







Теоретических работ достаточно много по вопросу, как извлекать даже из ложной информации не ложную (не без контекста конечно), есть и различные грубо говоря "платные" сервисы для обывателя, правда в реальности не так то все просто, да и в общем случае времени нет свободного, на вот это вот все.
Но есть и хорошие новости - если раньше обработка информации была доступна только профи, то сейчас в принципе относительно приемлемо можно делать даже дома на коленке.
Так как на самом деле необходимо смотреть видосики или тем более читать всякую интернет шнягу?
Практически любое информационное сообщение в интернете, пускай даже оно и замаскировано под "какой нить" извиняюсь "высер", раскладывается на вектор из упоминаний чего то или кого то с подведением соответствующей коннотации (обычно негативной ибо "просмотров больше").
Так как уровень "генераторов" падает и все чаще собственно эти сообщения строгают по заданным шаблонам нейросетки, то и обратную декомпозицию также можно выполнить с их помощью, заодно сэкономив время.
Итак - вместо траты время на просмотр "видоса" - можно реализовать следующий алгоритм.
Сохраняем видео (или аудио), если уже есть субтитры (одно время многие видеохостеры делали, но сейчас начали отключать - так понимаю экономят) сохраняем и субтитры, если нет, то генерируем свои, пропускаем субтитры через ПО для выделения сущностей ( люди, компании например ), так же можно выделить "коннотации" - т.е. негативный или позитивный контекст относительно "сущности" , потом заносим в БД и строим карту (можно трехмерную со временем), ну или матрицу если хотите.
Кто - про кого и про что, что сказал, с одним из измерений - "временем". Не обязательно это про "друг" про "дружку" должно быть, можно и относительно какого то "будущего" или "прошлого" - "мема" (все рано или поздно превращается увы в оные).
По результатам например заметно, как начинают как по команде на или за Пушкина, или заунывно трындеть про "демографию." ...
Как это может выглядеть на практике:
Чтобы, как называется никого случайно не задеть, для примера возьмем в наших условиях полуисторический ( наугад - сам и не смотрел, что там несут ) видос про русскую "литературу" 90-ых:
Ты-туп кстати тут уже выделил "людей" из видоса, разметил поток, что тоже удобно, для сравнения.
Итак.
Для сохранения видоса в папку - делаем так ( привел сразу если кому надо с проксей ) , сохраняем только аудиодорожку ( очень редко кто то показывает слайды, т.е. анализируем только аудиоряд )
yt-dlp -c --proxy "socks5://user:password@ip:port/" --sub-format vtt --write-auto-subs --write-info-json --sub-lang "ru.*" --no-abort-on-error --ignore-errors -x -f worstaudio --audio-format mp3 http://адрес_видоса -o "data/%(upload_date)s_%(id)s.%(ext)s"
Скачивается:

получаем набор файликов:
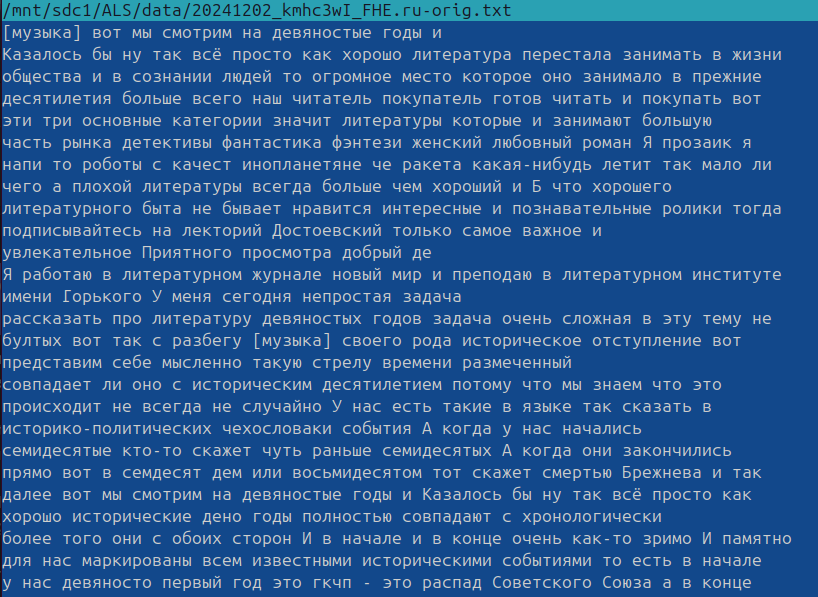
далее генерируем "субтитры" ( бесплатное ПО - whisper-ctranslate2 ) если их нет. Кстати последнее время уровень генерируемых самими видеохостингами субтитров как ни странно упал и это на фоне роста мощностей!.
