






По результатам работы по гранту попросили написать научно-популярную статью для "Ъ-Наука". Для меня это новый жанр. Поэтому решил предварительный вариант выложить здесь - услышать отзывы, насколько это понятно и интересно.
Каждый человек уникален. Мы отличаемся нашими геномами, окружающей нас средой, поведением, историей болезни, прошедшим и текущим медицинским лечением – это часто приводит к тому, что лечение, в первую очередь при помощи разных лекарственных препаратов, имеет разную эффективность.
Поэтому в современном здравоохранении все большее внимание уделяется персонализированной медицине, которая представляет собой совокупность методов профилактики, диагностики и лечения болезней, основанных на индивидуальных особенностях пациента. Истинная персонализированная медицина должна базироваться на "виртуальном пациенте" - цифровом двойнике реального пациента, который, в идеале, формируется и накапливается в течение всей жизни пациента, как результат его взаимодействия с системой здравоохранения.
Это очень сложная задача, в мире ее еще никто не решил. Мы попытались решить ее на примере лечения артериальной гипертонии. Это сложное мультифакторное заболевание, для лечение которого используются разные классы лекарственных препаратов, и часто врач пробует несколько схем лечения, чтобы найти оптимальный вариант для конкретного пациента.
При решении этой задачи было 4 основных вызова:
1) построить детальную цифровую модель биохимии и физиологии человека с достаточным уровнем детализации для заданной болезни. Мы полагаем, что сейчас не реально построить "виртуального пациента" на все случаи жизни. Поэтому наш подход - создать набор основных блоков, а из них собирать модель под заданного пациента и болезнь (как из блоков конструктора Лего). При этом, каждый блок может состоять из множества вложенных в него блоков. На самом нижнем уровне компонентами блоков являются биохимические реакции и дифференциальные или алгебраические уравнения, описывающие изменения соответствующих физиологических параметров (рисунок 1).
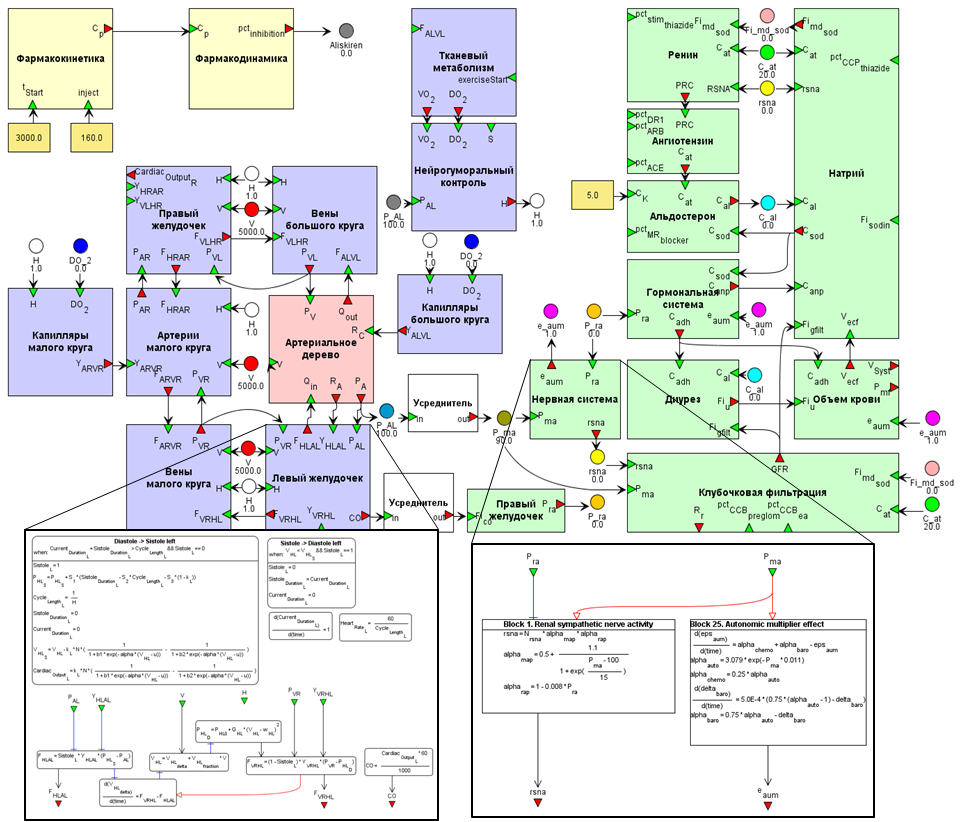
Рисунок 1. Диаграмма модели регуляции артериального давления у человека. Каждый блок содержит набор переменных и уравнений. Блоки соединены друг с другом, если у них есть общие переменные и параметры.
2) персонализация модели - даже такая модель содержит сотни параметров. В общей модели они берутся для некоторого усредненного человека. Если посмотреть историю болезни пациента, то из нее нельзя извлечь данные даже для 10% параметров модели. Для решения этой проблемы мы совместили 2 подхода. Первый - для многих физиологических параметров известны их зависимости от роста, веса, пола и возраста пациента. Из этих данных о пациенте мы можем рассчитать соответствующие параметры. После этого шага параметры модели уже ближе к реальному пациенту, но по прежнему многие из них остаются усредненными, хотя какой-то из этих параметров может у реального пациента существенно отличаться. Чтобы выйти из этой ситуации, использовался второй подход - строилось множество виртуальных пациентов (от 2 до 10 тысяч), при этом известные параметры у этих моделей соответствуют данным заданного пациента, а неизвестные - могут существенно варьировать. После этого проводится “лечение” созданной популяции, т.е. моделирование воздействия разных лекарственных препаратов (алискирен, лозартан, амлодипин, эналаприл, бисопролол и ряд других). При этом каждый виртуальный пациент реагирует на “лечение” по своему, не для всех оно будет эффективно. Это позволяет выделить группы виртуальных пациентов со схожей реакцией на лекарственный препарат и определить какие именно параметры определяют разделение на эти группы. В частности, такой анализ может позволить определить какие еще исследования нужно провести для данного пациента, чтобы понять к какой группе он относится и какое лекарственное лечение будет для него наиболее эффективно (рисунок 2).
