





Методика анализа описана здесь:
Авторский инвариант русских литературных текстов
Анализ проводится в два этапа (можно объединить в bat файле).
1. author_invariant.py <filename>.txt // Исходный файл в кодировке UTF-8 (переделывается в Notepad++при необходимости), выходной файл <filename>.dat
2. invariant_plotter.py <filename>.dat // На выходе графики в png
Листинги в конце.
ПРИМЕРЫ // Булгаков, Ильф и Петров.
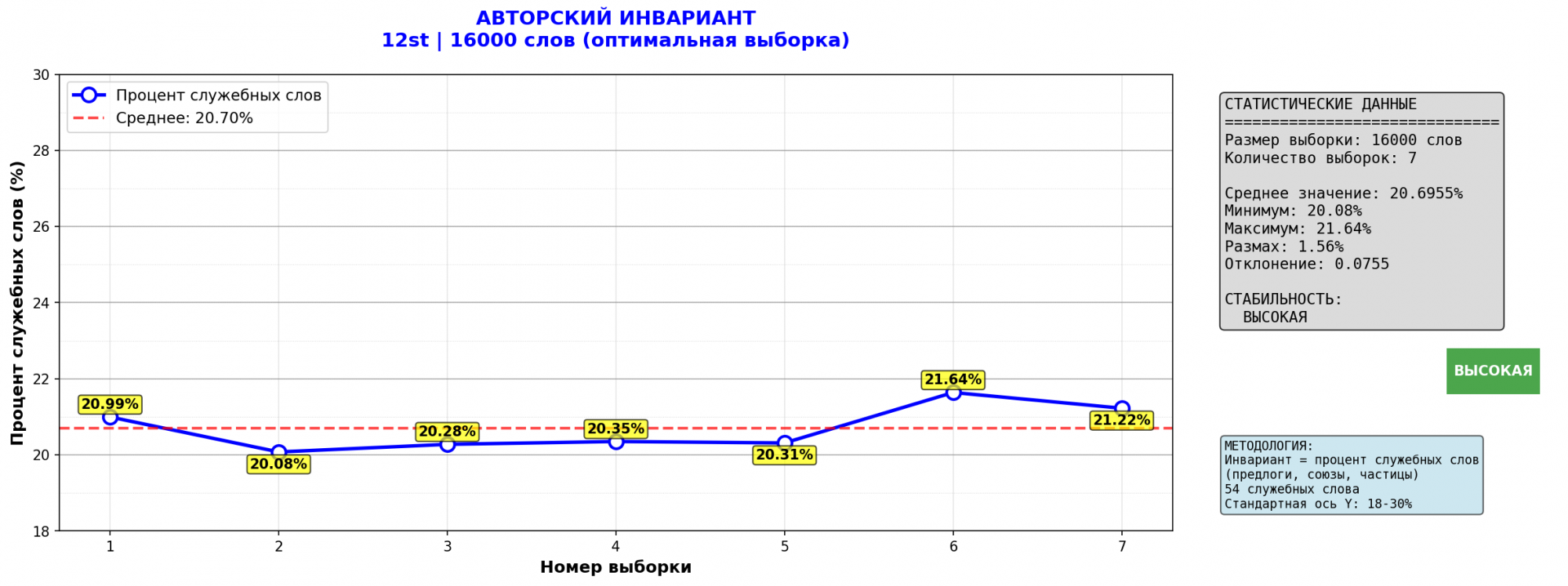
1. 12 стульев
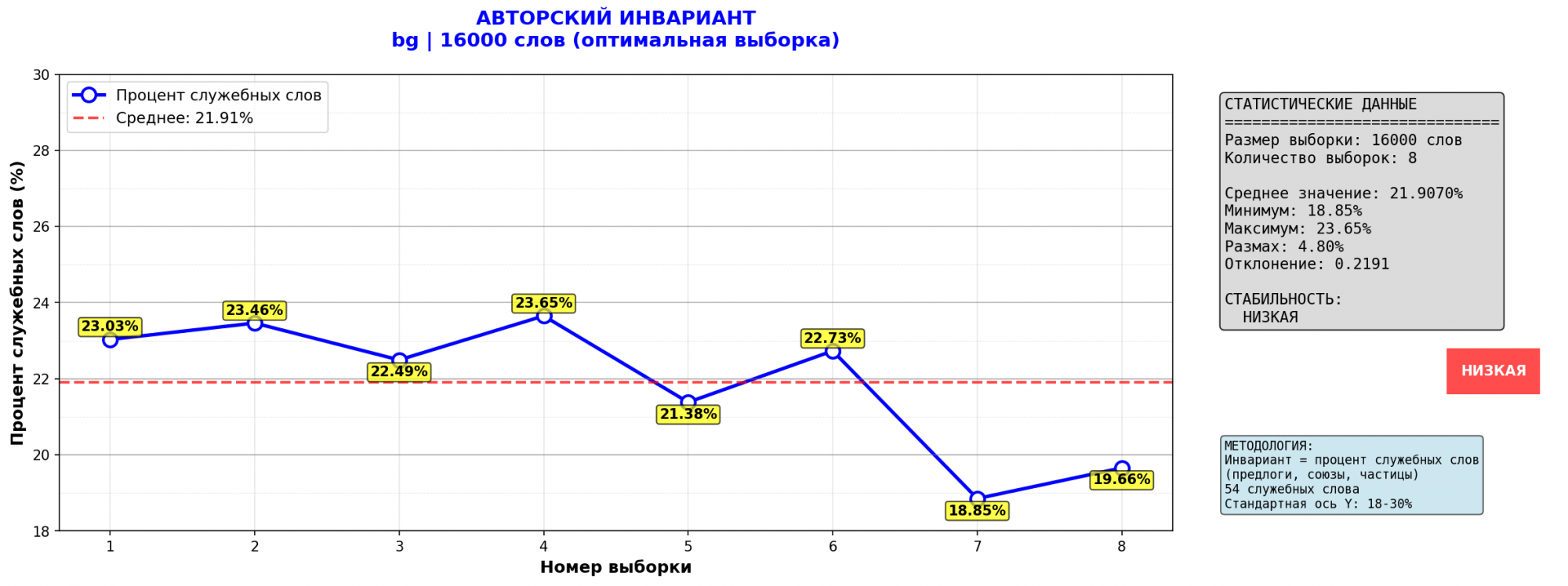
2. Белая Гвардия
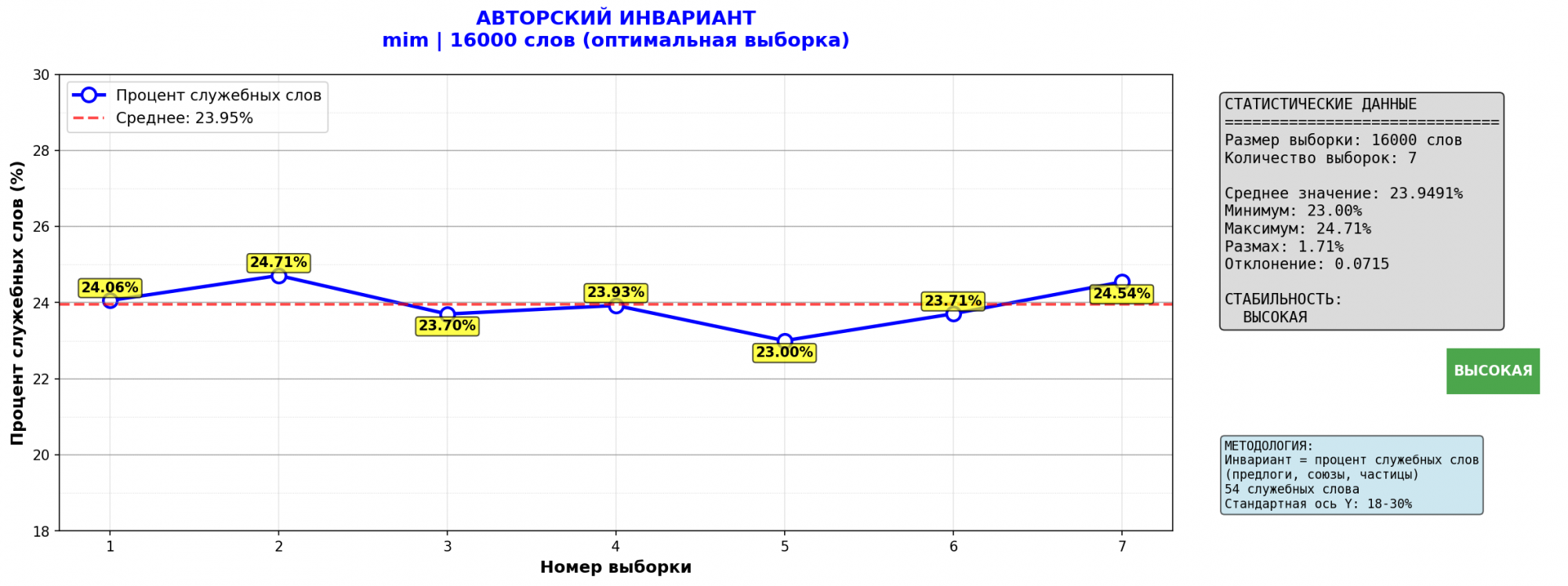
3. Мастер и Маргарита
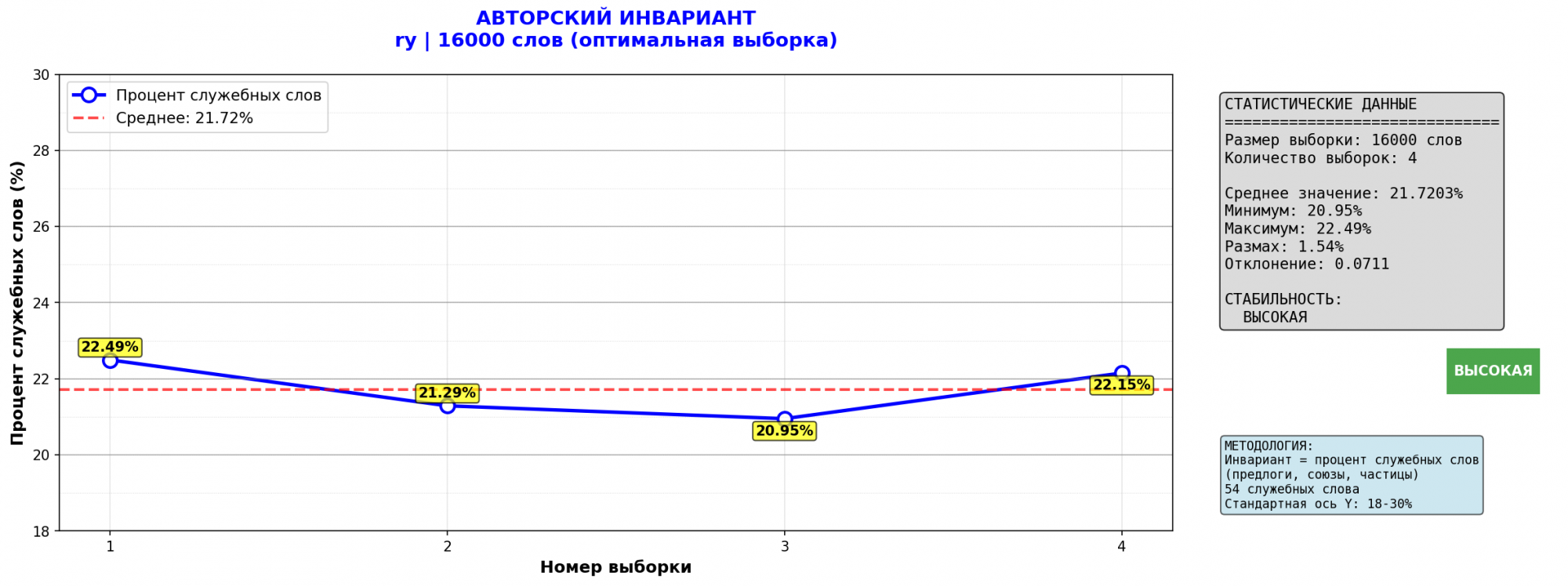
4. Роковые яйца
5. Собачье сердце
6. Том 1. Дьяволиада
7. Золотой теленок
ECHO ON
chcp 65001 > nul
author_invariant.py zt.txt
REM Для анализа одного автора:
REM python author_invariant.py tolstoy.txt
REM Для анализа с другим размером выборки:
REM python author_invariant.py tolstoy.txt 8000
PAUSE
import sys
import re
from collections import defaultdict
import json
import os
# Список служебных слов (54 слова)
SERVICE_WORDS = {
# Предлоги (24)
'в', 'на', 'с', 'за', 'к', 'по', 'из', 'у', 'от', 'для', 'во', 'без',
'до', 'о', 'через', 'со', 'при', 'про', 'об', 'ко', 'над', 'из-за',
'из-под', 'под',
# Союзы (14)
'и', 'что', 'но', 'а', 'да', 'хотя', 'когда', 'чтобы', 'если', 'тоже',
'или', 'то есть', 'зато', 'будто',
# Частицы (16)
'не', 'как', 'же', 'даже', 'бы', 'ли', 'только', 'вот', 'то', 'ни',
'лишь', 'ведь', 'вон', 'нибудь', 'уже', 'либо'
}
