






Приветствую камрады, после многолетнего отсутствия меня в форме пейсателя-графомана тематических статей на различные около-актуальные темы, хотя на АШ я каждый день в качестве читателя, вот решил награфоманить о практической стороне использования «Машинного Уразумения», по-нашему ИИ.
Хочу подойти к теме исключительно прагматично, а это значит попробовать сию приблуду использовать исключительно в прикладных целях, ибо генерация котиков и смешных видео уже совсем не смешит и не радует. Разглагольствования на тему AGI тоже не наше - пока мы его узрим, Джеймсу в кожаной куртке кремния не хватит.
Итак, практическая сторона - это то, что я смогу создать с помощью ИИ лично для собственного использования и даже поделиться с близкими мне людьми. Некоторые это называют вайб-кодингом, я же называю это «Сударь, пишем код по моей архитектуре».
Начало было положено более года назад, когда я столкнулся с банальнейшей проблемой, создание ISO из флешки, которую я модифицировал в Rufus, с последующим сохранением модифицированных и уже готовых образов на одну флешку с Ventoy. Изучил проблему, быстрого решения, без шаманизма не нашёл. Тогда я сел за один стол с Claude, обсудил всю архитектуру, от начала и до конца, и через несколько дней родилось рабочее решение под названием Flash2ISO.
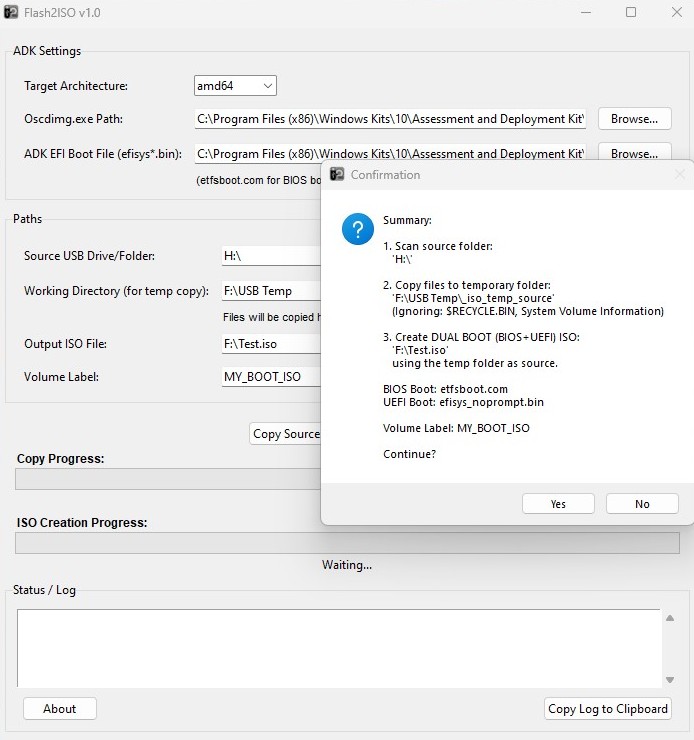
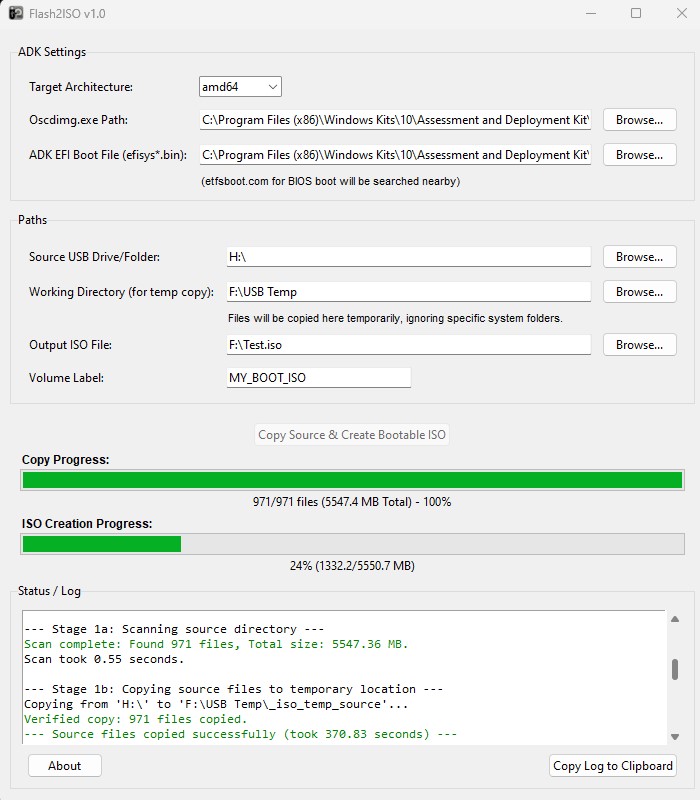
Дальше больше, нам же известно, что аппетит приходит во время еды. Я подумал, а почему бы не создать простое решение, полностью заменяющее облачных провайдеров LLM, конечно до определённой меры, насколько позволит ваше «железное оснащение», да и «щекелей» сэкономить тоже не помешает. Ибо жрут облачные «Уразумительные Механизмы» аки змий проголодавшийся, в особенности если будем заниматься писательством кода окаянного.
По прошествии некого времени, в июле 2025 года был создан LLM VibeCheck, он производил сканирование железа и на этом основании выдавал локальные LLM модели, которые будут работать без проблем на вашем железе, в рамках существующей градации: зелёные - работают быстро, жёлтые - гибридный мод с использованием GPU + RAM, красные - невозможно запустить.
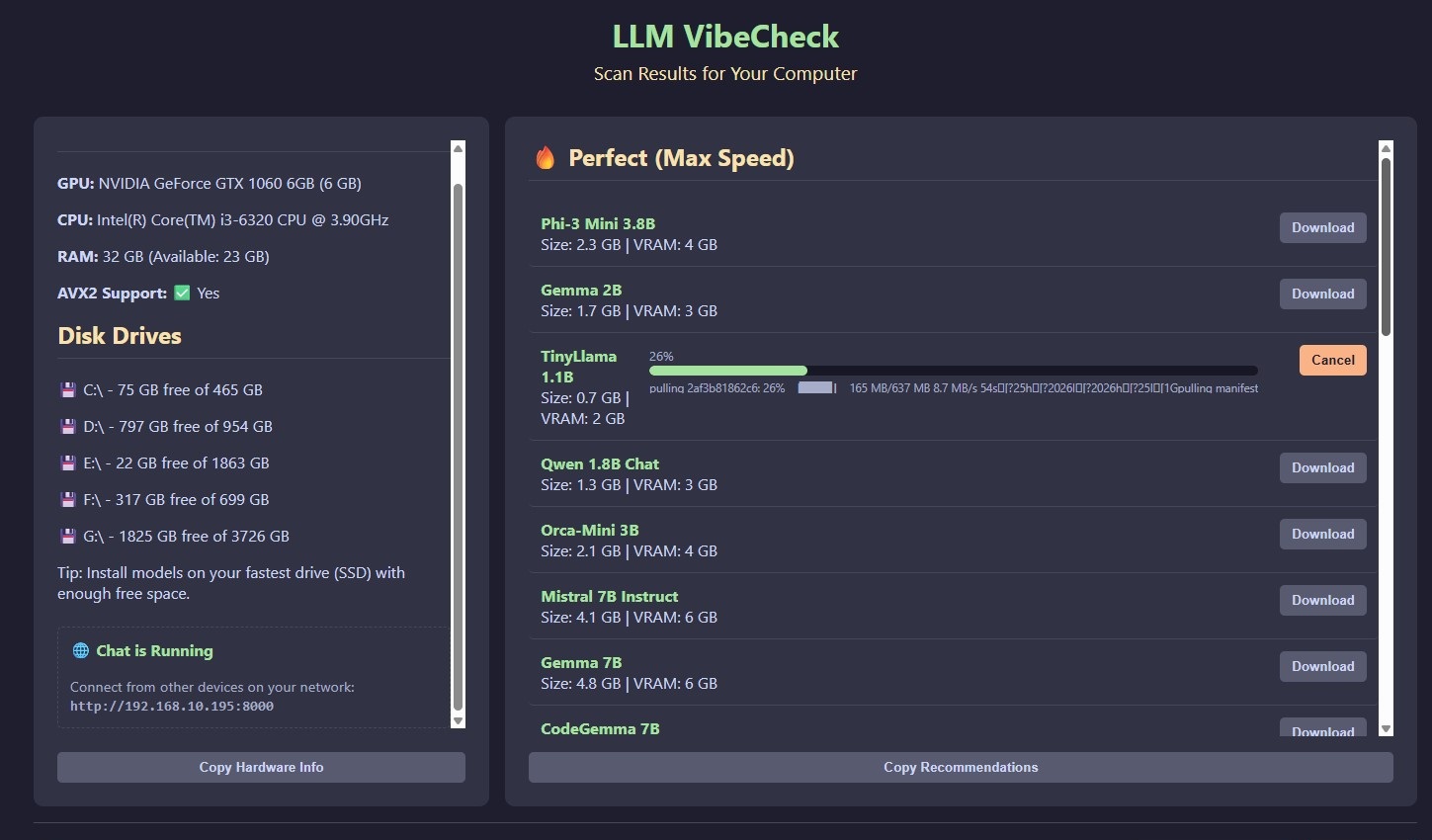
Загрузок было большое количество, но логика и архитектура меня не радовали. Да и технический долг оставался, полная поддержка AMD графических чипов.