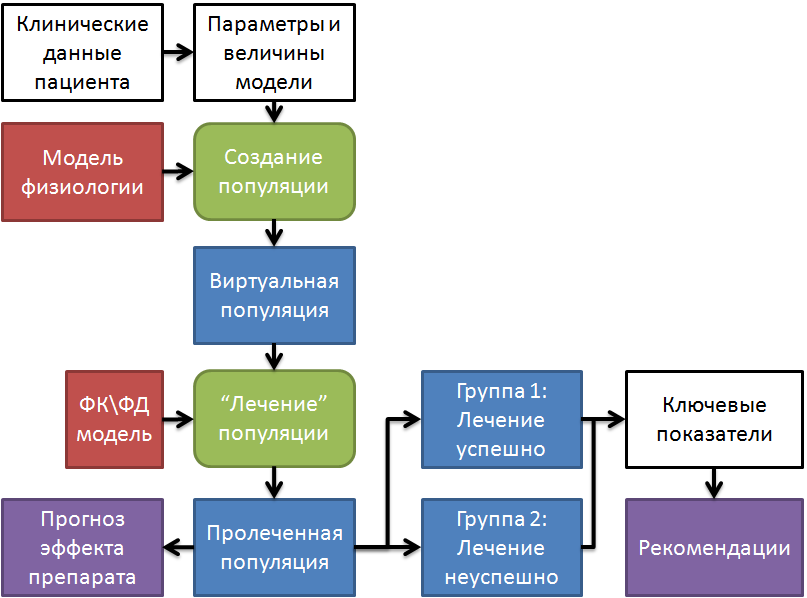
Рисунок 2. Чтобы решить проблему с неизвестными данными для реального пациента создается набор виртуальных пациентов, для которых моделируется лечение и определяется наиболее вероятный результат.
3) для каждого лекарства составляется 2 модели:
- фармакокинетика - как данное лекарство (и его производные) поступает, распределяется по организму и выводится из него;
- фармакодинамика - как данное лекарство воздействует на организм. Основой для построения таких моделей служат данные клинических испытаний лекарств, в которых описывается, как данное лекарство подействовало на группу пациентов. Однако, для построения модели нам нужно знать детальный молекулярно-биологический механизм действия лекарства и константы соответствующих биохимических реакций, а также исходные персональные данные всех пациентов, прошедших лечение, а не усредненные по группе значения. Но поскольку такие данные не доступны, то нам опять приходится определять параметры модели на основе генерации набора виртуальных пациентов, так чтобы их усредненные параметры соответствовали исходной выборке, а результат "лечения" соответствовал данным клинических испытаний.
4) данные пациентов - выше мы обсуждали проблему неполноты данных о пациенте, чтобы построить его цифрового двойника. Но есть и другие сложности:
- хотя сейчас истории болезней пациентов ведутся в электронном виде, они недостаточно формализованы, для того чтобы их можно было использовать напрямую для модели. Требуется предварительная подготовка этих данных квалифицированным специалистом-медиком.
- идеальной и наиболее простой для моделирования является ситуация, когда в клинику пришел больной пациент, которого до этого не лечили и для него провели детальное обследование, после этого назначили лечение, и через некоторое время вновь провели детальное обследование, чтобы оценить эффективность лечения. Поэтому для нашей работы мы отбирали ограниченное количество пациентов, которые наиболее полно соответствовали этим требованиям.
Как практический результат работы, была разработана компьютерная программа для оптимизации лечения гипертонии. Программа работает следующим образом: в нее вводятся имеющиеся данные пациента, после этого программа создает множество виртуальных пациентов, для которых она предсказывает наиболее вероятный эффект их лечения разными лекарствами и какие дополнительные исследования нужно провести, чтобы сделать более точный выбор. Однако для внедрения этой программы в медицинскую практику нужно пройти еще большой путь - апробировать ее на большом количестве пациентов и пройти процесс сертификации.
Тем не менее, предложенная технология построения виртуального пациента - это большой шаг вперед к построению цифрового двойника реального пациента. Ее дальнейшее развитие позволит прогнозировать действие и эффективность различных схем лекарственного лечения для многих болезней человека, что открывает новые возможности для персонализированной медицины.
Врезка 1
Если сравнить самые сложные биологические модели, то они очень редко содержат более тысячи компонентов, в то время как инженерные модели, например модель современного процессора содержит более миллиарда компонентов. Почему инженеры могут создавать такие сложные модели, а биологи нет? Основных причины 3:
1) для этого нужна формализация предметной области. Все знают, как выглядят электрические схемы - есть правила и стандарт. Каждый специалист может прочитать и понять такую схему. Только в начале 2000-х подобные стандарты (SBML и SBGN) были приняты и биологов. Юрий Лазебник очень хорошо описал эту проблему в статье "Может ли биолог починить радио, или что я понял, изучая апоптоз".
2) нужно соответствующее специализированное программное обеспечение. Чем сложнее модели, тем сложнее и программное обеспечение, его разработка занимает сотни человеко-лет.
3) инженерные модели созданы человеком - одному человеку гораздо легче понять то, что создано другим человеком - в них используется человеческая логика. Биологические системы созданы природой и их логику мы не до конца понимаем.
