в динамичном нынешнем мире - весьма ценный товар, т.е. обучающие выборки изначально целесообразно создавать в виде отдельной небольшой базы данных, которая может продаваться как сама по себе (для разных корпоративных приложений без выхода в сеть интернет), так и в виде удаленного доступа с некой бесплатной/платной подпиской.
4. Помимо самих обучающих выборок весьма серьёзный интерес представляют даже просто классы тематик или наборы рубрик/критерии, которые удастся выделить в имеющемся массиве сообщений. А-ля деловая переписка, набросная заказуха по методичкам, бытовое общение, научно-популярные тексты, невнятные комментарии, нецензурные комментарии с маскировкой, даже тексты со скрытым смыслом "читай между строк" имеют очень характерные статистики.

Комментарии
Зачем? Понять что коммент типа скандальный, можно по числу ответов на него, выделяя слова, бот, хохлик, методичка, клован.
Резко упростит взаимоотношения с комментаторами и вообще пользователями.
Понять можно имея некий опыт, этот алгоритм в автоматическом режиме предоставит достаточно простую для использования метрику.
Очередная никчемная пузомерка. Кому она нужна?
я бы добавил БГГ)
И ТБМ и голосование +1/-1.
И не нужны никакие матрицы, лингвистический анализ, группы и т.д.
Так в жизни зачастую и бывает - простота эффективна
Любая СЗ гораздо информативнее чем любая презентация Но что бы ее прочитать нужно сделать "усилие над собой")
тогда отдельные группы смогут легко подправить рейтинг в нужную им сторону - просто сговорятся и под комментариями будут сыпать этими словами. Как проблему с такой манипуляцией будете решать?
Ну вы, ребята, скоро английских уч0ных догоните.
У меня есть и сложные алгоритмы, оптимизированные под определение авторства текста или дидактический/синтаксический разбор, но в нашем случае, на мой взгляд, вполне достаточно такого примитивного варианта.
Ну вот вы и определили бесполезность своего ранжирования, проявив предвзятость.
Тут чистая математика и закон больших чисел, а предвзятость в обучающих выборках достаточно эффективно растушевывается за счет словоформ и других составляющих текста.
Вот читаю я ваши комментарии и удивляюсь - чем же вам тогда Фоменко не угодил? Тот же самый подход.
Коллега, позвольте я попрошу пояснительную бригаду?
Будьте добры, напишите еще несколько предложений, я не полностью понял вашу мысль и не распознал ни хорошо скрытую иронию, ни ярко выраженный сарказм...
Если вы уберёте из вашей фразы эти не и ни, то не нужно будет просить пояснительную бригаду.
Подход интересный, так как не требует карм и аналогов, и ресурсоемкую часть можно делать в период пониженной нагрузки на сервер, не требует оперативности.
Но алгоритм я пока не понял.
Вот мой коммент выше. Как его обсчитать, и что будет результатом обсчета.
Как построить матрицу.
Алекс, спасибо за интерес к теме.
Алгоритм следующий, на первом шаге весь текст прогоняется через оконную функцию в 5 символов приблизительно вот таким образом:
Подхо - +1
одход - +1
дход - +1
ход и - +1
од ин - +1
Текстовые функции выделения подстроки в строку работают очень быстро, в памяти хранится 5-мерная матрица с комбинациями различных составляющих текст символов (набор символов можно элементарно взять из индекса самой базы комментариев если он уже есть или построить простым 1-значным прогоном, заодно будет статистика символов русского языка из комментариев)
Далее имеющаяся матрица для этого комментария фактически перемножается с такими же матрицами обучающих выборок, после чего в самом простом виде все значения полученной перемножением матрицы складываются. Так как исходные матрицы достаточно большие и разреженные (считай пустые из-за малой длины комментариев), то все пустые ячейки будут перемножением на ноль, а сама операция перемножения матриц на современных серверах считается очень быстро.
Ну а далее полученные цифры можно считать коэффициентами похожести проанализированного сообщения с обучающими выборками и делать все последующие выводы.
Гм. Ок. Получили коммент, получили набор всех пятисимвольных комбинаций в нем, эти все комбинации сложили в базу.
Не совсем понял причем тут пятимерность, это одномерный массив.
Видим потом другой коммент, получили аналогичный массив. И т.д.
Допустим обработали 1000 комментов, имеем 1001. Получили очередной набор всех пятисимвольных комбинаций.
Баллы считаются как? Если пятисимвольный элемент ранее встречался скажем 100 раз в других комментах, то его наличие приносит комменту 100 баллов? Итак, для каждого пятисимвольного элемента?
Немного не так, Алекс.