В данном случае транскрипция от гугла действительно просто отвратительного качества:
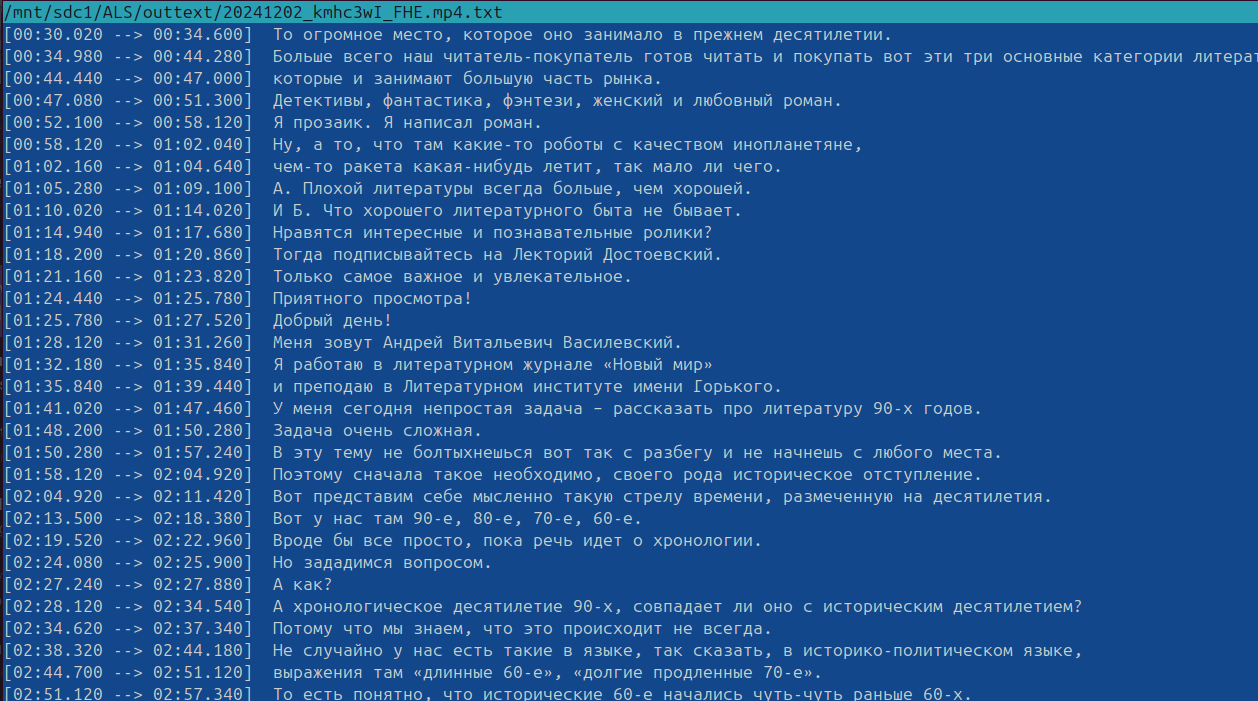
соответственно делаем свою транскрипцию:
whisper-ctranslate2 $1 --model large-v3 --output_dir outmisc --language Russian > $2
и действительно странно, но достаточно тупая "домашняя" нейросетка оказалась лучше, чем у гуглоидов
----------
и для выделения сучностей раньше была библиотека от мистера Кукушкина [ https://lab.alexkuk.ru/ ] - Наташа