Поэтому для построения сложных биологических моделей нужно использовать инженерный подход - что мы и сделали. Для построения биологических моделей мы разработали соответствующее программное обеспечение - программный комплекс BioUML (Biological Universal Modelling Language, http://biouml.org). На его разработку ушло более 100 человеко-лет, разработка была начата в 2002 году. Сейчас, на наш взгляд, это наиболее мощная платформа для модульного моделирования биологических систем в мире. Пользователь может установить BioUML как на своем компьютере, так и использовать его "облачную" веб-версию(рисунок 3). В последнем случае, несколько пользователей могут одновременно работать над одной моделью, подобно редактированию документов в Google.

Рисунок 3. Веб-интерфейс программного комплекса BioUML для моделирования сложных биологических систем.
Комментарии
На мой взгляд Рис. 1 слишком перегружен для научпопа.
Не отражен текущий статус проекта, есть ли практика и статистика? Экспертные отзывы?
В этом году завершается соответствующий грант РФФИ.
Статистика - с одной стороны работали по базе 1500+ пациентов, но мало показателей, с другой - всего 7 пациентов, но тщательно и детально обследованных.
Есть научные публикации по теме проекта в рецензируемых журналах, защищена кандидатская диссертация.
Ниже один из экспертных отзывов из РФФИ:
Обоснование оценки " Актуальность заявленной темы исследований"
Построение математических моделей деятельности организма - чрезвычайно сложная задача. При этом попытка добиться хорошего количественного совпадения результатов, да еще и с привязкой к конкретному пациенту ( или группе схожих по каким-то признакам пациентов) - задача крайне сложно разрешимая ввиду чрезвычайно большого количества параметров задачи. Отметим, что точность измерения многих параметров (например, констант химических реакций в организме) крайне мала. Таким образом, создание комплексной адекватной математической модели физиологических процессов в организме и тех или иных воздействий и их влияния на организм в целом представляется задачей весьма перспективной и очень актуальной.
Обоснование оценки " Соответствие предложенных подходов и методов планируемых исследований поставленной цели и задачам проекта"
В проекте дан обзор состояния работ по тематике проекта, в частности, в России. На взгляд рецензента, обзор несколько фрагментарен и не затрагивает несколько интересных циклов работ по моделированию динамики крови в организме или работы по функционированию деятельности ансамбля нефронов. Конечно, обзор литературы в заявке не претендует на исчерпывающую полноту. План работ, сформулированный в проекте, весьма обширный. Моделирование в динамике действия на пациента только одного препарата предполагает не только моделирование большого и малого кругов кровообращения, но и почек (как подчеркнуто в заявке), возможно, также потребуются описания систем, например, кроветворения или свертывания крови. Как подчеркнуто автором проекта, решение будет зависеть от чрезвычайно большого количества параметров, часть которых плохо известна. На "раздобывание" требуемых значений и на верификацию параметров также требуется время.
Обоснование оценки " Уровень имеющегося научного задела и характеристика участников проекта"
В заявке представлен подробный детализированный план работ. По-видимому, из-за большого объема работ в полном объеме план будет неосуществим, однако даже частичное выполнение такого плана исследований способно принести весьма интересные научные результаты.
Заключительные замечания эксперта
Очень смелый и амбициозный проект. По-видимому, для его выполнения в заявленном объеме потребуется лет 10-12, но и за три года несомненно интересные результаты получить можно.
Обоснование оценки " Новизна предложенного исследования"
Автор продвигает идею агентного подхода к моделированию, хорошо зарекомендовавшему себя при построении математических моделей в биологии и медицине в последние годы. Отдельные модули программ (или отдельные "агенты") включают в себя части, основанные на известных численных методах решения обыкновенных дифференциальных уравнений или уравнений в частных производных
Обоснование оценки "Соответствие уровня исследований и ожидаемых результатов проекта мировому уровню"
Подобных математических моделей "виртуальных пациентов" в мире не построено. Любой шаг в этом направлении будет являться значительным прогрессом.
Ок, понял, спасибо.
Достойно. На стыке разных дисциплин дело идёт гораздо быстрее, что Вы и продвигаете.
Ц: "...Каждый человек уникален...."
Не будет ли "залечен" достаточно уникальный, но здоровый человек, попав в жернова инженерного алгоритма?
А шо делать? Лучше иметь дурацкий план чем никакого. Наши врачи до сих пор в основном используют методу Галена, я не хочу сказать, что Гален плох, упаси Бог, но прошло уже достаточно времени, чтобы попробовать нечто новое. Тем более пациенты вроде не особо страдают.))))
получится как с насморком - если не лечить, длится неделю. а если лечить то вылечивается за 7 дней:)
виртуальность пациента кмк будет работать нормально лишь после расшифровки днк к примеру, когда будет понятно что вообще из себя представляет данный конкретный индивид, начиная от алергий и отношения к герпесу и заканчивая всеми изменениями от перенесенных болячек. ато знаю одного персонажа, с детства лечили от давления всеми способами, а к 35 годам случайно выяснилось что вся семья по женской линии и он заодно носители микоплазмы, собсно организьм так и реагировал то температурой легкой то давлением. ни один айболит не предполагал даже. сожрал курс антибиотиков, за год ни одного всплеска давления и простуда тоже отстала..
Оно понятно, что лучше быть красивым и богатым, чем бедным и больным. Однако... маэмо тэ що маэмо.(с)
Вот почему амеры наглотавшиеся лекарств под руководством суперпрофессиональных врачей превращаются в монстров!
Идея хороша..., но как-то странно все выглядит.
Первая схема для научпопа совершенно бесполезна, ИМХО, это какой-то навал всего. Почему все свалено в одну кучу?