# Учитываем, что некоторые служебные слова могут быть частью других слов
# Например, "не" в слове "небо" - не частица
# Для простоты будем искать точные совпадения слов
def clean_text(text):
"""Очистка текста: оставляем только буквы, пробелы и основные знаки препинания"""
# Заменяем переносы строк и табуляции на пробелы
text = text.replace('\n', ' ').replace('\r', ' ').replace('\t', ' ')
# Убираем лишние пробелы
text = ' '.join(text.split())
return text.lower() # Приводим к нижнему регистру
def split_into_words(text):
"""Разбиваем текст на слова"""
# Используем регулярное выражение для выделения слов
# Слово - последовательность букв и дефисов
words = re.findall(r'[а-яёa-z-]+', text, re.IGNORECASE)
return words
def is_service_word(word):
"""Проверяем, является ли слово служебным"""
# Приводим к нижнему регистру для сравнения
word_lower = word.lower()
# Проверяем точное совпадение
if word_lower in SERVICE_WORDS:
return True
# Для составных союзов типа "то есть" нужно особое внимание
# В нашем случае они уже учтены в списке SERVICE_WORDS как отдельные слова
# Но при разбиении текста "то есть" станет двумя словами
# Для простоты будем проверять только одиночные слова
return False
def calculate_samples(text, sample_size=16000):
"""Разбиваем текст на выборки заданного размера"""
words = split_into_words(text)
total_words = len(words)
if total_words < sample_size:
print(f"Предупреждение: Текст содержит только {total_words} слов, что меньше минимального размера выборки ({sample_size})")
return []
samples = []
num_samples = total_words // sample_size
for i in range(num_samples):
start_idx = i * sample_size