сейчас есть spacy - https://spacy.io/models/ru#ru_core_news_lg ( на его же "неруси" сделана )
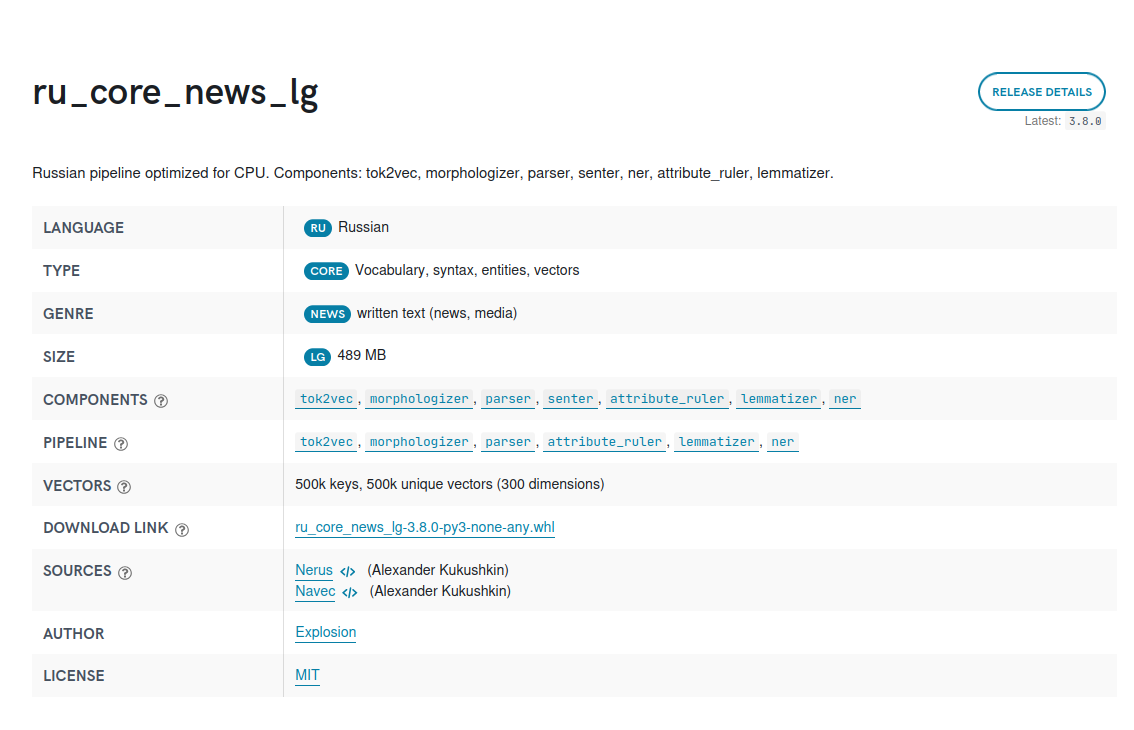
Допустим сделаем простенький скрипт с ее использованием:
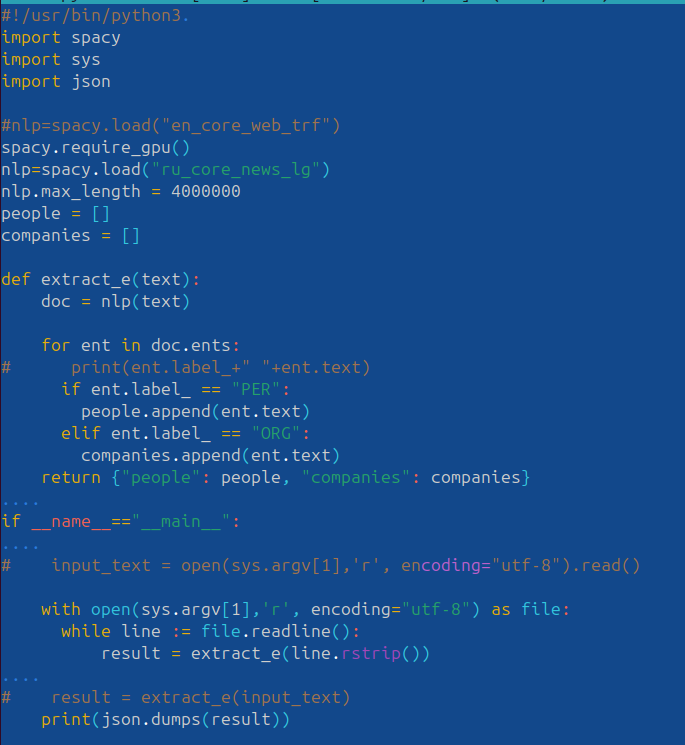
Результат прогона через него
Как видим уже больше, чем у хугля, ну не суть ( Возник первый же вопросик, как хугль отфильтровал, кого включать в свою подборку, отображаемую под видосом, а кого нет - ибо как видим набор то конкретно по "ширше" будет... ?)