Что общего у альдостерона и гормональной системы? Выглядят они совершенно одинаково, хотя первое часть второй, и если первое конкретное вещество, то вторая,- это суть множество тканей организма. Может быть имеет смысл как-то обособить ткани от всего остального?
Я не знаю всей специфики вашей работы, но разве не проще было бы разложить весь организм на органы (ткани) и все проводить как взаимодействие межу ними (применить объектно-событийную модель), было бы в разы нагляднее, ИМХО.
Что касается самой идеи, ее можно только поприветствовать, удачи вам в вашем прекрасном начинании,
З.Ы.
Мне кажется, что вы должны максимально ужесточить иерархию структур и зависимостей, иначе с моделями будет беда, но это мое личное ИМХО.
Плюс можно взять из теории автоматических систем управления такие понятия как обучение и самообучение математической модели.
Хотя б что попроще пока сделать. Привести знания в систему, а там уж совершенство бесконечно.
Грант закончится, Автору и его коллективу надо за новым грантом идти. Не будут думать, как прокормить семью - многого добьются.
Например, можно использовать аппарат нечётких систем: нечётких множеств, нечёткой логики, нечёткого моделирования и т.д.
Математика и алгоритмы, предполагаю, наше преимущество. Плюс, конечно же, знание предметной области.
Тут надо очень осторожно выбирать, алгоритмов много, а задача одна.))
Без этого ни куда, тут вы правы.
> это какой-то навал всего. Почему все свалено в одну кучу?
это блочная структура реальной модели.
Как-то я специально интересовался, каким образом можно разбить сложную систему на блоки. Универсального алгоритма нет - зависит от контекста и задачи.
В нашей работе мы редко создавали блоки с нуля. Как правило мы находили уже готовые модели для соответствующих блоков, адаптировали их и складывали в конкретную модель.
В этом одна из "фишек" работы - мы не старались сделать одну модель на все болезни и все задачи. Сделали набор блоков, собрали из них несколько вариантов модели и затем смотрели, какая будет лучше работать. В одном из вариантов модели у нас подробно моделируется кровоток (55 основных артерий), но такая модель очень долго считается, а качественного улучшения в работе модели нет.
Поэтому получается, что структура модели не соответствует анатомической структуре человека. В зависимости от важности подсистемы мы описываем ее с разным уровнем детализации.
Если провести аналогию с программированием, то мы используем не объектно-ориентированный подход, а компонентный. И наша основная задача четко специфицировать входы и выходы компонентов.
> Первая схема для научпопа совершенно бесполезна
с одной стороны да - из нее мало, что понятно. С другой стороны - вот она реальная структура рабочей модели. Если бы я был на месте на читателя, мне бы хотелось увидеть, что-то реальное, пусть и не совсем понятное.
Тут с вами не поспоришь, но разве вы не работаете с иерархией систем?
Это вряд ли возможно пока что ИМХО.
В смысле поведение какой модели больше соответствует медстатистике?
Для того списка задач, который вы ставили для своих моделей.
С этим все ясно, спасибо, но это очень уменьшает научпоп потенциал таких моделей, ИМХО.
Это ясно. Компонентный метод хорош, но совершенно не нагляден. Потому что вы используете в качестве компонент совершенно разнородные объекты иногда даже не отдельные объекты, а их комплексы.
Это имхо задача второстепенная. Главное сами компоненты специфицировать.
Главное сами компоненты специфицировать.
Не могу с вами согласиться чтобы совсем уж так. Вы просто тренируете нейронную сеть, к реальным моделям она мало относится. Это просто комплекс нодов с весами, вы что-то подаете на вход, и что-то получаете на выход. Называть эти ноды вы можете как хотите, а можете вообще никак не называть, ИМХО.
Нет, у нас механистическая модель - т.е. набор алгебро-дифференциальных уравнений с событиями, т.е. это портретное моделирование. Мы пытаемся, насколько это возможно и известно, использовать известные механизмы взаимодействий между компонентами системы. В качестве блоков используются, как правило, уже существующие и валидированные на экспериментальных данных модели. Хотя бы из-за этого такая модель уже имеет большую ценность - знания по физиологии и биохимии человека формализованы в виде набора уравнений и проверено, что такая модель:
- соответствует экспериментальным данным в норме;
- может воспроизвести разные патологические состояния и процесс лечения при помощи разных лекарств.
"Давным, давно ... Когда нам было все равно ..."
я спросил у одного стоматолога - почему бы вам не ввести паспорт зубов пациента: на каждый зуб - диагноз, кто лечил, почему так, какие материалы, обезболивающее, ...
Мне ответили - это ведь зафиксированная ответственность, кому это надо?
"Что есть, что пить, с кем жить. И жизнь вся проходила хай-фай, мы пили ..."
Очень интересная статья и идея.
Просто супер. Как будто в будущее одним глазком заглянул.
Это прообраз искусственного интеллекта, однако система, в любом случае, останется автоматизированной - окончательное решение будет принимать человек.
Тема для попилов и откатов, к реальной жизни отношения не имеет.
К реальной жизни имеют уголовные дела и посадки по результатам этих дел. То, что реализация научных разработок весьма слаба - факт.
Вы представляете размеры грантов РФФИ? Какие там могут быть попилы и откаты?
Пока это только наука, причем ее передний край. Когда это войдет в практику? Может через 5 лет, а может через 20.
Нынче попилы и откаты, ув. Insk, и есть реальная жизнь!
Это - шаг в будущее. Может быть когда-нибудь будут сниматься базовые параметры новорожденного чтобы потом фиксировать динамику развития. Кстати, в этой работе для чистоты эффекта было бы неплохо параллельно проводить количественный и качественный анализ применяемых лекарственных препаратов.