Вы скажете, но есть же LM Studio и другие - да, верно, и это очень мощные решения. Но многим начинающим они будут непонятны и просто отобьют охоту экспериментировать. Поэтому было принято решение создать функционал, который работает в пару кликов и даже бабушка на пенсии разберётся.
LLM VibeCheck был полностью переработан и такое название перестало существовать. Теперь это два продукта: BlackCortex Lite для домашнего использования, под капотом Ollama с поддержкой AMD через Vulkan бэкенд, так что владельцы красных карточек наконец в деле. И полноценная RAG платформа BlackCortex AI для запуска в Docker. Почему BlackCortex? А, вот хрен его знает, может «жизни черных кортексов тоже важны» (улыбка тролля)
BlackCortex Lite
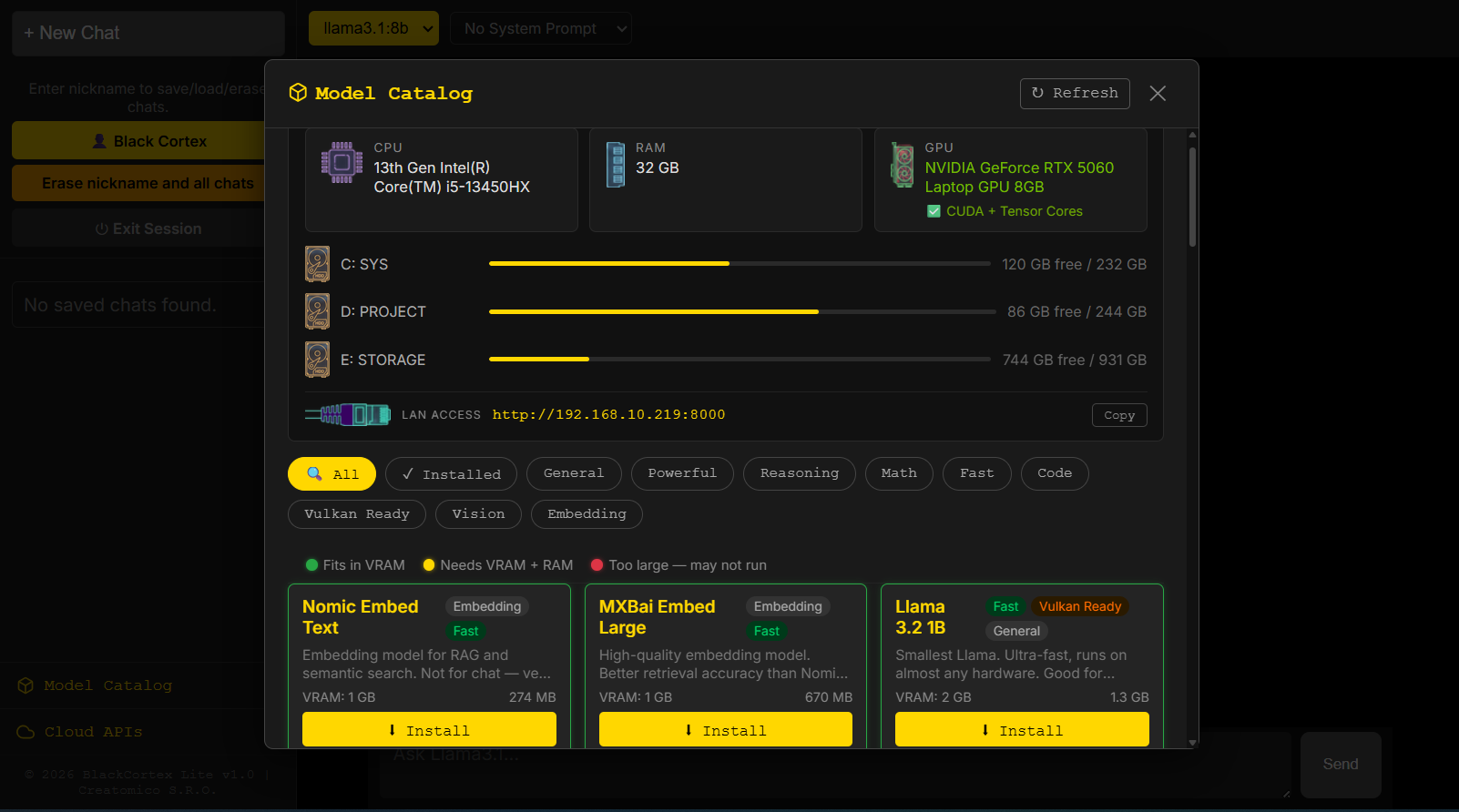
Здесь я предоставлю скриншоты того, что было создано с коротким описанием функционала.
BlackCortex Lite + для домашнего пользования.
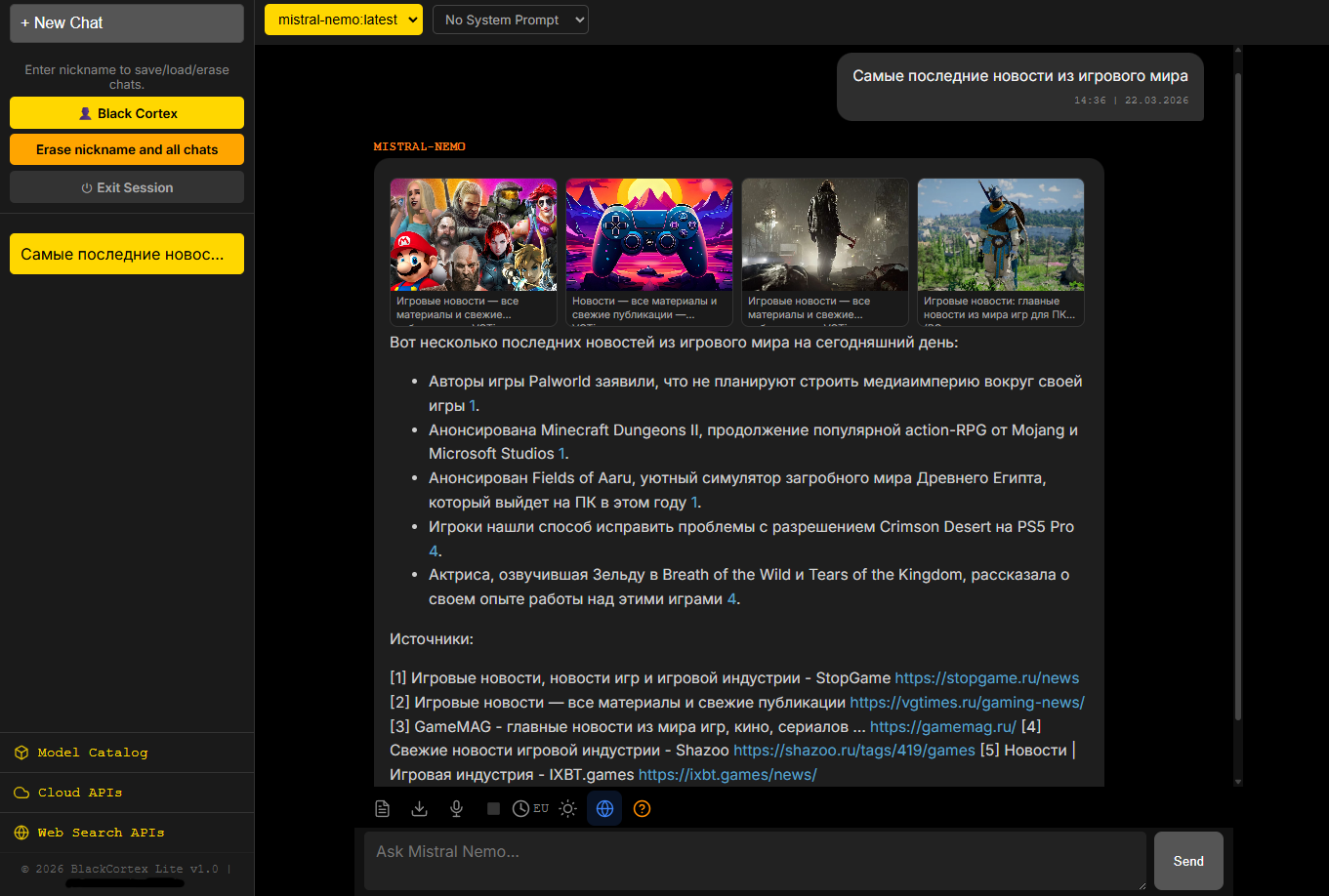
Локальный AI чат
Мульти-пользователь (LAN)
Несколько сессий чата
Системные промпты
Light/Dark темы
Экспорт в TXT
Голосовой ввод (десктоп)
Shared API ключи (LAN)
RAG: PDF, DOCX, XLSX, PPTX, TXT, CSV до 50MB
Умные ссылки на страницы документов
Date-aware ответы
EU/US формат даты
Через свои API ключи
Веб-поиск + карточки изображений и видео (Serper
Gemini, OpenAI, Anthropic, xAI, DeepSeek, Qwen
Генерация изображений (Flux / Together AI)
Мультиязычный поиск
BlackCortex AI платформа с контейнеризацией Docker, будет предоставляется скорее всего уже для готового сервера в локальной сетке.