Считается не просто набор пятисимвольных комбинаций, а количество вхождения каждой из всех разных пятисимвольных комбинаций в текст. Т.е. для случая двухсимвольных комбинаций получается матрица ~32х32 ячейки в каждой из которых записано сколько раз встречается комбинация из буквы-строки и буквы-столбца в тексте комментария.
Т.е. в ячейках матрицы записаны не сами комбинации, а количество раз ее появления в тексте, косвенно - вероятность. (ну если просуммировать все ячейки и привести значение каждой из ячеек в величину, относительную всей суммы матрицы)
Хранить этот массив не надо, его быстрее и проще вычислить для сообщения, нежели записать эту прорву информации в базу.
А вот в базу пишется коэффициент корреляции между матрицей сообщения и матрицами разных обучающих выборок (какие именно - решим и подберем отдельно). В простейшем случае коэффициентом корреляции будет просто сумма поячеечного перемножения матрицы сообщения и матрицы каждой из обучающих выборок. Как побочный эффект - перемножая матрицы обучающих выборок можно грубо оценить их качество, т.е. репрезентативность.
Ну а имея индексы похожести комментария с разными обучающими выборками можно легко подобрать уравнения для решающего индекса.
Я все же не понимаю размерность. Как я понимаю возникает не матрица, а массив, где индексом служит комбинация букв, а значением сколько раз она встретилась в комменте.
На примере текста выше
N['Я все'] = 1;
N[' все '] = 1;
N['все ж'] = 1;
...
То есть откуда возник термин пятимерный? Поясните.
Далее. Хорошо. Построили такой массив.
Что с ним делать и по какому алгоритму? Есть база троллиных комментариев, определенная ранее (вручную) и мы прогоняем каждый коммент через эту базу, смотрим совпадения пятибуквенных комбинаций и что делаем с ними? Наличие пятибуквенной комбинации в базе тролинных комментов дает количество баллов по количеству ее вхождений в троллиной базе?
Как конкретно выглядит алгоритм?
Отлично, Алекс!
Термин пятимерный - это разрядность матрицы. Сам алфавит, если посчитать количество встречания букв в тексте - это одномерный массив статистики букв, считайте столбец или строка значений. Так, буквы А и О наиболее встречающиеся (частые, вероятные) в текстах на русском языке, а твердый знак, и краткое, ё, ФХЦЭЮЯ - наиболее редкие.
Вероятности двухбуквенных комбинаций символов - это уже двухмерная таблица, к имеющейся строке/столбцу первого символа добавляется наоборот столбец/строка второго символа, итого - алфавит по горизонтали, алфавит по вертикали, а в ячейках количества встречаемости комбинаций. Опять статистические особенности русского языка.
Трёхбуквенных - это к таблице добавляется ещё раз алфавит символов по вертикали как третья буква в трехграмме.
Соответственно для пятисимвольных комбинаций это будет матрица с алфавитом по пяти измерениям и в каждой ячейке будет записано количество вхождений такой 5-граммы в текст.
Заполняется матрица простым скользящим окном из текста.
Далее, для коротких текстов эта матрица будет очень разряженной, практически пустой.
Но мы имеем несколько таких массивов, один для обрабатываемого сообщения и по одному для каждой из обучающих выборок.