Интересная тема, на стыке наук , надо глубоко вникать ,но имхо мало кто из практикующих врачей может пока осознать все это целиком, я лично хорошо если половину понял. Модель требует введения множества параметров, что, каждого человека вот так детализировать? Как это в массовом порядке делать? Имхо молодым докторам
лучше лечить по нынешним протоколам, так меньше риска получить судебные иски от прошаренных пациентов. врач с опытом - традиционно индивидуальный подход. Описанный метод имхо, дело не столь
близкого будущего, но дело нужное, а пока все остается как есть, мы идём по порочному пути . В советской медицине и то больше проку было.
Мысли интересные, возможно в этом что-то есть. Но. Слишком дорого досконально изучать каждого пациента, чтобы назначить банальную антигипертензивную терапию.
Гипертоников с терапией миллионы, сотни миллионов.
Учитывая, что повышенное артериальное давление является нормальной реакцией организма на целый ряд процессов предлагается её (нормальную реакцию), симптом по сути, лечить "глубоко научными методами": - поиском за деньги больного, наиболее эффективного лекарства для приведения давления к усредненной "норме". Про поиск и классификацию причин болезни, вызывающих такую реакцию организма, околонаучных сочинений не выдумывают, ИМХО продавать нечего будет.
Всё вернётся на круги своя. Вернемся к чеховскому фельдшеру. - С чем пришел? - Да, я...- Все ясно, Иван. Пойди и выпей огуречного рассольчика. Моментальный точный диагноз, и безотказно действующее снадобье. Любой суперКомп от перегрева пожелтеет, но зато после тщательного обследования выдаст наиболее эффективное лицензированное лекарство - касторку.
Только, учитывая реалии, в виде фарса:
Больной: Доктор помогите, я совершенно не чувствую вкуса!
Врач: Сестра, принесите таблетку номер 23 и дайте больному. Больной(разжевав таблетку, изумлённо): Так это же дерьмо!
Врач: Сестра, пишите-больной излечён.
ЧЕРЕЗ ПОЛГОДА
Больной: Доктор помогите, у меня совершенно пропала память!
Врач: Сестра, принесите таблетку номер 23.
Больной(возмущённо): Так ведь это дерьмо!!!
Врач: Сестра пишите-больной излечён.
ещё через полгода.
Больной: Доктор помогите, у меня потенция!
Врач: Сестра, принесите таблетку номер 23.
Больной(зло): Да е*ал я вас и вашу таблетку!!!
Врач: Сестра пишите-больной излечён.
Аж умилился, вспомнил свое счастливое советское научное детство на кафедре фармакологии 1-го Меда:
Теперь по сути, но со ссылками на вышеизложенные аксиомы.
Во-первых, строить изолированную модель артериальной гипертензии бессмысленно, см. аксиомы номер раз и два. АД реагирует абсолютно на все, с кем-то поругался - повысилось, принял бокальчик холодного красного винца в горячей ванне - понизилось, возникли проблемы с легкими и, соответственно, гипоксия - сердце начинает усиленно молотить, кровь прокачивать, занялся аутогенной тренировкой по Шульцу, стал спокоен, как удав, с пониженным АД. В общем, идите в мед. вуз и изучайте сначала нормальную, а потом патологическую физиологию, биохимию и прочие рецепторы, медиаторы и сопряженные с ними мембранные каналы, фунциональные системы и их взаимодействие, и только потом пытайтесь строить математические модели.
Во-вторых, по выборке из 7 хорошо обследованных пациентов и полторы тысячи плохо обследованных. Вообще-то в клинических испытаниях на 3-ей фазе для того, чтобы выявить влияние лекарства на крайне ограниченный набор показателей, одного, ну пары-тройки, используют выборки в 300 - 500 человек, причем выборки стараются сделать максимально гомогенными. Отсюда возникает описание исследований "проспективные плацебо-контролируемые двойные слепые рандомизированные", с жесткими критериями включения/исключения пациентов, с минимизацией эффектов плацебо и предпочтений/предубеждений исследователей.
А если исследования "обсервационные ретроспективные", то размер выборок для изучения единственного параметра может составлять несколько тысяч человек. Например, среди 5 тысяч пациентов, госпитализированных за 10 лет с диагнозом "внебольничная пневмония", микробиологические анализы брали у половины, из 2,5 тысяч тех, у кого брали анализы, только у половины была мокрота, а остальные просто плюнули в пробирку, из тех, у кого была мокрота, только у 50% микробиологи вытащили клинически значимые возбудители, а не обычных обитателей полости рта. Из около 600 пациентов с реальными возбудителями нужны те, у которых анализы брали и в первые сутки после госпитализации, и через 7 - 10 дней после антибиотикотерапии. Таких набирается около 100 человек. Вот у этой сотни из 5 тысяч и можно далее изучать один единственный параметр, как изменилась устойчивость патогенов после недели лечения антибиотиком 1, и после лечения антибиотиком 2. Авось по критерию Пирсона (кси-квадрат) вылезут статистически достоверные различия.
А в вашем случае вы пытаетесь на 7 хорошо обследованных, и 1500 плохо обследованных пациентах, представляющих собой неизвестную выборку по неизвестным критериям включения/исключения, воспользоваться аксиомой номер 2 и выявить, ой, а чой-то в данном месте в данное время влияет больше? При том, что на АД в соответствии с аксиомой номер раз влияет всё на всех уровнях всех систем. Какую статистическую гипотезу вы можете сформулировать и проверить таким обазом?
В-третьих, по поводу индивидуализации лечения. На практике всю кучу параметров, которые вы пытаетесь вбить, в массовом практическом здравоохранении не используют. В качестве примера, есть около десятка различных шкал оценки тяжести пневмоний, а в массовом здравоохранении пригодны только две, в которых не учитывается парциальное давление кислорода крови, потому что его обычно нигде, кроме реанимации мерять нечем.