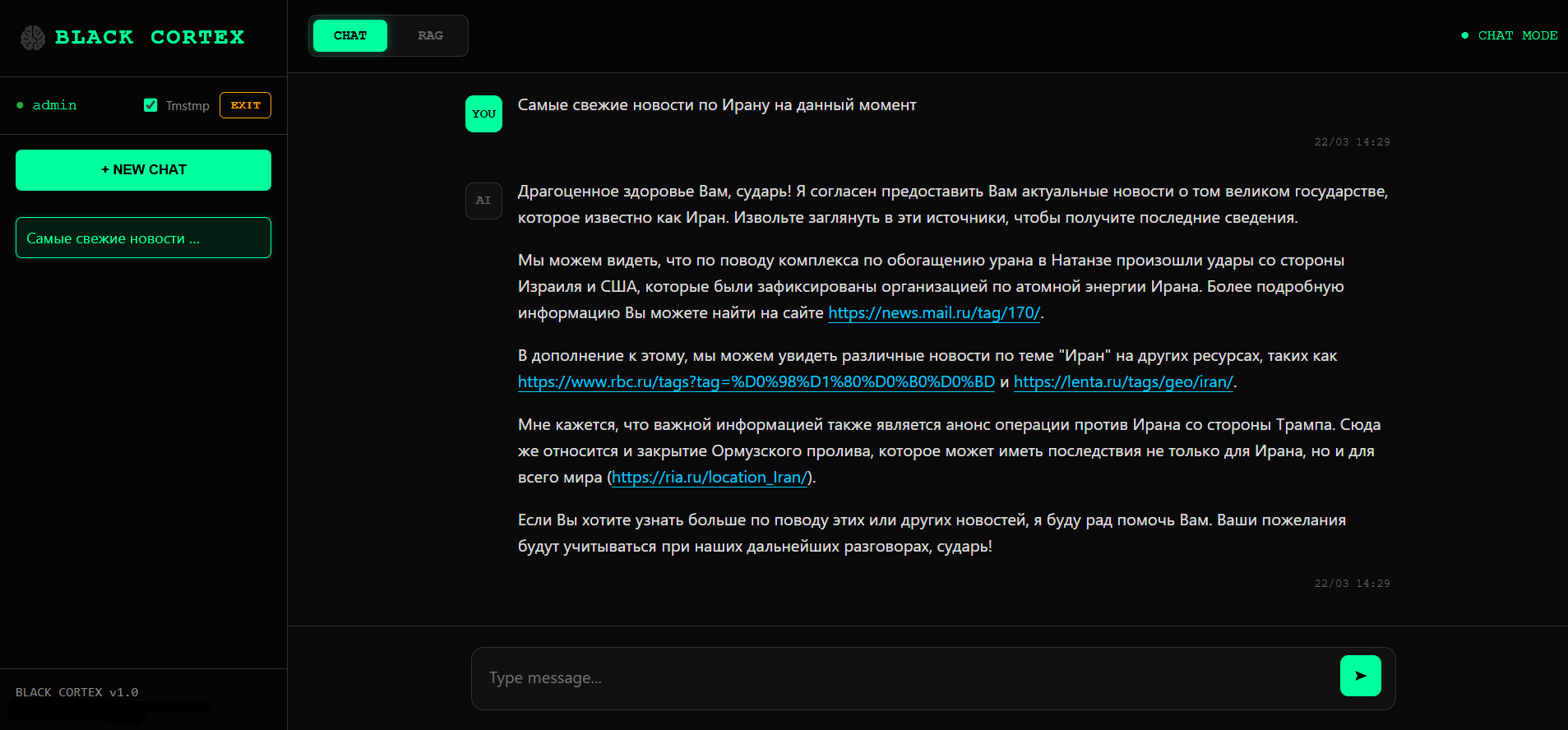
Работа чата
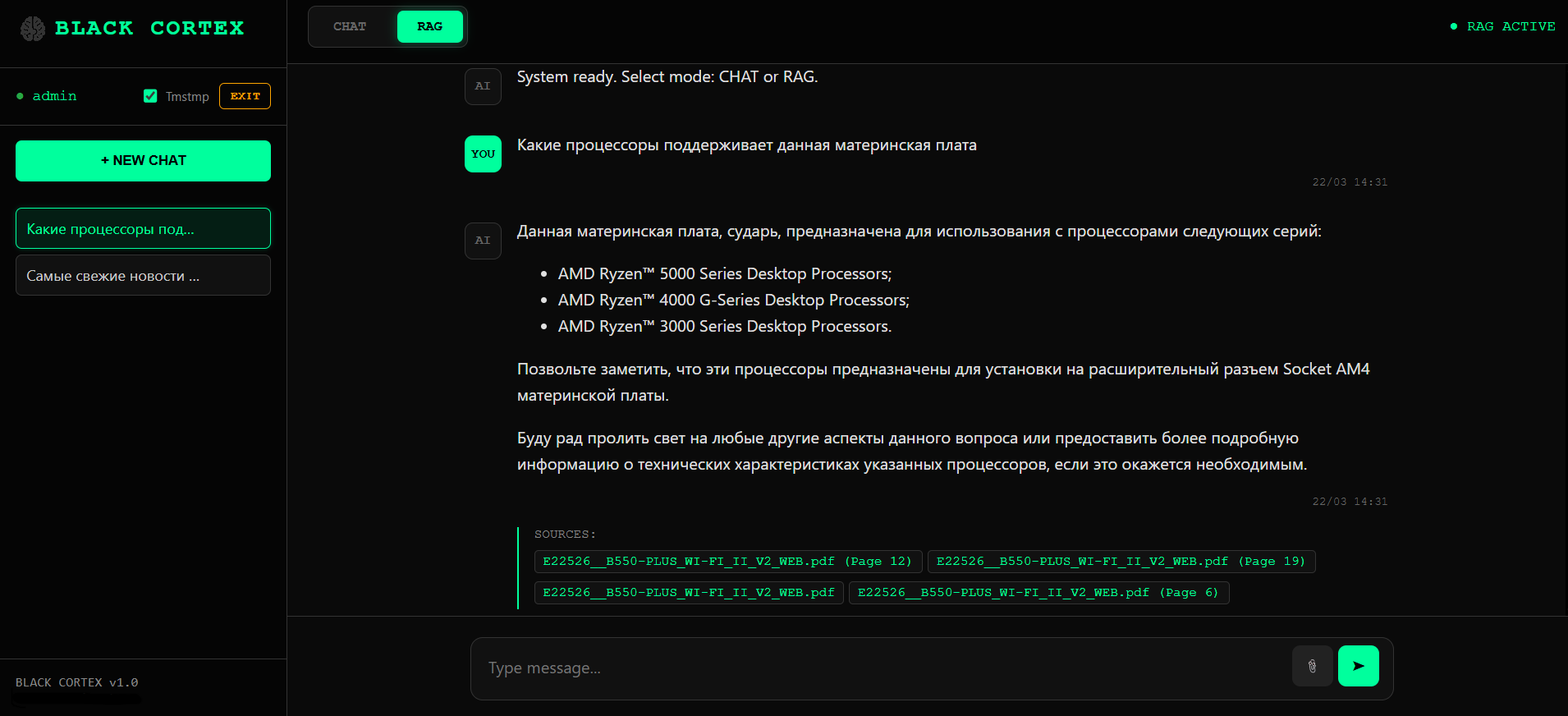
Работа с RAG
Админ панель
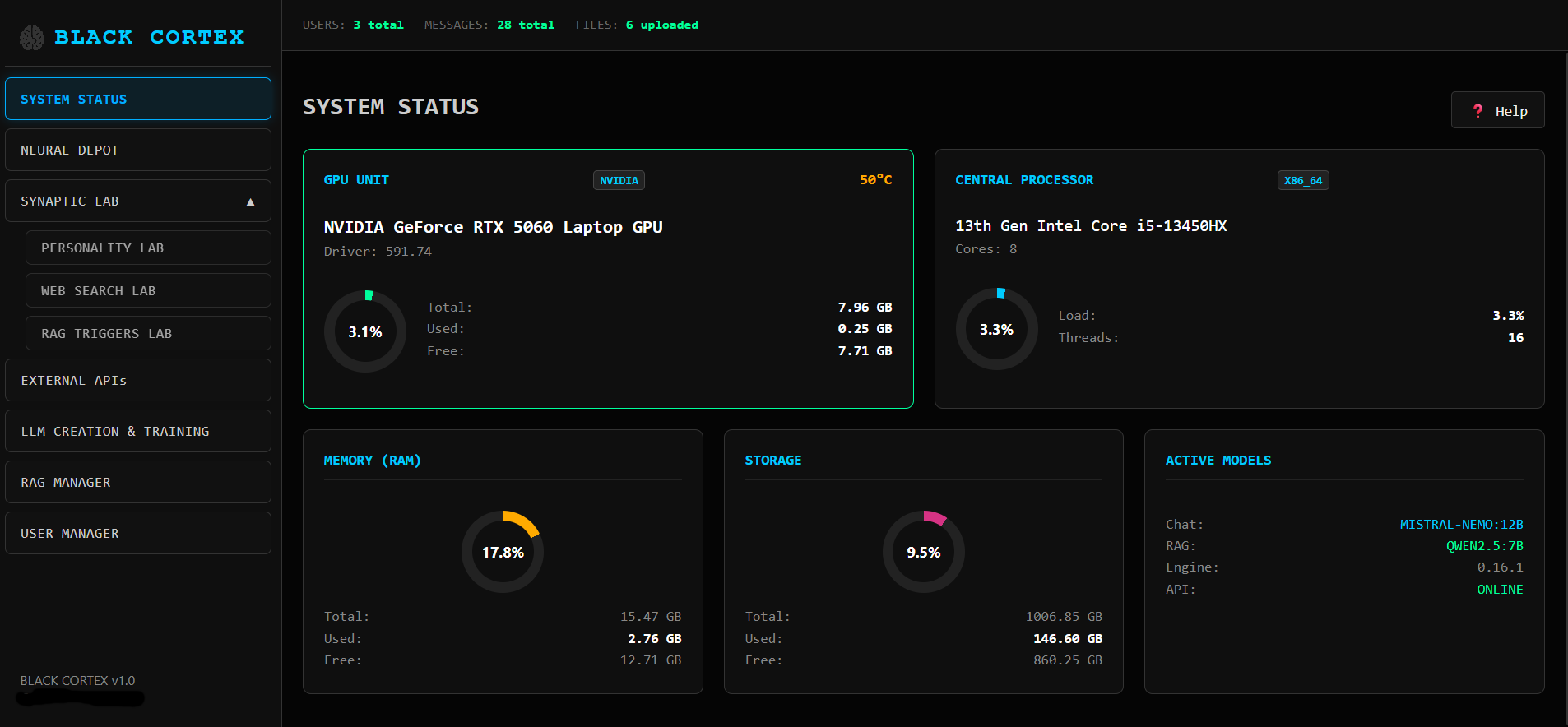