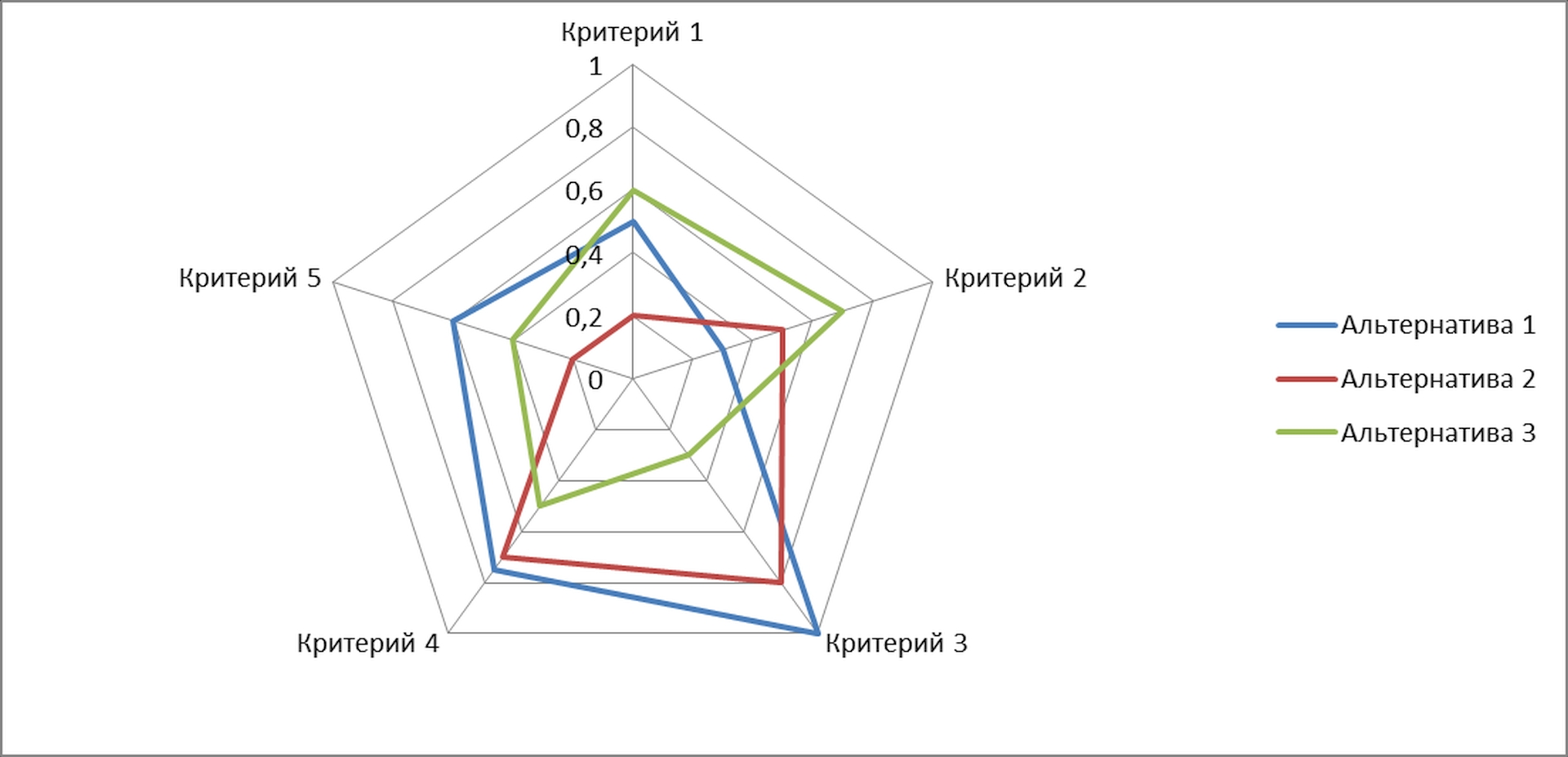
Дальше нам требуется оценить степень похожести массива нашего обрабатываемого сообщения попарно с каждым из массивов обучающих выборок. В общем случае это коэффициент корреляции, но для наших сильно разреженных матриц достаточно просто поячеечно перемножить уже имеющиеся цифры и потом просто сложить все значения новой (полученной перемножением ячеек) матрицы. В типовом случае будет какое-то значение для каждого из обучающих наборов, совсем 0 не получится из-за наиболее общеупотребимых слов русского языка типа междуметий. Вот эта цифра и является в самом простом случае мерой похожести обрабатываемого сообщения и обучающих наборов, т.е. при больших значениях - практически однозначным признаком этой темы. Имея несколько разных цифр сообщение уже легко классифицировать по большому количеству критериев построив для него диаграммы как в примере из основного сообщения.
Занимался этой темой сильно меньше, чем автор (ТС). Попробую по-своему ответить, а автор поправит.
Реализуется через распознающие матрицы примерный механизм персептрона - аппаратного обработчика сигналов для распознавания образов.
Для распознавания некоторой темы (маты, ковид, СВО, психические личности, клоны аккаунтов) строится через обучение или вручную матрица распознавания. Могут для улучшения строиться несколько матриц, чтобы суммировать результаты.
Любой коммент или статья загоняется в такую же матрицу - "сигнал". Как описал ТС, далее просто вычисляются произведения (разреженных) матриц и суммируются (весовые коэффициенты не нужны, они уже в матрицах). Сумма (скалярная сигнатура) - есть число, говорящее, насколько похож коммент или статья на искомый признак.
Обрабатывать можно не сразу, а в периоды наличия свободных вычислительных мощностей, чтобы при Ддосах нагрузка не страдала.
Да, формулируя попроще - именно так.
Персептроны, с вашего позволения, приберегу для оппонентских заключений на авторефераты всяких соискателей, тут публика может и не оценить.
"Персептрон" - персональный сепаратор?
Кто сформирует "обучающие выборки"? Кто этот основатель цензуры?