Но при этом грамотные врачи лечат неплохо, в том числе артериальную гипертензию, если пациент хочет лечиться. Так что задачу индивидуализации лечения можно решать менее громоздкими способами.
В общем, на данный момент полная ботва.
Поэтому вам надо увеличить финансирование раз в 20 сроком лет на 50, чтобы грамотные медики подключились, и сразу прописать всего пациента, а не только АД. Авось через полвека что-нибудь полезное получится, если не будете сектой IT-килек в собственном гною.
Это научно-популярная статья, из нее, судя по вашему комментарию, сложно понять и оценить уровень исследования.
Поэтому несколько комментариев:
1) разработка модели началась в 2006 году, тогда был другой грант - на интеграционные проекты, в нем участвовало 3 института (1 академик, 2 профессора и несколько кандидатов). Основные результаты изложены в 2 монографиях, там же есть и гораздо более подробное описание модели, а так же детальный обзор по артериальной гипертонии от ученых физиологов, которые ей занимаются всю жизнь. Если интересно - могу дать ссылки и прислать соответствующие публикации.
2) затем мы несколько лет отлаживали модель на экспериментальных клинических данных, по новой версии модели написана отдельная книга (издано как учебное пособие для студентов) - около 200 страниц;
3) в 2016 начался этот проект, вызовы этого проекта описаны в статье. В проекте участвуют 3 медика, из них 2 доктора наук, один из которых несколько дней в неделю принимает пациентов.
Мы просмотрели сотни статей с результатами клинических испытаний, чтобы вытащить конкретные цифры, чтобы смоделировать действие разных лекарственных препаратов. Основная проблема клинических испытаний - они никогда не дают доступ к исходным данным, только результаты стат. обработки. Поэтому и приходится выкручиваться через создание популяций виртуальных пациентов. Интересно, что фарм. компании, по крайней мере в публичных докладах и исследованиях используют этот же подход.
Поскольку я стараюсь более-менее отслеживать, что происходит в мире по этой теме, то могу сказать, что работа в отдельных аспекта выше мирового уровня:
1) BioUML - инструмент, который мы создали
2) модель.
> Поэтому вам надо увеличить финансирование раз в 20 сроком лет на 50, чтобы грамотные медики подключились, и сразу прописать всего пациента, а не только АД.
хоть и мечта, но мы пытались, и дальше будем.
Раньше было такое модное направление - технологические платформа, одна из них была "Медицина будущего" - http://tp-medfuture.ru/.
Там какое-то время был НТС "Медицинская биоинформатика", где мы пробовали провести проект "Виртуальный пациент", как комплексный проект полного цикла. Но затем так как-то все заглохло - финансирование на технологические платформы не пошло.
Первичку по клиническим испытаниям фармкомпаний действительно не вытащить, и хорошо, что на вас профи от медицины работают.
Но дело в другом. Даже имея собственный опыт в медицинских исследованиях и кое-какой медицинской информатике я по данной статье так и не понял, что именно и зачем вы делаете. А что тогда спрашивать с широкой публики?
Вроде как речь идет о подборе терапии по артериальной гипертензии? Тогда все сильно переусложнено.
Если же речь идет о модели "виртуального пациента", в которую можно подставить доступную участковой тетке фактологию по конкретному пациенту, и на выходе за счет внутренней механики модели заткнуть те дыры в диагностике, которые недоступны в массовом здравоохранении, тогда в одной артериальной гипертензии смысла нет. Надо вбивать все органы и фунциональные системы, потому что стеб стебом, но оно же действительно всё влияет на всё на всех уровнях всех систем.
Другое дело, что для моделирования не обязательно с разгону лезть в молекулярную биологию, наверняка многое можно смоделировать на уровне показателей, доступных приличному клиницисту в хорошо оснащенной больничке.
Но тут опять возникает вопрос корреляции модели с реальностью. А у вас тут вроде как порочный замкнутый круг - делаем виртуального пациента, но поскольку проверить адекватность модели на практике не можем, устраиваем толпу виртуальных пациентов, которых тем более на практике проверить нельзя.
Я выше привел пример с оценкой динамики устойчивости патогенов к антибиотикам в ходе лечения - ради проверки единственного показателя с четко сформулированной гипотезой пришлось перелопачивать первичку (благо имели базу данных, специально заточенную под клиническую микробиологию и антибиотикотерапию) на несколько тысяч пациентов.
А у вас в распоряжении 7 хорошо обследованных пациентов, и полторы тысячи не понятно кого, куча переменных и невнятно сформулированные гипотезы для проверки (если они вообще сформулированы).
Оно конечно можно уповать на "большие данные", но там свои заморочки. Во-первых, вопрос об их качестве - "миллионы мух не могут ошибаться, это действительно анализ кала на дисбактериоз, и миллионы участковых теток тоже не могут ошибаться, это действительно диагностика и лечение уровня участковых теток". Во-вторых, Ростех пытается подгрести всю медицинскую первичку под себя, и не факт, что из-под его толстого корпоративного седалища что-то можно будет вытащить исследователям.
В общем, начать и кончить, за полвека и при щедром финансировании.
Поддержу, если уж очень хочется создавать модели, то язык моделирования должен предусматривать несколько степеней абстракции - более общие и более подробные/детальные способы моделирования. Кроме того, каждая из моделей должна иметь возможность валидации и настройки на предмет адекватного описания того, что она описывает.
Также не понял, какие задачи решаются - для отдельных индивидуумов или выборки в целом?
Совершенно верно, наш инструмент как раз это поддерживает. Это было одной из задач - создать такой инструмент, в котором модель собирать из блоков было почти также легко, как конструктор Лего.