end_idx = start_idx + sample_size
sample_words = words[start_idx:end_idx]
samples.append(sample_words)
return samples
def analyze_sample(sample_words):
"""Анализируем одну выборку"""
total_words = len(sample_words)
if total_words == 0:
return 0.0
service_count = 0
for word in sample_words:
if is_service_word(word):
service_count += 1
# Процент служебных слов
percentage = (service_count / total_words) * 100.0
return percentage
def main():
if len(sys.argv) < 2:
print("Использование: python author_invariant.py <input_file> [sample_size]")
print("Пример: python author_invariant.py tolstoy.txt 16000")
sys.exit(1)
input_file = sys.argv[1]
sample_size = 16000 # значение по умолчанию
if len(sys.argv) > 2:
try:
sample_size = int(sys.argv[2])
except ValueError:
print(f"Предупреждение: Некорректный размер выборки '{sys.argv[2]}'. Используется значение по умолчанию: {sample_size}")
# Проверяем существование файла
if not os.path.exists(input_file):
print(f"Ошибка: Файл '{input_file}' не найден")
sys.exit(1)
# Читаем текст из файла
try:
with open(input_file, 'r', encoding='utf-8') as f:
text = f.read()
except UnicodeDecodeError:
print("Ошибка: Не удалось прочитать файл в кодировке UTF-8. Попробуйте другую кодировку.")
sys.exit(1)
print(f"Анализируем файл: {input_file}")
print(f"Размер выборки: {sample_size} слов")
# Очищаем текст
cleaned_text = clean_text(text)
# Разбиваем на выборки
samples = calculate_samples(cleaned_text, sample_size)
if not samples:
print("Текст слишком короткий для анализа. Необходимо минимум 16000 слов.")