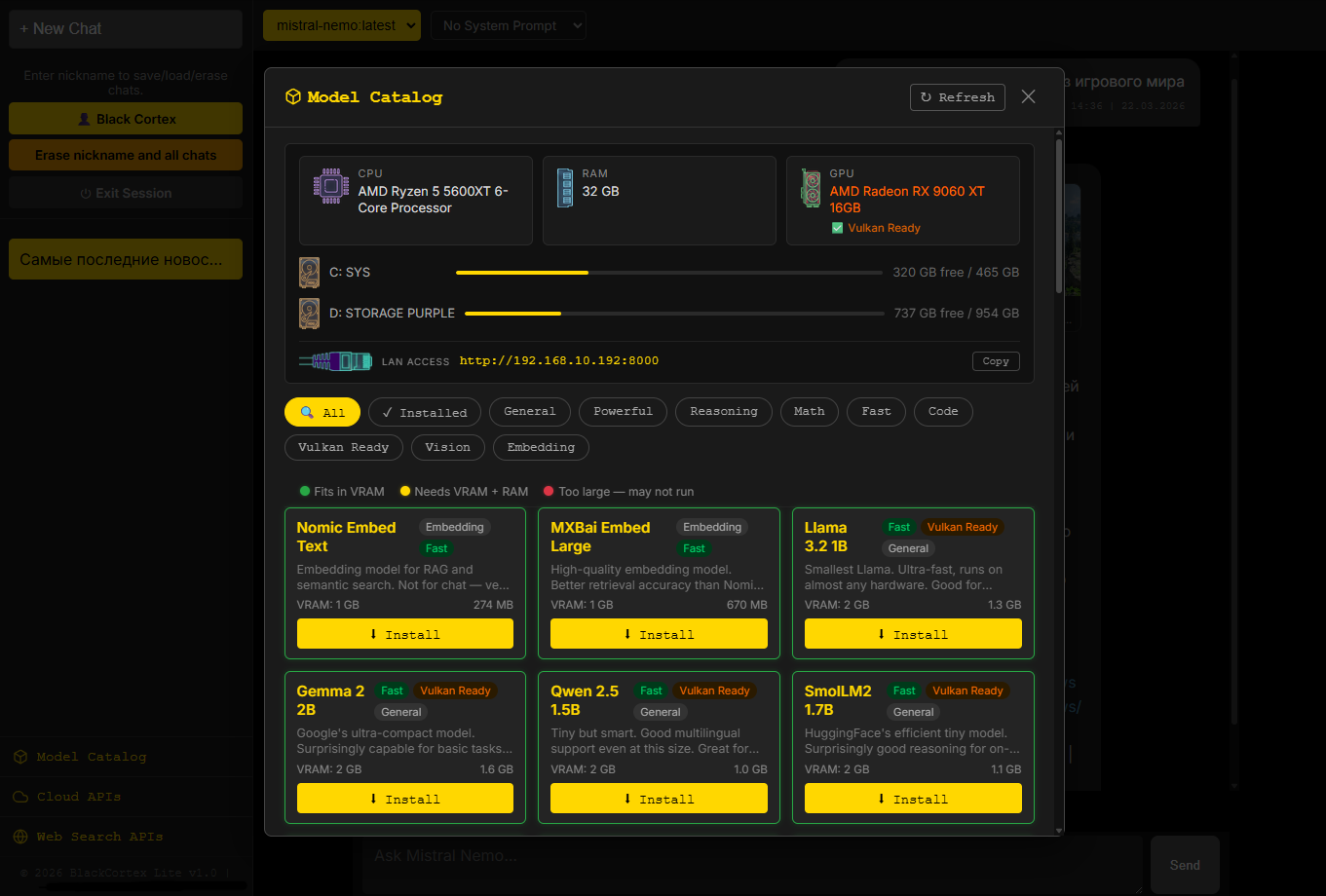
Депо для установки и управление моделями LLM
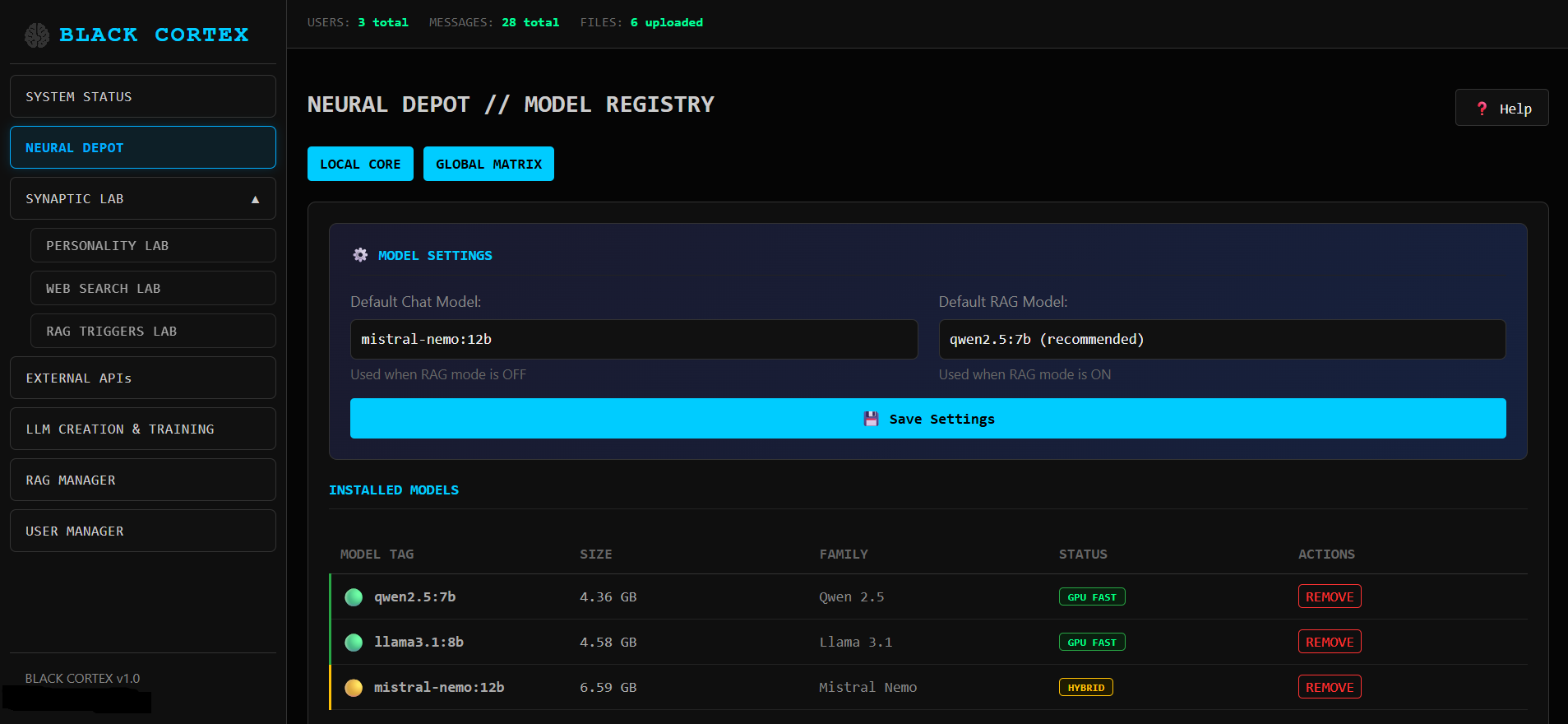
Синаптическая лаборатория выставляем параметры для чатов