Было несколько задач.
1) воспроизвести данные клинических исследований - эти данные в литературе всегда представлены в виде выборки, поэтому генерируем виртуальную популяцию, насколько это возможно, воспроизводящую выборку пациентов, использованных в выбранном клиническом исследовании.
2) сделать выбор или прогноз по лечению для конкретного пациента - для этого пациента у нас есть значения только нескольких параметров, которые можно напрямую перенести в модель. Что делать с остальными (большинство) параметров? Мы пробуем разные варианты их значений - получается набор виртуальных пациентов. Моделируем и смотрим, для всех ли из них получился одинаковый результат, если разный - то смотрим, какие неизмеренные у реального пациента параметры отвечают за этот разный результат.
Идея интересная, но на мой взгляд выбран слишком механистический подход, который при перегрузке деталями может и подвести, ведь в организме много связей сложных, трудно формализуемых, если не описывать все и вся.
По статье: для статьи нужно более подробно сосредоточиться на решаемой задаче, возможно с примерами, и уже потом показать, как и какой инструмент может в этом помочь.
По инструментарию: инструмент должен представлять собой не только язык описания (моделирования), но и сопровождаться методикой применения, тут бы как раз сосредоточиться на описании методики применения. А у меня, как минимум, 2 вопроса по методике :
1. Как осуществляется валидация содеянного на предмет адекватности описания предмету? Ведь мало создать модель, нужно понимать, что она адекватна. При разработке формальных моделей тут же должны рассматриваться методы ее вализации. Как простейший пример - модели данных. По работе я прошу всегда исполнителей сопровождать модель данных проверочным набором данных, который описывает предметную область и укладывается в модель.Так вот - как валидируются ваши далеко не тривиальные модели? Я понимаю, что они создаются во многом на основе чужих построений, но если в результате компиляции чужого опыта из отдельных правильных элементов получится нечто неадекватное, то смысла в построении таких моделей нет.
2. Как осуществляется применение на практике. Зачем такие модели создаются и как применяются? Тут нужны более подробные объяснения - начиная с постановки прикладной задачи, Есть ли возможность с помощью полученной модели "вести" пациента (осуществлять мониторинг и при расхождении с реальностью проводить коррекцию модели?), решать задачи "что будет если"? Т.е. проводить адаптацию моделей под конкретного человека и проводить имитационное моделирование с целью нахождения каких-либо решений (что опять же возвращает нас к постановке задачи)?
путем проверки, может ли модель воспроизвести экспериментальные данные
- в норме
- в патологии
- при лечении (данные клинических испытаний).
Более того, мы пытаемся методологию разработки программ (XP) к разработке модели. Здесь слайды на эту тему:
http://www.biouml.org/vc/pdf/Kutumova_Applying_XP_methodology_for_model_...
На практике это пока не применяется, о чем и пишется в статье. Это следующий этап, и не совсем понятно, когда это будет.
бред. если обезьяна нарисует на стене пещеры пациента, да еще попытается лечить по этому рисунку.... у тупорылых "медиков" накоплен недостаточный запас знаний о процессах происходящих в организме. На каждый орган и гормон может быть по десятку взаимоисключающих теорий и гипотез./ простейший тест-вопрос- какой гормон влияет на либидо? в журнале моды "космополитен" ответ известен.А медицине нет/ Поэтому ваш "виртуальный пациент" -это не то что "индивидуальный подход", а совершенно наоборот. Лечение по стандартным протоколам возведенное в абсолют.
и два- необходимость полного сверхдорогостоящего обследования. Регулярного. Выполняемого по единым стандартам на одном оборудовании (иначе будут отличаться как единицы измерения, так и референтные значения. Если у одного пациента взять кровь на какой -нибудь анализ, разделить ее на две части и исследовать в различных лабораториях, то конечный результат будет всегда отличаться ). Что само по себе уже есть недостаток, т.к нет идеальных приборов и методов. И какой -то один метод может привести к системной ошибке при диагностике
По поводу "цифрового двойника" - это ж прямые отсылки к "цифровой экономике", "Индустрии 4.0" и прочим мантрам, что говорит о желании хайпануть и вскочить в вагон к инноваторам)))) А этого, если посыл изначально был не распильный, делать не надо ни в коем случае)))
Собственно для этого и нужно моделирование. Как-то мы работали с Пущино по асцитным опухолям у крыс. Было несколько гипотез, которые в виде текста выглядели вполне логично. Но стоило их перевести в математическую модель, как стало понятно, что работает только одна.
Полностью согласен с Doc_Mike. Он популярно объяснил, почему это не будет работать практически, несмотря на академиков и профессоров в творческом коллективе. Крайне сомнительно получить с нужной точностью все параметры и коэффициенты уравнений в модели. Да и сами уравнения, скорее всего, линейная аппроксимация нелинейных уравнений с переменными во времени коэффициентами.
Но не это главное, изначальная цель - давайте начнём с простого "лечим гипертензию", а потом станем усложнять - ложная! Сама гипертензия может сопровождать другие болезни, и абстрагироваться от них, опуская одни диагностические параметры в пользу других, неверно. Пациент умрёт от диабета, но с нормальным давлением. Лечить надо больного, а не болезнь (©Гиппократ).
Сами проекты такого рода, по моему, вредны. Они вводят в обиход общение не с самим человеком, а с его цифровой моделью. Логичным следующим шагом при вашем подходе будет вживление биочипов для контроля тех самых параметров, по которым работает модель. Иллюзия всемогущества BigData.
А как распил бюджета - отличная тема на многие годы!
Да я не против собственно проекта, и с моей точки зрения, ему надо нормальное финансирование на долгие годы. Потому что даже отрицательный результат в науке тоже результат - другие в этом месте копать не будут. И в любом случае накопится опыт и компетенции работы со сверхсложными медицинскими динамическими моделями.