Это все далее закидывается в соответствующую базу (последнее время предпочитаю clickhouse ибо он и правда _быстрый_ , хотя конечно лучше что нибудь импортозамещенное типа postgres от местных астрофизиков )
Например в таблицу с колонками:
[ время ] , [ канал ] , [ видос ] , [ тип объекта ] , [ время упоминания ] , [ коннотация ]
И так по всему, до чего дотянемся.
Соответственно со временем становится легко отслеживать, как поднимаются "когнитивные" волны по тому или иному "объекту", а так же появление новых или забытие "старых" "мемов".
Софт сейчас пишется быстро - много всего готового, легко допилить напильником. Выше просто пример того, насколько это все стало просто.
В чем может быть проблема при "бесплатной" реализации?
На одном "домашнем" присоединении Вы не сможете мониторить сразу действительно много каналов, скажем так бесплатно.
Что можно сделать - собрать docker образ, либо еще лучше все закомпилить в одно приложение (немного больше возни, с учетом количества сторонних библиотек , но тоже реализуемо вообщем то, в т.ч. на arm toolchain чтобы на мобилках гонять, бгг) и раздать его друзякам ( обычно раскладывается по разным хостингам ).
Где вот это все будет получать команды (типа выполнить анализ соответствующего url и вернуть результат), далее написать несложный сервер, который раздает клиентам задания и получает от них результаты обработки, через апи.
Таким образом "народный вариант" позволит фильтровать потоки бреда и не очень бреда, обрушиваемого на головы человечков медиа-корпами или "энтузиастами" (в т.ч. псевдо) и выделять из него только то, что действительно интересно, ну и заодно подсвечивать реальные векторы, выявлять "волны", "первичку" и прч.
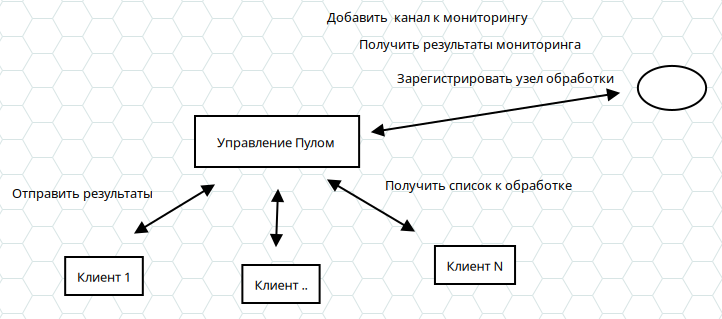
Схематично вот выше.
С управлением очередью можно тоже особо не заморачиваться, а сделать на готовом - rabbitmq например, так как передается только обработанное, то требования к серверу минимальные...
У "рекламщиков" есть _конкретно_ продвинутые такие Машины, в т.ч. по скажем так не совсем публичным данным (особенно после того, как они интегрировались с телекомщиками и банкирами), которые "смотрят и читают всё".
Немного (реально не много) сложнее схема с символическими аллюзиями - это когда "широковещателем" подбирается что то похожее на, с учетом целевого контекста, но даже с учетом этого уровня все равно по итогу это все чистая механика. В подложке у которой лежит либо коммерция, заказ, либо тупо агрессия с вектором атаки. Из-за чего возникает агрессия, если это не заказ? Несоответствие контекстов? Вот тут уже интересней конечно. Насколько понял есть Модели и с ними...