т.е. если мои коммменты не будут соответвовать шаблону снятому с некого идеального комментатора, мнея забанят?
Свобода выбора вот основа развития и процветания ресурса. Каждый должен сам выбирать что ему читать и кого. А навязывать через "умные алгоритмы" цензуру не надо
Так как сам алгоритм легкий в вычислительном смысле, а репрессии можно и не устраивать (ну по крайней мере сразу и до установления эффективности алгоритма) - то это можно делать индивидуально каждому пользователю.
Как вариант - каждый может добавить в каждую их обучающих выборок по 1-2-3-5 сообщений на свой вкус.
Второй вариант - десять итераций алгоритма на всех сообщениях достаточно несложно разложат их по наиболее существенно отличающимся кучкам, так точно никому не будет обидно.
Не надо словоблудия за алгоритм
Кто определит эталонный коммент?
Так я и говорю: не лишайте человека свободы выбора что читать и что не читать, это тяжкий грех (лишение свободы выбора)
Нет, никакого лишения свободы выбора, наоборот - помощь реализовать свой выбор.
Человек выбирает - уменьшать размер шрифта истеричных комментариев (ну или выделять их розовым цветом, как выберете) или наборот, увеличивать и истерить со всеми, выплеснуть накопившееся.
Другой разговор, что если часто выплескивать накопившееся - то можно оказаться несколько пораженным в праве выплескивать, но это уже отдаем на откуп администрации. Ну типа один "выплеск" в неделю, а остальное время сидите смирненько, не отсвечивайте и не привлекайте излишнего внимания администрации с банометом.
- это цензура.
Некто будет решать что автор которого я читаю и почитаю, должен писать пореже. Чё за ???
Тоже не вопрос.
Премодерация работает достаточно просто. Коммент/статья не попал под критерии "истеричного" - опубликован, если попал - то будет опубликован в следующий час/сутки на усмотрение администрации.
в каждом вашем ответе фигурирует фраза: ....на усмотрение администрации....
это и есть цензура
Тема началась с приведения в пример АнТюра и Счетовода.
Так вот АнТюр пишет менее эмоционально чем Счетовод, но идеи АнТюра имеют большее отклонение от сегодняшней нормы чем идеи Счетовода. АнТюр смотрит "в завтра", а Счетовод работает "в сегодня"
Какому то форумчанину не нравятся идеи АнТюра и он начинает продвигать тему цензуры под видом борьбы с хайпожорством и эмоциональнойй накрутки.
А есть ещё профессиональные инфовоены которые пишут вроде безобидный коммент, но ты знаешь что он сегодня в задаче на разгон и потому бьешь комментатора по голове. Сразу. Алгоритм явно будет против.
Тут неплохо сложилось. Автор читает комменты, отвечает и сам цензурирует. Это фича ресурса.
Алгоритм может быть полезен автору или редакторам на предмет поиска матов, чтобы время меньше тратить. Но в оценке содержания это затея провальная.
Я согласен с опасениями, но ДЕФАКТО, цензура у нас УЖЕ есть.
Вот только что отключил одного после сигнала в личку:
https://m.aftershock.news/?q=comment/12644858#comment-12644858
То есть у нас УЖЕ есть база тех, кого отключили. Почему бы не взять их комменты для "первичного наполнения" базы троллей и прогнать новые комменты через эту базу?
Результат мне самому заранее непонятен, но можно посмотреть.
Что точно можно сказать, предлагаемый анализ лексический, условный "вежливый и терминологически опрятный Овче" данные фильтры проскочит, но комменты типа того что выше, вполне может зацепить и дать сигнал, присмотритесь типа.
Сейчас то все в ручном режиме.
Цензура будет без вариантов, иначе будет беспредел и анархия.
Это приблизительно как кричать о противоправности видеокамер на улицах и видеорегистраторов с радарами на дорогах.
Без правил, пусть даже не правил хорошего поведения, а хотя бы поведения пристойного, ни одному ресурсу не выжить, он превратится в срач и помойку.
Другой разговор, что механизмы контроля должны быть аккуратными и ненавязчивыми, а мера пресечения иметь выраженные эластичность и гибкость. Никто не будет моментально банить или что-то запрещать. Наоборот, будет собрана доказательная база, на основании которой пользователь будет постепенно поражаться в правах вплоть до блокировки в зависимости от степени и частоты нарушений.
Да, цензура на сайте есть. Да цензура завязана на личность основателя сайта.
И уровень её сбалансированный. Не лезьто своими грязными руками.
Вы не можете создать инструмент более рабочий по цензуре чем существующий сейчас. У вас с нет ни компетенций ни ресурса.