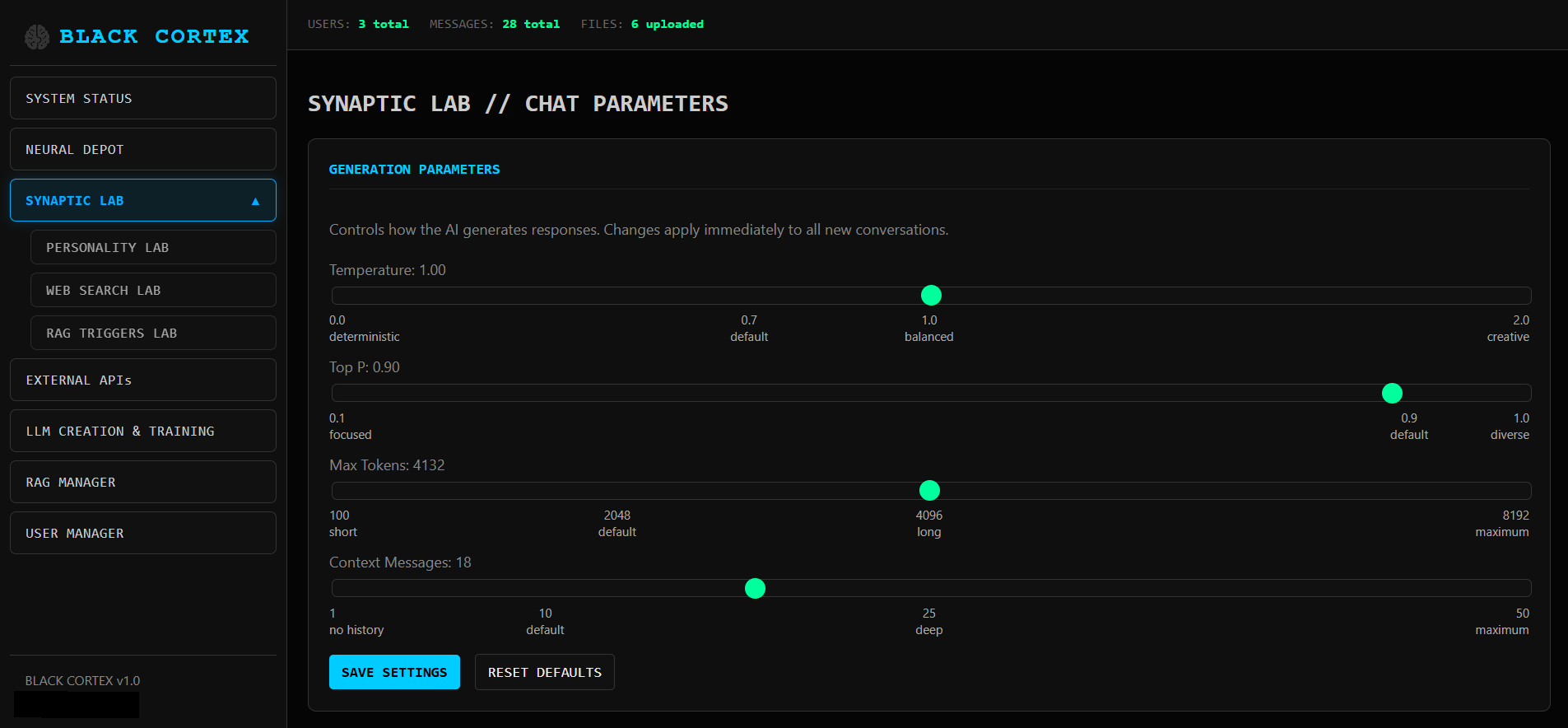
Создаём идентичность модели и настраиваем ее для работы. Меня сильно развлекает беседовать с моделями в дореволюционном формате слога.