sys.exit(0)
# Анализируем каждую выборку
percentages = []
for i, sample_words in enumerate(samples):
percentage = analyze_sample(sample_words)
percentages.append(percentage)
print(f"Выборка {i+1}: {percentage:.3f}% служебных слов")
# Вычисляем статистику
if percentages:
avg_percentage = sum(percentages) / len(percentages)
# Вычисляем отклонение (разброс)
max_p = max(percentages)
min_p = min(percentages)
deviation = (max_p - min_p) / avg_percentage if avg_percentage > 0 else 0
# Формируем результат
result = {
"input_file": input_file,
"sample_size": sample_size,
"num_samples": len(samples),
"average_invariant": avg_percentage,
"deviation": deviation,
"min_percentage": min_p,
"max_percentage": max_p,
"percentages": percentages
}
# Сохраняем результат в файл
output_file = os.path.splitext(input_file)[0] + '.dat'
try:
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print(f"\nРезультаты сохранены в файл: {output_file}")
print(f"Количество выборок: {len(samples)}")
print(f"Среднее значение инварианта: {avg_percentage:.3f}%")
print(f"Отклонение: {deviation:.6f}")
print(f"Минимальное значение: {min_p:.3f}%")
print(f"Максимальное значение: {max_p:.3f}%")
# Дополнительная информация
if avg_percentage < 19:
print("Замечание: Значение инварианта ниже типичного диапазона (19-27.5%)")
elif avg_percentage > 27.5:
print("Замечание: Значение инварианта выше типичного диапазона (19-27.5%)")
except Exception as e:
print(f"Ошибка при сохранении результатов: {e}")
else:
print("Нет данных для анализа")
if __name__ == "__main__":
main()
ECHO ON
chcp 65001 > nul
invariant_plotter.py zt.dat
PAUSE
import json
import matplotlib.pyplot as plt
import sys
import os
def plot_invariant_from_file(filename):
"""
Построение графика авторского инварианта со стандартной вертикальной осью
Parameters:
-----------
filename : str
Имя файла с данными (.dat)
"""
# Стандартный диапазон для вертикальной оси (ось Y)
# На основе данных из исследования: значения от 19% до 27.5%
# Добавляем запас сверху и снизу
STANDARD_Y_MIN = 18.0 # минимальное значение на оси Y
STANDARD_Y_MAX = 30.0 # максимальное значение на оси Y
# Проверяем файл
if not os.path.exists(filename):
print(f"Ошибка: файл {filename} не найден")
return
# Читаем данные из файла
try:
with open(filename, 'r', encoding='utf-8') as f:
data = json.load(f)
except json.JSONDecodeError:
print(f"Ошибка: файл {filename} не является корректным JSON")
return
except UnicodeDecodeError:
# Попробуем другую кодировку
try:
with open(filename, 'r', encoding='cp1251') as f:
data = json.load(f)
except:
print(f"Ошибка: не удалось прочитать файл {filename}")
return
# Извлекаем необходимые данные
sample_size = data.get('sample_size', 16000)
percentages = data.get('percentages', [])
if not percentages:
print("Ошибка: в файле нет данных для построения графика (отсутствует 'percentages')")
return
# Вычисляем среднее значение, если его нет в данных
if 'average_invariant' in data:
average_invariant = data['average_invariant']
else:
average_invariant = sum(percentages) / len(percentages) if percentages else 0
# Создаем график
fig, (ax, ax_stats) = plt.subplots(1, 2, figsize=(16, 6),
gridspec_kw={'width_ratios': [3, 1]})
# Номера выборок
sample_numbers = list(range(1, len(percentages) + 1))
# 1. ОСНОВНОЙ ГРАФИК на левой панели
# Рисуем ломаную линию
line_color = 'blue' if sample_size == 16000 else 'green' if sample_size == 8000 else 'darkorange'
ax.plot(sample_numbers, percentages, 'o-', color=line_color,
linewidth=2.5, markersize=10, markerfacecolor='white', markeredgewidth=2,
label=f'Процент служебных слов')
# Горизонтальная линия для среднего значения
ax.axhline(y=average_invariant, color='red', linestyle='--', linewidth=2,
alpha=0.7, label=f'Среднее: {average_invariant:.2f}%')
# ЗАДАЕМ СТАНДАРТНУЮ ВЕРТИКАЛЬНУЮ ОСЬ
ax.set_ylim(STANDARD_Y_MIN, STANDARD_Y_MAX)
# Добавляем горизонтальные линии через каждый 1%
for y in range(int(STANDARD_Y_MIN) + 1, int(STANDARD_Y_MAX)):
ax.axhline(y=y, color='gray', linestyle=':', linewidth=0.5, alpha=0.3)
# Выделенные горизонтальные линии
for y in [20, 22, 24, 26, 28]:
ax.axhline(y=y, color='gray', linestyle='-', linewidth=0.8, alpha=0.5)
# Настройки основного графика
ax.set_xlabel('Номер выборки', fontsize=12, fontweight='bold')
ax.set_ylabel('Процент служебных слов (%)', fontsize=12, fontweight='bold')
# Заголовок с информацией о файле
base_name = os.path.basename(filename)
file_name_without_ext = os.path.splitext(base_name)[0]
if file_name_without_ext.endswith('.dat'):
file_name_without_ext = file_name_without_ext[:-4]
# Определяем цвет заголовка в зависимости от размера выборки
if sample_size == 8000:
title_color = 'darkorange'
sample_info = "8000 слов (средняя выборка)"
elif sample_size == 16000:
title_color = 'blue'
sample_info = "16000 слов (оптимальная выборка)"
elif sample_size == 4000:
title_color = 'green'
sample_info = "4000 слов (малая выборка)"
elif sample_size == 2000:
title_color = 'purple'
sample_info = "2000 слов (минимальная выборка)"
else:
title_color = 'black'
sample_info = f"{sample_size} слов"
ax.set_title(f'АВТОРСКИЙ ИНВАРИАНТ\n'
f'{file_name_without_ext} | {sample_info}',
fontsize=14, fontweight='bold', color=title_color, pad=20)