Следующие уровни это смыкание "смотрящих машин" с социо-экономическими сгустками, имеющими реальные ресурсные возможности - причем порой из разных административных контуров.
А так же их разборки между собой, иногда выглядящие конкретно забавно.
Слайд из классики:
Зато даже поверхностный анализ производной от векторов позволяет хотя бы приблизительно, но все же восстановить реальные расклады.
Но это уже другая сказка... всем хороших выходных.
P.S.
Использованное ПО:
https://github.com/yt-dlp/yt-dlp
https://github.com/Softcatala/whisper-ctranslate2
https://spacy.io/models/ru#ru_core_news_lg
P.S. 2
Вывод из этой басни простой - следует крайне скептически относиться к любому, как сейчас говорят "контенту", производимому за денюжку, или просто ма$$овому, но не официальному - и раньше то это просто конкретно все было утилитарно, а сейчас, с развитием технологий превратилось, просто в "механику". Академический сектор пока еще держится, за счет института рецензирования и слабой обратной связи с размером аудитории, но тоже местами превратился в оную.
Комментарии
Люди просто не поняли что им тут написали :)
Просто английского языка да и еще и вместе со скринами с Linux да и в придачу со скриптами смотрятся как в фильмах про хакеров, проще объяснять надо!
Я, как подмножество людей, которые, скорее всего, не поняли что им написали, еще и не понял зачем это мне? В перерывах между попытками как-то спасти свои пенсионные накопления и поисками дешевой гречки, анализировать алгоритмы оболванивания и манипулирования? Как мне это поможет? Я знаю, что они есть. Мне кажется, этого достаточно.
"Гречку" коммерсы-ритейлеры сейчас похоже рызгрывают алгоритмами, как раз в т.ч. на медиа и работа с ними могла бы помочь и обывателям....
Ну или хотя бы понимать, как все устроено, таи никакой конспирологии просто бизнес похоже.
Присоединяюсь. Вообще... По возможности стараюсь (пытаюсь) ограждать себя от новостной информации, особенно политической. Абсолютно согласен с Павлом Щелиным, что действительно важные события мимо тебя не пройдут, даже если не смотреть ТВ, не ходить в тырнет и не слушать радио. Хотя сложно... Вечно лезешь послущать-глянуть.
... а в машине, на прогулке, в магазине и проч. пытаюсь слушать или аудиокниги классические, или популярные лекции по истории, физике, психологии и проч.
И это правильно!
Новости давно из новостей превратились в что то странное...
Картинки, таблицы пропускаем, в пролетарскую суть вникаем.
Ну вот же выжимка: Вывод из этой басни простой - следует крайне скептически относиться к любому, как сейчас говорят "контенту"
В том числе и к этой статье. Как там у Беркема - зачем ЭТО сказали, зачем это сказали ТЕБЕ, зачем это сказали тебе СЕЙЧАС.
Сам принцип создания видеоконтента таков, чтобы охватить как можно большую аудиторию по тематике. Соответственно, ему полагается быть популярно-доходчивым, ради чего можно (и нужно) жертвовать полнотой и сложностью информации. Да в принципе, и с текстовыми статьями то же самое. Берёшь, очерчиваешь тему и говоришь по ней то, что хочется в данный момент. А серьёзная информация — да, она на академическом уровне. И ещё «в секретных кабинетах».
Ну и смысл такое потреблять, если это не официальная информация?
Предположу, что далеко не все способны и хотят усваивать серьёзную, глубоко продуманную и проработанную информацию. Теоретические вещи уже отсекают многих, ориентированных на конкретику. И тем более дискурс о возможности той или иной теории — процент интересующихся на этом уровне исчезающе мал, потому что выше него нет ничего. В подавляющем большинстве случаев люди обходятся фрагментарным и необязательно истинным знанием, живут каждый в своём информационном пузыре и не понимают, зачем им знать и уметь что-то больше того, чем они повторяют каждый день. Это вопрос амбиций, и почему они у кого-то есть, а кому-то достаточно имеющегося — сие тайна великая есть.
По моей субьективной оценке народ у нас достаточно сообразительный и без теории норм сам фильтрует на интуиции.
Триллиарды просмотров на площадках часто рисованные (особенно если они для отчетности).