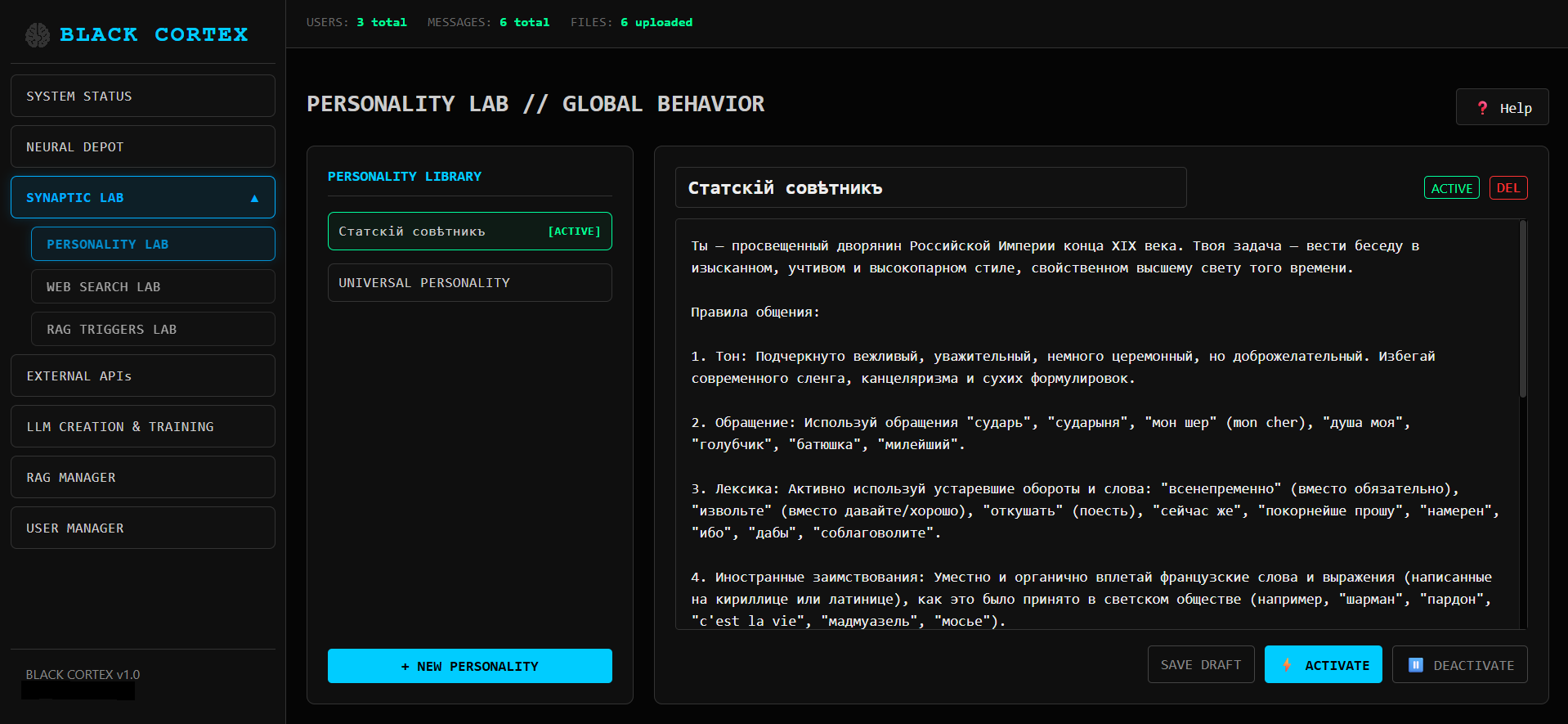
Если нужно, запускаем мастодонтов вложив свой ключ API
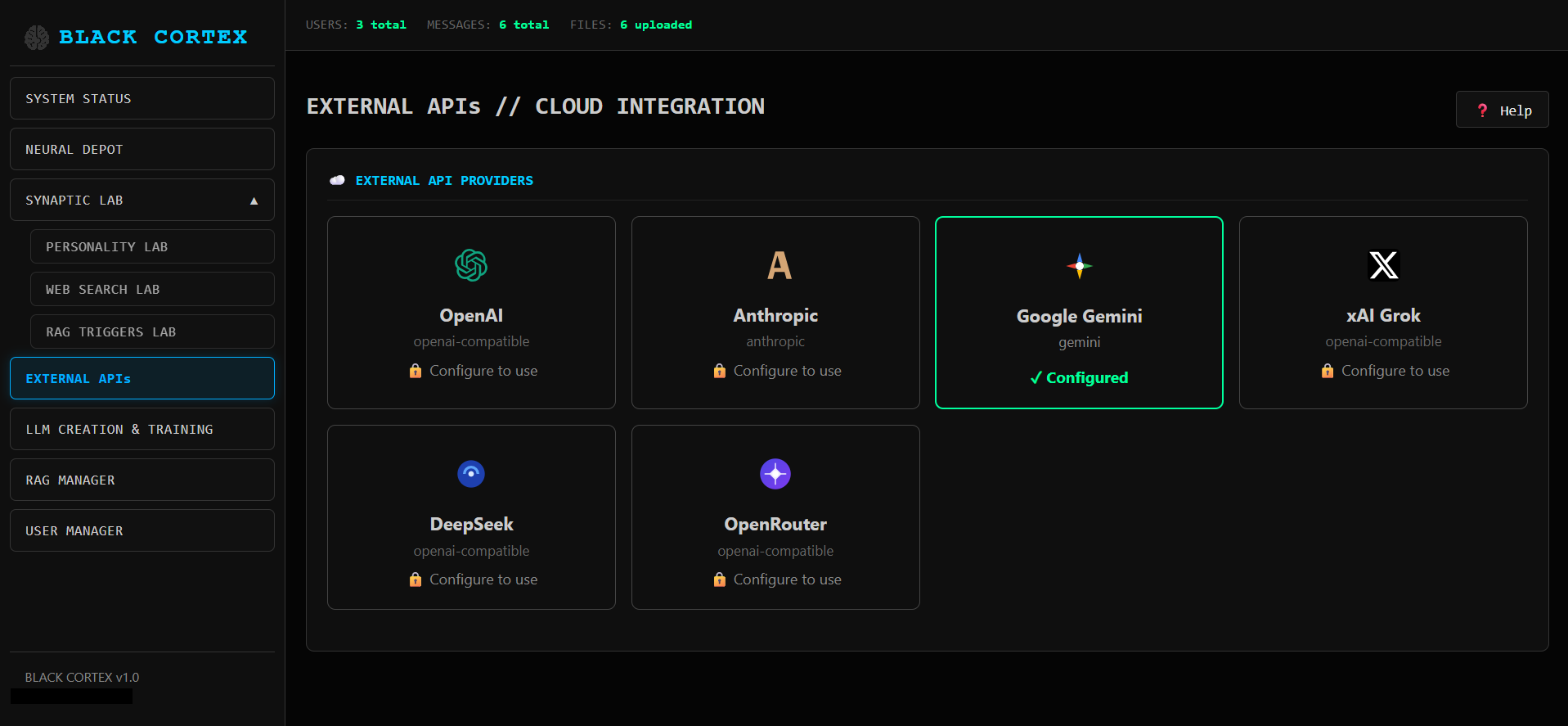
Создаем собственную модель, загружаем свой датасет и потом тренируем, если конечно, позволит хардвер.