ax.grid(True, alpha=0.3)
ax.legend(fontsize=11, loc='upper left')
ax.set_xticks(sample_numbers)
# Добавляем значения над точками
for i, value in enumerate(percentages):
# Выбираем положение текста в зависимости от положения точки
if i == 0:
va = 'bottom'
y_offset = 0.15
elif i == len(percentages) - 1:
va = 'top'
y_offset = -0.15
else:
# Сравниваем с соседними точками
if i > 0 and value > percentages[i-1]:
va = 'bottom'
y_offset = 0.15
elif i < len(percentages)-1 and value > percentages[i+1]:
va = 'bottom'
y_offset = 0.15
else:
va = 'top'
y_offset = -0.15
ax.text(sample_numbers[i], value + y_offset, f'{value:.2f}%',
ha='center', va=va, fontsize=10, fontweight='bold',
bbox=dict(boxstyle='round,pad=0.2', facecolor='yellow', alpha=0.7))
# 2. ПАНЕЛЬ СТАТИСТИКИ на правой панели
# Вычисляем статистику
min_percentage = min(percentages)
max_percentage = max(percentages)
range_percentage = max_percentage - min_percentage
deviation = data.get('deviation', 0)
if deviation == 0:
# Вычисляем стандартное отклонение, если его нет в данных
import math
avg = average_invariant
squared_diffs = [(p - avg) ** 2 for p in percentages]
deviation = math.sqrt(sum(squared_diffs) / len(percentages)) if percentages else 0
# Создаем текстовую статистику
stats_lines = [
"СТАТИСТИЧЕСКИЕ ДАННЫЕ",
"=" * 30,
f"Размер выборки: {sample_size} слов",
f"Количество выборок: {len(percentages)}",
"",
f"Среднее значение: {average_invariant:.4f}%",
f"Минимум: {min_percentage:.2f}%",
f"Максимум: {max_percentage:.2f}%",
f"Размах: {range_percentage:.2f}%",
f"Отклонение: {deviation:.4f}",
"",
"СТАБИЛЬНОСТЬ:"
]
# Оценка стабильности
if deviation < 0.05:
stability = "ОЧЕНЬ ВЫСОКАЯ"
stability_color = "darkgreen"
elif deviation < 0.1:
stability = "ВЫСОКАЯ"
stability_color = "green"
elif deviation < 0.2:
stability = "СРЕДНЯЯ"
stability_color = "orange"
else:
stability = "НИЗКАЯ"
stability_color = "red"
stats_lines.append(f" {stability}")
# Отображаем статистику
ax_stats.axis('off') # Выключаем оси для панели статистики
# Создаем текстовый блок
stats_text = "\n".join(stats_lines)
ax_stats.text(0.1, 0.95, stats_text, transform=ax_stats.transAxes,
fontsize=11, fontfamily='monospace',
verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='lightgray',
alpha=0.8, edgecolor='black'))
# Добавляем цветной индикатор стабильности
stability_box = plt.Rectangle((0.7, 0.3), 0.25, 0.1,
facecolor=stability_color, alpha=0.7,
transform=ax_stats.transAxes)
ax_stats.add_patch(stability_box)
ax_stats.text(0.825, 0.35, stability, transform=ax_stats.transAxes,
ha='center', va='center', fontsize=10, fontweight='bold',
color='white')
# Добавляем ссылку на методологию
method_text = ("МЕТОДОЛОГИЯ:\n"
"Инвариант = процент служебных слов\n"
"(предлоги, союзы, частицы)\n"
"54 служебных слова\n"
"Стандартная ось Y: 18-30%")
ax_stats.text(0.1, 0.05, method_text, transform=ax_stats.transAxes,
fontsize=9, fontfamily='monospace',
bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.6))
plt.tight_layout()
# Сохраняем график в файл
output_filename = f"{file_name_without_ext}_стандартная_ось.png"
plt.savefig(output_filename, dpi=150, bbox_inches='tight')
print(f"График сохранен как: {output_filename}")
print(f"Размер выборки: {sample_size} слов")
print(f"Количество выборок: {len(percentages)}")
print(f"Среднее значение: {average_invariant:.4f}%")
print(f"Отклонение: {deviation:.4f}")
print(f"Стабильность: {stability}")
print(f"Вертикальная ось: {STANDARD_Y_MIN}-{STANDARD_Y_MAX}% (стандартная)")
# Показываем график
plt.show()
return {
'sample_size': sample_size,
'average': average_invariant,
'deviation': deviation,
'min': min_percentage,
'max': max_percentage,
'range': range_percentage,
'stability': stability,
'num_samples': len(percentages)
}
def main():
"""
Главная функция программы
"""
if len(sys.argv) != 2:
print("=" * 60)
print("ПРОГРАММА ДЛЯ ПОСТРОЕНИЯ ГРАФИКА АВТОРСКОГО ИНВАРИАНТА")
print("=" * 60)
print("\nИспользование:")
print(" python invariant_plotter.py <имя_файла.dat>")
print("\nПример:")
print(" python invariant_plotter.py 12st.dat.txt")
print("\nТребования к файлу:")
print(" - Формат JSON с данными об авторском инварианте")
print(" - Должен содержать поле 'percentages' с процентами служебных слов")
print(" - Может содержать поле 'sample_size' (по умолчанию 16000)")
print("\nОсобенности программы:")
print(" - Вертикальная ось ВСЕГДА стандартная: 18-30%")
print(" - Автоматическое определение размера выборки")
print(" - Оценка стабильности инварианта")
print(" - Статистика и методология на графике")
print("=" * 60)
return
filename = sys.argv[1]
# Проверяем расширение
if not filename.lower().endswith(('.dat', '.json', '.txt')):
print(f"Предупреждение: файл {filename} имеет нестандартное расширение")
answer = input("Продолжить? (y/n): ")
if answer.lower() != 'y':
return
# Обрабатываем файл
print(f"\nОбработка файла: {filename}")
print("-" * 40)
try:
result = plot_invariant_from_file(filename)
print("\nОбработка завершена успешно!")
except Exception as e:
print(f"\nОшибка при обработке файла: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
main()

Если программы здесь выкладывать не формат, скажите, больше не буду.