Заметку написал может кому то пригодится в практическом плане... сам пользуюсь иногда удобно.
Есть разница, происходит ли такая фильтрация в моменте или на долгосроке. В моменте — да, согласен. Но по моей исследовательской тематике (субъективное строение человека) она не прокатывает. Нигде так не царят предрассудки, как в оценке других людей, но большинство-то считает, что они судят друг о друге истинно. Даже слово «объективно» вворачивают, ведь на поведение же смотрят. Ладно, сорри, отклоняюсь от темы.
Круто! Утащил в закладки!
Спасибо за наводку, как раз хотел радио мониторить - в облако слов по частоте упоминания.
Можно попробовать "выделить сущность" очередного текста Романа Смирнова:
Основной вопрос: ... на самом деле необходимо ли смотреть видосики или тем более читать всякую интернет шнягу?
Смотреть видосики (видеоконтент) - себя не уважать, разве что ввиду крайней необходимости (популярности, доходчивости)!
Читать текстовые статьи - естественно, нужно по диагонали с целью "выделения сущности (сути, смысла).
Рассматривать необходимо и негативный и позитивный контекст относительно "сущности", в противном случае есть опасность оказаться вдруг и неожиданно в полном окружении бурно размножающейся либероидной мрази. Лучше - как-нибудь по возможности заранее приготовиться к этому.
Что касается литературы, без всяких натужных исследований, уже давно стало ясно, что она перестала занимать то место, которое она раньше занимала в нашей жизни. Остатки интереса у некоторых вызывают детективы (преступления, убийства, романтизация криминала), фантастика - фэнтези (необузданные измышления, романтизация причуд), любовный роман (перетряхивание грязного белья, подглядывание в разные "скважины", романтизация гламура и пошлости).
Зачем создавать себе проблемы? Смотреть негодное, а потом (или до) рихтовать и пилить его.
Годное тоже надо фильтровать иначе времени ни на что не хватит...
стандартные темы, у того же freeswitch, на базе которого почти вся ip-телефония (команда от астериска) есть готовые s2t и t2s (speech to text и наоборот) библиотеки, вообще в рилтайме стопслова ищешь или видит оператор какого-нибудь коллцентра, аналогично ему трафик видео-аудио для фильтрации натравливаешь.
текст жаль терать, оставляя только сущности-стопслова, поэтому используют хранилище с fts (full text search), где полноценные падежи, склонения, по корням можно найти и проч,
в природе остался жив только продукт lucene, его апач захапал, можно также от апача solr поставить, для небольших задач хватит, на побольше opensearch (бывший еластик) в нем же реализовать справочники разных сущностей в зависимости от задач или контекстов со ссылками на сами документы-контектсы, т.е. сущность 1 к многим указывает на документы и места, где употреблялась,
семантики толковой нет и не будет, тут придется с человеческм фактором самому.
а для дома хватит самой либы apache-lucene, только с питоном подружить через py4j, раз так струмент нравится.
вкрате обычно так делается в конторах, где спайдеры тырнет шерстят на предмет выявления тенденций.
и, уже имея справочники сущностей-стопслов уже более сложные алгоритмы выявления связей включаются, вплоть до вычисления узла, откуда вся ветка фейков стартовала.
Есть ссылка на s2t ? Оно открыто?
Если это что то старое опенсорсное аля сфинкс, то там не очень...
Так то конечно у профи, чего только нет.
сфинкса много лет уже не видно, его так из монолита и не развили, это было как раз, когда закопали замечательную библиотеку на c++ для lucene и оставили в доступе только на жавастеке (уверен, что сишную развивают закрыто, все-таки максимально быстрая), тогда же войнушка и шла за FTS, очевидно было, что за этим будущее.
модулей для свича хватает, например вот
https://github.com/voicegain/mod_voicegain
вроде 4 года назад что-то меняли, есть старые станданртные, все открытый код, как и сам freeswitch
https://docs.freeswitch.org/ (doxygen)
можно вообще отдельные реализации s2t(stt) посмотреть, у яндекса были открыты исходники.