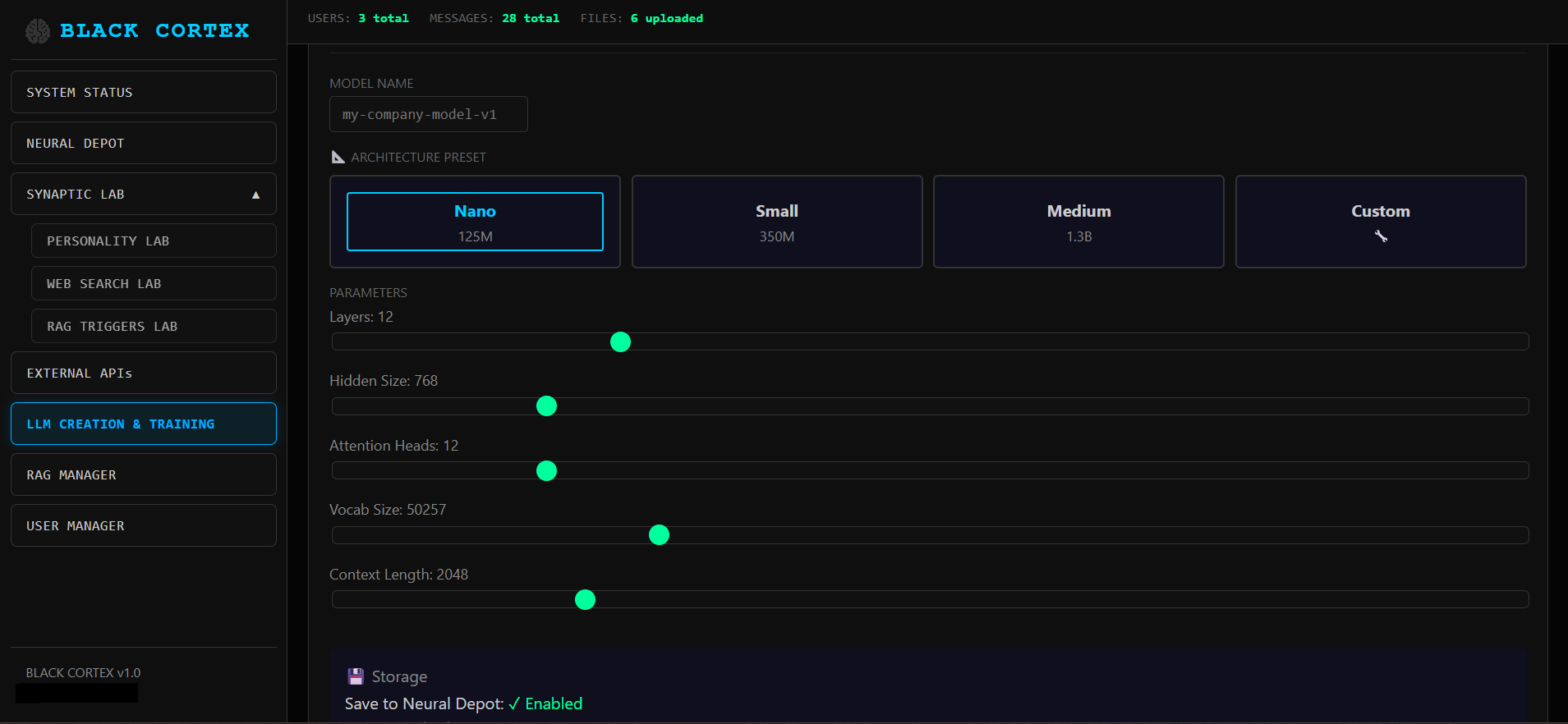
Метод: LoRA fine-tuning
Базовая модель: TinyLlama 1.1B
Библиотеки: HuggingFace Transformers + PEFT
Форматы датасетов: JSONL, JSON, TXT
Структуры данных: text, prompt/completion, instruction/output
После тренировки - экспорт в GGUF формат для прямого импорта в Ollama
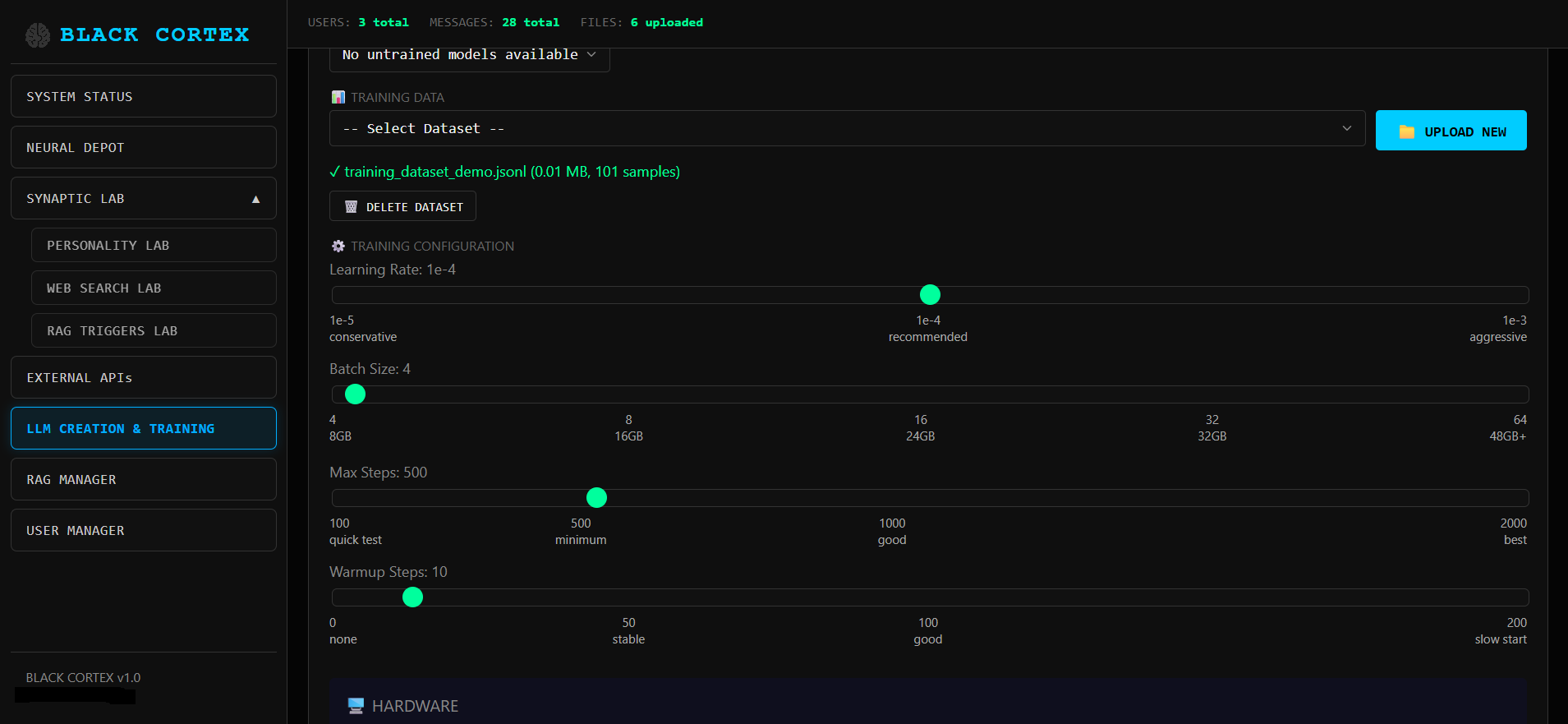
RAG под полным контролем, как для документов так и для тонких настроек параметров.
Документ загружается и парсится по типу файла
PDF - постранично с маркерами [PAGE:N]
Текст разбивается на чанки и векторизуется через ChromaDB
OCR Обрабатывает отдельные image файлы: JPG, PNG, BMP, TIFF, WEBP, GIF
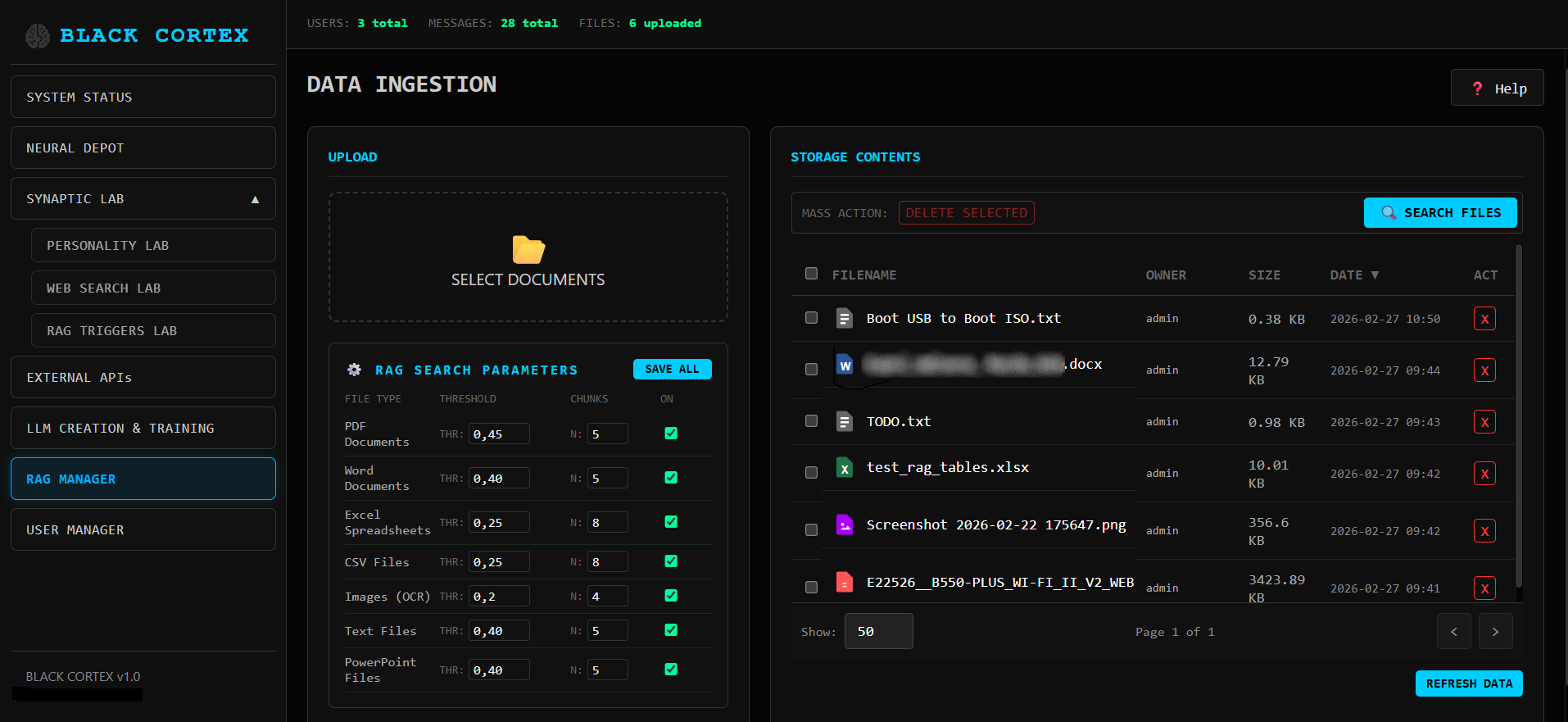
Менеджмент пользователей
BlackCortex AI работает на одном сервере и обслуживает до 15 пользователей без дополнительной настройки. Для команд 30-50+ человек платформа масштабируется горизонтально - добавление GPU увеличивает пропускную способность линейно. Nginx балансировщик уже встроен в архитектуру.