Комментарии
Вопрос даже не к методике (см. близкие результаты у Леонова с Фединым) и "разброс" по ПСС Чехова и Шолохова... а к самим текстам - что есть авторский вариант? Изданный?! В какой версии? Например, "12 стульев" - есть черновой (частично легализованный через отдельные публикации *тогда*) и опубликованный, причем этих публикаций несколько... Какая версия использовалась?! И сравнивались ли *разные* версии одного текста? Собачье сердце было же похищено при обыске, о чем синеглазый аж Верховному писал и черновиков "не осталося".
ЗЫ: хороший тест на булгаковоеда (не опечатка) - сколько писем написал синеглазый прежде чем был звонок от самого?
То, что версия о "якобы плагиате" - это неплохая пиар идея какой-то верной ученицы Омаровны (вряд ли третьей вдовы - артистки Булгаковой - хотя она бы оценила), на мой взгляд, очевидно. Спасибо. Но, что же следует из этих данных? Что стиль автора меняется? ;) что морфинизм это страшное заболевание? И кстати - Белая гвардия - это же фактически автобиографическая вещь - а тут спорное авторство, как и самое тяжёлое психическое состояние... И тогда уж и Дни Турбиных с Каббалой светош прогнать... Правда опять - какие варианты текста...
Это на скорую руку сделал к статье Молнируйте, Аткарск и горшановское пиво, или кто написал «12 стульев» и «Золотой теленок».
С Белой Гвардией промахнулся, захватил в конце пьесу и примечания. Просто показал, что метод работает.
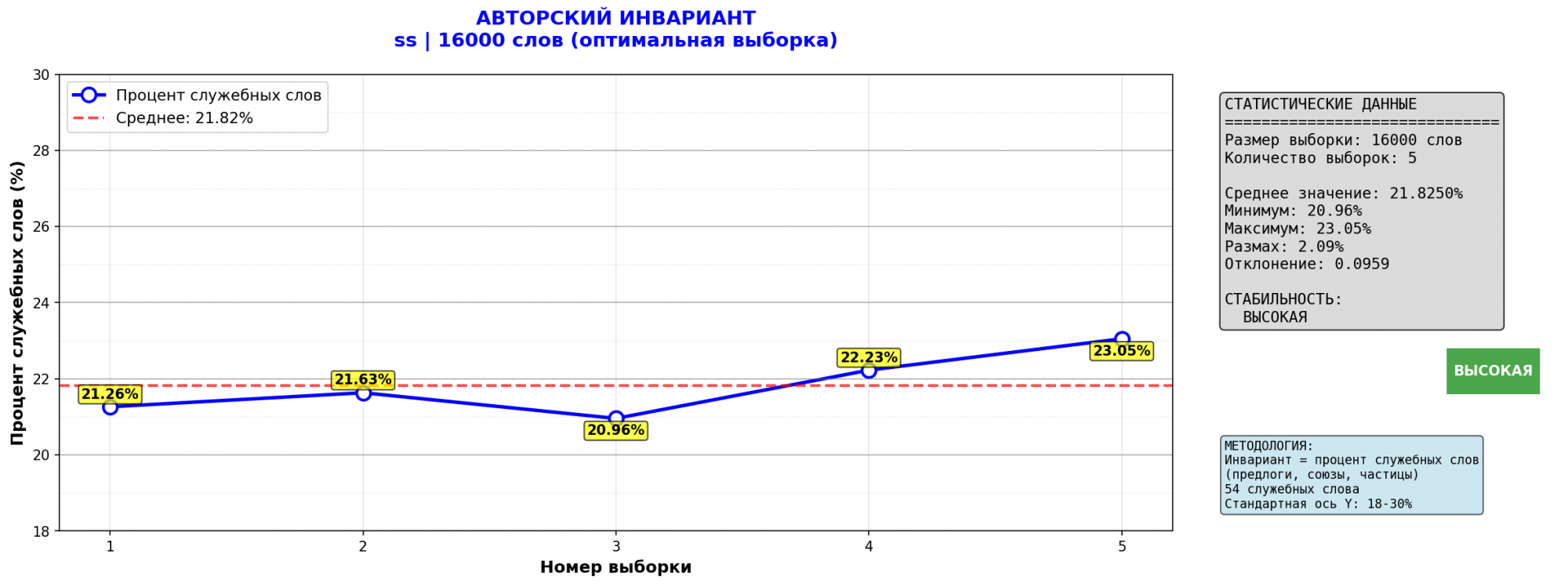
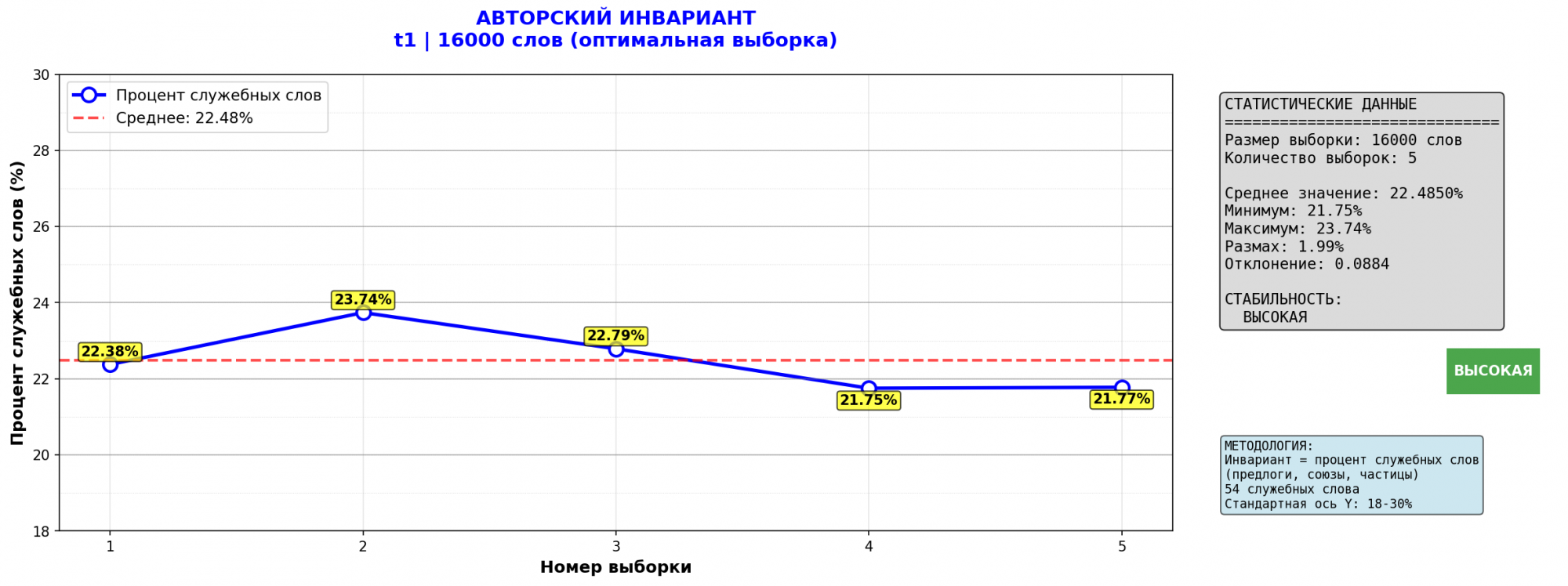
Авторские инварианты, Булгакова и Ильфа-Петрова, похоже, разные.