Другое дело, что на данный момент проект выглядит неподъемным. И помимо вышеизложенного там же еще чисто математическая проблема. Комбинации множества взаимодействующих параметров это же экспотенциальный вычислительный взрыв, факториалы считать (некий аналог см. притчу про скромного индийского мудреца, который попросил положить на первую клетку шахматной доски всего-навсего одно зернышко риса). Плюс каждый параметр наверняка надо обсчитывать по нестандартной S-образной кривой стимул-ответ с выходом на плато и затем падением ответа до нуля из-за десенситизации рецепторов/истощения медиаторов/клеточной энергетики/полиорганной недостаточности и вообще смерти.
Я сам в качестве хобби смастерячил модельку диагностики при множественной патологии. Так вот когда выяснилось, что можно обойти экспотенциальный взрыв, у меня сильно полегчало на душе, и я на радостях по этому случаю даже злоупотребил любимым канадским пивом с одной местечковой пивоварни. Но у меня же статическая система чукча-стайл, чо прям щас вижу, то пою, тупое распознавание образов. А у авторов по определению множественные комбинации параметров в динамике стимул-ответ, у любого суперкомпьютера зубы вспотеют такое считать.
Поэтому разработчикам надо не накачивать свою модель множеством дополнительной информации, а наоборот, безжалостно резать все, что не влияет на конечные ключевые параметры модели. И не лезть в молекулярные дебри до тех пор, пока модель адекватно реагирует на уровне органов/фунциональных систем. Там сложности хватит за счет неизбежного выхода за пределы изолированного АД.
А вообще, на данный момент, насколько понятно из описания, в качестве основной задачи проекта надо ставить отработку системы/методов корреляции модели с реальными пациентами. 7 хорошо обследованных и полторы тысячи неизвестно кого это ни о чем.
В каком-то виде эта проблема есть, но не так страшно.
1) для каждого параметра мы проводим анализ чувствительности модели к его изменениям. Модель показывает, что сравнительно небольшое количество параметров существенно влияют на артериальное давление. Далее мы работаем только с этими параметрами.
2) многие параметры связаны друг с другом и поэтому не явлюятся независимыми. Это и плюс и минус. Минус - нужен специальный алгоритм, чтобы учесть совместное распределение параметров по выборке. Плюс - существенно уменьшается пространство для анализа параметров.
Безжалостно резать - для этого даже есть термин "упрощение модели (model reduction)" и набор математических методов. Смысл этого - берем модель и набор экспериментальных данных, который она должна воспроизводить. Затем при помощи этих методов убираем или объединяем переменные, до тех пор, пока упрощенная модель сможет почти так же хорошо воспроизводить экспериментальные данные.
1) Без этого мы не сможем воспроизвести клинические данные по лечению, поскольку нам нужны конечные молекулярные точки, на которые действует лекарство
2) дальнейшие перспективы - мы хотим в дальнейшем механистически (причинно-следственно) связать модель с генотипом и мутациями конкретного человека. А для этого, чем больше генов/белков в модели - тем лучше. Потому что сейчас такая связь идет за счет поиска корреляций типа признак-мутация.
"...Без этого мы не сможем воспроизвести клинические данные по лечению, поскольку нам нужны конечные молекулярные точки, на которые действует лекарство... дальнейшие перспективы - мы хотим в дальнейшем механистически (причинно-следственно) связать модель с генотипом и мутациями конкретного человека. А для этого, чем больше генов/белков в модели - тем лучше. Потому что сейчас такая связь идет за счет поиска корреляций типа признак-мутация".
Не знаю. Вы идете в молекулярно-генетическую глубину, а можно идти в ширину, добавляя другие функциональные системы, кроме регуляции АД.
Практика тех же клинических испытаний показывает, что гомогенизация выборок за счет критериев включения/исключения пациентов по сопутствующей патологии, т.е. по другим сопутствующим системам, кроме изучаемой, в вашем случае АД, вполне себя оправдывает. И при доведении препаратов до клиники уже не заморачиваются молекулярными мишенями, а смотрят, что с пациентом на макроуровне. У вас тут пустота из 7 человек.
Молекулярные механизмы на крысках изучают до того, как препарат вводить в пациента.
В общем, дерзайте, и хорошего финансирования вам.
И еще один вопрос - а откуда такое доверие результатам экспериментальных и клинических данных?
Как сформулировал Ганс Селье "В теорию не верит никто, кроме того, кто ее выдумал. В эксперимент верят все, кроме того, кто его проводил". Недаром появился такой жанр медицинских исследований, как метаанализ. А ведь еще бывает заведомая залипуха для отчетности.
Как вы отбираете исследования для включения в модель?
Вопрос - что такое нужная точность?
Во многих случаях, ошибка в 20% вполне допустима, и существенно не повлияет на результат.
Это один из парадоксов биологических систем:
- с одной стороны робастность - т.е. можно в 10 раз изменить значение какого-то параметра, а другие параметры почти не изменятся. Один из механизмов, ответственных за это - это регуляция с отрицательной обратной связью. На этом построен гомеостаз в организме.
- с другой - ультрачуствительность - т.е. незначительное изменение одного параметра может быть усилено в тысячи и даже миллионы раз (например, глаз человека теоретически может зафиксировать даже 1 фотон). Это строится на нескольких каскадах усиления сигнала.
Артериальное давление - это очень важный параметр организма, поэтому здесь очень важен гомеостаз, и поэтому, многие параметры не оказывают существенного влияния.
Может вам с этими ребятами скооперироваться?
https://tass.ru/v-strane/6007781
В целом задумка очень крутая. Уровень проработки идеи впечатляет.