Еще раз - это не инстумент цензуры.
Это инструмент автоматизированного поиска сообщений, уже и так либо запрещенных, либо предельно неодобряемых на ресурсе.
Решение - за администрацией. Вы же не удивляетесь, что здесь одни правила, на украинских - другие, на американских - третьи?
Нет, не удивляюсь.
И нынешняя система более чем устраивает.
А вы продвигаете цензуру под видом "новая веха в истории человечества", проходили: компьютер не заменит человека до тех пор пока не научится спихивать свою раоту на другой компьютер и смеяться над тупыми шутками старшего компьютера.
Моя цель - не цензура, а убирание тех текстов, которые пользователь сам не хотел бы читать.
Предлагаемый инструмент может работать и как жёсткая цензура, на сайтах и она нужна. (Реклама "Шкафы-купе" в комментариях вам нужна?)
Если инструмент может = будет
Во втором абзаце выдуманная проблема, в обоснование вашей позиции не годится.
И еще: зачем простому форумчанину такой мощный инструмент? Его личных познавательных и аналитических способностей не достаточно отличить зерна от плевел? Тогда если он тупой, то ты руках тупаря предлагаемый инструмент пострашнее атомной бомбы.
Зачем администрации новый инструмент если все и так работает?
Ну вот, ваши комменты вполне подойдут как "истеричные", для обучающей матрицы. ;-)
А что в них истеричного-то? У человека сомнения он спорит.
Мне тоже пока не совсем понятно как это работает.
Всё зависит от того, кто и как будет настраивать этот инструмент.
Если есть доверие, можно дать потренироваться на хохлоботах, производных мата и переход на личности с уводом темы, как седня в теме Tinkle bеll.
Обкатав инструмент, можно сдавать в аренду.))
п.с. Инструмент лишним никогда не бывает, лишь был не очень тяжёлым.))
Первичная база уже есть - это комменты уже забаненных, их немало за годы ресурса набралось.
Другое дело, насколько результат полезен.
Я за следующее - автору записи просьба прокмментить:
1. Мы сделаем скрипт, который обработает базу комментов ранее забаненных, чтобы собрать стату условно негативной выборки. Но понимаем при этом, что забаненные не всегда писали как тролли, лексический анализ и смысловой разные вещи. Тем не менее, полагаю, доля троллизма там будет существенно выше чем в среднем.
2. Мы сделаем пробный запуск оценки свежих комментов, на основании этой базы.
3. Посмотрим сами, и, если результат покажется полезным, покажем сообществу.
Ярика, как оппонента, подключим на пункте 3 (до сообщества).
Прошу прощения, Алекс, говоря о доверии, я не себя имел ввиду.
У меня до зимы ни времени, ни мобильной связи не предвидится.((
и автор чего-то молчит уже полдня..
Занят на основной работе, уж извините.
Время тут потребуется лишь на просмотр того, что нам движок сгенерит - как я понимаю сформирует выборку подозрительных комментов на взгляд алгоритма, а мы посмотрим и решим, практично ли это.
Да, на выходе будет список комментов, отсортированный по степени статистической похожести на комменты уже забаненных.
Причем групп забаненных лучше всего сделать несколько, типа забаненных за мат, за истерики, оскорбление ВПР или пользователей, это будет нагляднее всего.
И лично я против называния этого инструмента ИИ.
Нет, никакой это не И и тем более ИИ, это просто математическая статистика, элегантно примененная в одной узкой области человеческой деятельности.
1. Да, ИИ не при делах, это вообще неудачный термин - не только здесь, придуманный пиарщиками и профессиональными выбивателями бюджетов.
Статистический анализ в данном случае.
2. Предлагаемые группы выделить проблематично, так как на уровне базы данных этой категоризации нет. Есть просто один признак - аккаунт отключен.
Как я понял, нужны именно категории комментов по которым делаем матрицы и которые будут "шерстить" сайт на соответствие признаков.
В качестве подборок, которые возможно прийдётся собирать вручную, весь смысл затеи.
Иначе у вас будет "каша" непонятно чего. Троллинг пока не трогать, им пользуются все. Брать категории попроще.))
Хорошо, не вопрос.
Завтра утром я в общих чертах опишу приблизительную программу действий для реализации обсуждаемой здесь концепции и какие приблизительно элементы администраторского интерфейса потребуются в ходе разработки.
Во избежание любых инсинуаций изначально отказываюсь от любых сведений о самих пользователях или их комментариях. Всё обсуждение будет исключительно публичным с подробными ответами на все вопросы.
По математике вопросы остались или все уже понятно?
Страницы