Я понял к чему ;) и написал про талантливую ученицу Омаровны, которая приложила таки руку не только к возвращению имени, но и к текстам (а сейчас уже и к авторским правам).
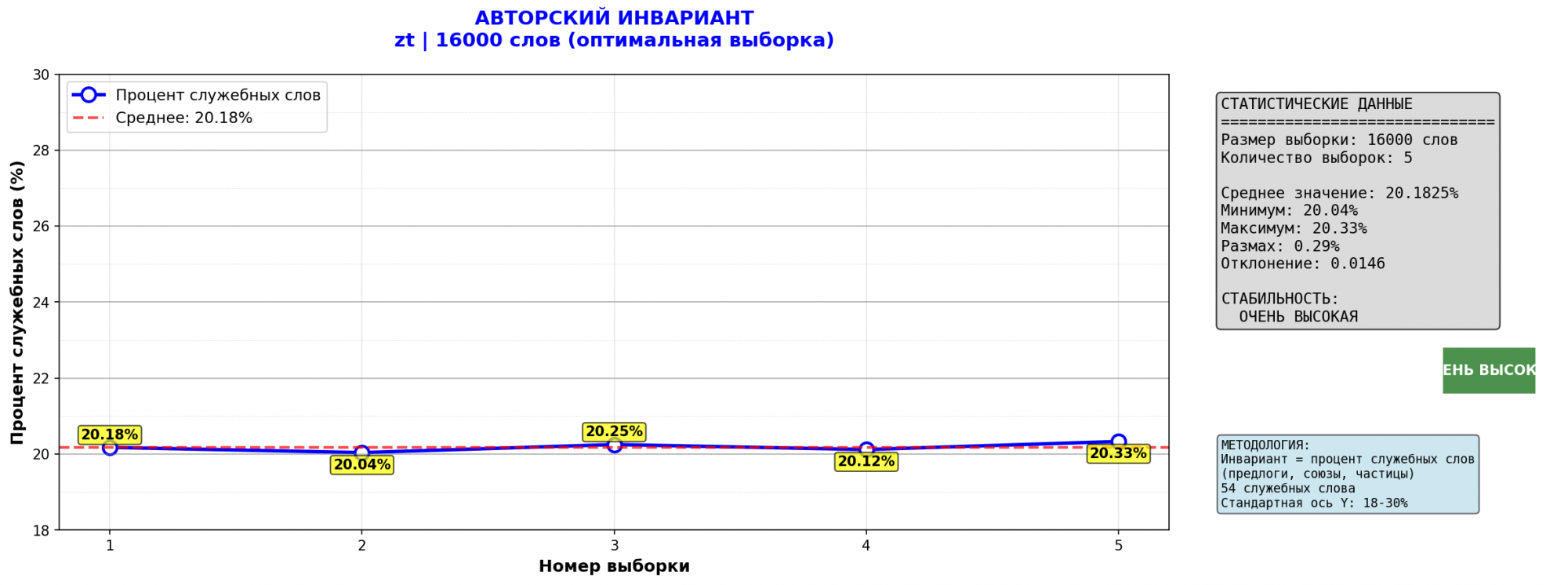
Но я же написал - что делать с собранием сочинений Чехова? Там тоже авторский инвариант разный!!! Вы же сами в комментах опубликовали сводку по Шолохову - и вот как?!
И этому... автору я написал скромное замечание, что лично для меня авторство синеглазого морфиниста (два факта подряд) в том, что издается ныне как МиМ - вызывает некоторые сомнения - и после чтения черновиков, и обстоятельного знакомства с обильной булкаговоедной литературой и биографиями...