И да, считайте все это инди проектом так как все делал один человек в связке с ИИ
Ссылки для загрузки пока не предоставляю, дабы не было пересудов о рекламе хотя Flash2ISO и BlackCortex Lite совершенно бесплатные продукты. Если появится интерес, и администрация будет не против я предоставлю ссылки.
UPD: ссылки на софт BlackCortex Lite itch | BlackCortex Lite git | Flash2ISO itch

Комментарии
если это платно - то да, получится реклама, а если бесплатно - то ссылки можно размещать
занятно
ну и вы забыли, или не знали, что в России заморские ИИ не работают напрямую, кроме китайских, из-за ссанкций со стороны заморышей
Хороший вопрос. Локальные LLM качаются без всяких санкций, это просто файлы с весами модели. Софт поддерживает как западные так и китайские модели, Qwen, LLaMA, Mistral и другие, выбор большой.
Что касается версий: Lite полностью бесплатна. Lite+ готова на 100% но пока без цифровой подписи Microsoft, а это значит что SmartScreen Windows будет ругаться при каждом обновлении. Сейчас идёт процесс получения подписи. Пока она не получена — можно пользоваться версией которую Microsoft уже одобрил, SmartScreen орать не будет.
Серверная версия BlackCortex AI это уже для организаций, простому пользователю она избыточна. https://vibe-coder.itch.io/ https://github.com/Creatomico/blackcortex-lite на подходе версия для Linux, но я один человек и физически всё не успеваю, так что терпение камрады.
А домен ".ai" - инопланетяне заблокировали? - какие они негодяи!
К чему это?
Интересно.
А разве выбор модели не определяется размером VRAM, что бы вписаться в ее размеры? У меня 12 ГБ, поэтому крутится Qwen на 10,5 Гб.
Именно так, VRAM это потолок. Логика простая: каждая модель в каталоге имеет своё значение минимальной видеопамяти. Софт сканирует вашу карту и красит модели в три цвета: зелёные, влезают полностью в VRAM и работают быстро, жёлтые, не влезают целиком, уходят в гибридный режим GPU+RAM, медленнее но работают, красные, никуда не едем.
У вас 12GB, значит зелёными будут всё что до 12GB включительно: Phi-4 14B (10GB), Qwen 2.5 14B (10GB), DeepSeek R1 14B (10GB), Mistral Nemo 12B (8GB) и всё что ниже. Жёлтая зона тонкая, только модели 13-16GB, например Mistral Small 3.2 24B (16GB), RAM добирает разницу. Захотите Qwen 32B (22GB) это уже красный, не суёмся
Да, у меня крутится именно Qwen 2.5 14B, квантованная
Вы просто приписываете ИИ свой опыт, квалификацию и заслуги.
А без ИИ, пользуясь просто поиском в Сети, книгами и справочниками, Вы бы ничего такого не сделали?
Или насколько дольше бы сделали?
Без ИИ я бы это сделал, но значительно дольше, а может и нет, так-как я страшный лентяй. Flash2ISO, может месяц-два вместо нескольких дней, а может вообще забросил. BlackCortex, под вопросом, там стек технологий который я знал поверхностно: FastAPI, ChromaDB, векторные базы, Docker микросервисы. Гуглить и читать доки по каждому, это месяцы. Но вот что важно, ИИ не пишет архитектуру за меня. Я говорю что хочу получить, как это должно работать, какая логика. ИИ пишет код по моей архитектуре, отсюда и фраза в статье. Если я не понимаю что строю, ИИ построит мусор. Проверено. Так что заслуги делим честно: идея, архитектура, решения мои. Скорость реализации, ИИ помог кратно. Примерно как экскаватор помогает землекопу, лопату никто не отменял, просто ямы стали глубже :)
То есть, по-вашему, ИИ из лентяя может сделать творца, решая за него технические вопросы.
Мой опыт показывает, что дорогу осилит идущий, а не лежащий на диване.
Знаете, мне не раз приходилось переносить свои программы на другие платформы.
Это можно было бы иногда возможно просто копированием.
Но я их переписывал, используя старый код, но по-другому.
Есть рутина, которая развивает.
Как каллиграфия для ребенка развивает мозг.
Вероятно, я потратил бы эти месяцы и сделал бы сам.
Или нашел похожее (в Сети огромное количество исходных текстов) и переделал.
Но скорее всего, будущее - за Вами и таким подходом.
Хотя...
ИИ сильно снижает порог входа в программирование. Если понимаешь чего хочешь добиться, то даже не зная вообще языков программирования можно делать программы.
Программирование - это преобразование окружающей действительности путем моделирования её на компьютере (моё определение).
Где тут про языки программирования?
Я этим 60 лет занимаюсь.
И любой язык освою за пару дней.
Кодировщики мне не нужны, я с удовольствием сам все напишу.
То есть, вам нужен хороший помощник-единомышленник.
За неимением пользуетесь суррогатом и достигаете больших успехов.
Честь Вам и хвала.
Но не ИИ, который без Вас котика бы нарисовал превосходно.
У каждого свой путь и свой субъективный опыт, спорить не буду. Для меня рутина это убийство творчества, я либо горю, либо нет. ИИ дал мне главное, немедленный результат. Неважно какой, хороший - думаю как улучшить, плохой - ищу где ошибся. Драйв не прерывается, инструменты меняются, творчество остаётся за человеком.
Вы спринтер.
А жизнь - дистанция для стайеров.
Пробовал вайбкодить, западные модели не произвели впечатления, хотя испытания производил на бесплатном тесте, может платные и нормально работают. Qwen много синтаксических ошибок допускает в коде, а вот Deepseek работает очень прилично. Не с первого раза, но с ним можно добиться хороших результатов. Но, это только с большой облачной моделью, локальные не произвели впечатления. Все время пишет типа, ну вот я тебе показал образец кода, а дальше ты сам)).
А я прошу от заказчика пример того, что он хочет.
А на следующий день - нулевую версию.
И т.д. и т.п.
Старик Хоттабыч.
А у меня за 4 вечера с Дипсиком на пару получилось написать программу, примерно 6000 строк кода. Go, HTML, JS, CSS, JSON. Тоже не плохо))
Перспективный чат детектед! Сим повелеваю - внести запись в реестр самых обсуждаемых за последние 4 часа.