Да какая Амлински талантливая ученица Мариэтты Омаровны? Там, в её книжонке, анализ текста на уровне ощущений, примерно как у Фоменко иК при построении исторических гипотез. Из книги Амлински:
"Глава I. Уездный город N и его обитатели. «В уездном городе N было так много парикмахерских заведений и бюро похоронных процессий, что, казалось, жители города рождаются лишь затем, чтобы побриться, остричься, освежить голову вежеталем и сразу же умереть. А на самомделе в уездном городе N люди рождались, брились и умирали довольно редко. Жизнь города была тишайшей. Весенние вечера были упоительны, грязь под луною сверкала, как антрацит, и вся молодежь города до такой степени была влюблена в секретаршу месткома коммунальников, что это просто мешало ей собирать членские взносы. Вопросы любви и смерти не волновали Ипполита Матвеевича Воробьянинова, хотя этими вопросами, по роду своей службы, он ведал с 9 утра до 5 вечера ежедневно, с получасовым перерывом для завтрака. По утрам, выпив из причудливого (морозного с жилкой) стакана свою порцию горячего молока, поданного Клавдией Ивановной, он выходил из полутемного домика на просторную, полную диковинного весеннего света улицу имени товарища Губернского. Это была приятнейшая из улиц, какие встречаются в уездных городах. По левую руку, за волнистыми зеленоватыми стеклами, серебрились гробы похоронного бюро «Нимфа». Справа,за маленькими, с обвалившейся замазкой окнами, угрюмо возлежали дубовые, пыльные и скучные гробы, гробовых дел мастера Безенчука. Далее «Цирульный мастер Пьер иКонстантин» обещал своимпотребителям «холю ногтей» и «ондулянсион на дому». Еще дальше расположилась гостиница с парикмахерской, а за нею, на большом пустыре, стоял палевый теленок и нежно лизал поржавевшую, прислоненную к одиноко торчащим воротам вывеску: «Погребальная контора „Милости просим“». Еще к описанию достопримечательностей городка в главе «Слесарь, попугай и гадалка» читаем: «Были на доме еще два украшения, но уже чисто коммерческого характера. С одной стороны – лазурная вывеска «Одесская бубличная артель – «Московские баранки». На вывеске был изображен молодой человек в галстуке и коротких французских брюках. Он держал в одной, вывернутой наизнанку руке сказочный рог изобилия, из которого лавиной валили охряные московские баранки, выдававшиеся по нужде и за одесские бублики».
Первым звоночком, привлекшим мое внимание, была нежность в описании достопримечательностей уездного городка. Повествование проникнуто любовью, хотя ничем, на первый взгляд, эта любовь к провинциальному захолустью не могла быть вызвана. «Полная диковинного света улица», «весенние вечера были упоительны», «приятнейшая из улиц» – такими эпитетами одарил автор этот ничем не примечательный городок. Поэтому вывод напрашивался сам собой: чем-то это место было ему дорого. А теперь прочтем еще одно описание такого же маленького городка: «И вот я увидел их вновь, наконец, обольстительные электрические лампочки и главная улица городка, хорошо укатанная крестьянскими санями, улица, на которой, чаруя взор, висели – вывеска с сапогами, золотой крендель, изображение молодого человека со свиными наглыми глазками и с абсолютно неестественной прической, означавшей, что за стеклянными дверями помещается местный Базиль, за 30 копеек бравшийся вас брить во всякое время, за исключением дней праздничных, коими изобилует отечество мое». Зарисовка взята из рассказа «Морфий», в котором описан уездный город Вязьма. В этот городок был переведен из села Никольское молодой врач Михаил Булгаков, который проработал полтора года в деревне, не видел никого, кроме больных, фельдшера и двух акушерок, и радовался газете двухнедельной давности. Для Булгакова этот перевод в уездный город 8 означал возвращение к жизни, и потому, ничем не привлекательная (для любого непровинциального жителя) Вязьма, была так нежно, с любовью описана им. Привлекла внимание и вывеска «Цирульный мастер Пьер и Константин». А точнее буква «у» в слове «цирульный». Заинтересовало это тем, что тема безграмотного перевода названий улиц, магазинов и официальных учреждений с русского на украинский язык, волновала и возмущала писателя Булгакова, когда он находился в Киеве в 1918-1919 годах. Об этом он написал в очерке «Киев-Город», опубликованном в 1923 году: «Это киевские вывески. Что на них только написано, уму непостижимо. Оговариваюсь, раз и навсегда: я с уважением отношусь ко всем языкам и наречиям, но, тем не менее, киевские вывески необходимо переписать. Нельзя же, в самом деле, отбить в слове «гомеопатическая» букву «я» и думать, что благодаря этому аптека превратится из русской в украинскую. Нужно, наконец, условиться, как будет называться то место, где стригут и бреют граждан: «голярня», «перукарня», «цирульня», или просто-напросто «парикмахерская»! Как видишь, читатель, из рассказа Булгакова «Морфий» вывеска с золотым кренделем, преобразовавшаяся в вывеску бубличной артели, парикмахерская и молодой человек были «заимствованы» и использованы в романе «12 стульев». При этом мы не забываем, что булгаковский рассказ «Морфий» был опубликован в 1927 году, к моменту работы над разбираемым романом, учитываем нежность в описании городка (странную для одесситов Ильфа и Петрова, но логичную для Булгакова) и слово «цирульный», рассмотренное ранее. Предлагаю задуматься над этим и продолжить исследование романа «12 стульев»."
В обличениях Фоменко сотоварищи самое интересное в механизме обеспечения дисциплины соблюдения табу на обнаружение аналогичных по сути методов в исполнении его кагбы «антагонистов».
Например.
все книжки написаны с помощью ии, давно уже, Гоголь не даст соврать!
— Вы слышали, доктор, Булгаков за одну ночь два романа накатал?!
— И вы говорите, Пал Палыч...
А если использовать готовый стемминг (snowball) и анализировать не текст, а полученный вектор?
Да полно всего сделали.
Те же служебные части речи необязательно искать регулярными выражениями - есть прекрасные морфермные анализаторы, например, древний PyMorphy2 (что там есть новое, давно тему не рыл)?
Для стемминга и/или лемматизации нужно что? Знать эти слова!
А если не знаешь, то регулярки по "сырому" тексту пойдут, и не все служебные части речи учитывать будут, которых поболее, чем в коде от ПолПола.