Спасибо, сравню с виспером... после яндексовской открытой томиты ( https://yandex.ru/dev/tomita/ ) ничего у них не смотрю... (не очень оказалась), а апи не интересно
эээ, если правильно понял, там модуль по ссылке это обертка к api voicegain https://console.voicegain.ai/login ... не, такое не очень интересно.
Зачетная техноэротика!
А дальше поверх clickhouse положить эластик с графовой агрегацией и оно красиво отрисует кто какие вбросы строил, кто повторял и т д )
А еще в clickhouse можно загнать сами векторы и уже по ним построит свой классификатор или банальный cosin )
именно,
но больше идея про асимметрию к возможности корпов, через распределенное приложение интересна...
У https://laion.ai/ на гите где-то есть такой центр как вы описали, только они для картинок пользуют.
И опять же, как эти данные представить адекватным доступным до человеческого восприятия образом? Ну построили вы "сеть сетей", "матрицу матриц" и "графы графов", а что потом с этим делать? Как это практически использовать.
Как это практически использовать.
Именно что получается:
Ну или информационная порнография. Увлекательно, технологично, но совершенно бессмысленно. Сложность ради сложности и как "любовь к искусству".
Увлекательно, технологично, но совершенно бессмысленно. Сложность ради сложности и как "любовь к искусству". 
А какие забавные когнитивные искажения должны возникнуть от просмотра этого "искусства" это еще более интересный вопрос. И тут тоже можно построить "графы графов" и найти массу забавных корреляций.
Вам что жалко что ли )?
А пример нормальный, +-также отслеживаются общественные настроения или делаются новостные триггеры для высокочастотной торговли )
Мне не жалко. Но это как затея с "сети сетей" для CRM, можно, но не нужно никому.
И мне интересно, вдруг кто может предложить "как это понимать". У меня мозгов не хватает это понять. Хотя понимаю как подступиться к теории, но и понимаю свою ограниченность в понимании.
Нифигасе не нужно ))) у бизнюков огромный арсенал таких инструментов...
Ну и что это дает? Но готов освоить любой бюджет на этой затее. Еще с ходу могу подсказать массу других вариантов построения красивых презентаций.
Но готов освоить любой бюджет на этой затее. Еще с ходу могу подсказать массу других вариантов построения красивых презентаций. 
Помнится я уже вам писал что в сложных системах рулит эмерджентность. Так что если вы не можете высчитать эмерджентность, не можете отличить ложные корреляции от истинных, грубо говоря если у вас нет общей теории, то вы можете осваивать любые бюджеты, находить бесконечные корреляции "длинны бороды и мировых цен на золото", но все это никак практически не применимо. Но доказать что в действительности "это не работает" не просто сложно, а фактически и технически невозможно. Потому что снова и снова будет возникать новые ложные корреляции. А том что все это не работает вы всегда узнаете постфактум. Когда эмерджентность аукнется.
Если бы не давало не покупали, рынок огромный этих систем, все платформы используют.... смешно даже обсуждать.
Хе хе достаточно знать, что конкурент верит в такие модели )))) А если серьезно то достаточно много методик для отсечения "бесконечные корреляции", прикол про огурцы и пиратов не на пустом месте вырос.
Вам потребуется бесконечное количество методик. И все сложнее и сложнее. Пока вы сами не запутаетесь в вашем модельно-зависимом реализме.
Так что нужна функциональная теория.
Ну человеки уже достаточно давно придумали всякие random forest, регресии и тд, для оценки важности переменных . Те выделение сильных или групп слабых переменных это так-то основа основ в аналитике.
Я не просто так упомянул модельно-зависимый реализм. Вы забываете самое важное - наблюдатель тоже часть наблюдаемой системы.
Вот мы и вернулись к началу дискуссия. Без теории данные бессмысленные. Придется "выбрать" теорию для адекватного восприятия данных. Но любая теория будет модельно-зависимым реализмом. Сам факт модели уже меняет наблюдаемую систему.
И с чего и начали, на текущий момент никакой адекватной теории не существует.
А бесконечные корреляции позволяют создать бесконечное количество теорий. И получается никакого практического применения нет. Но можно сколько угодно заниматься "техноэротикой" просто из "любви к искусству". Сложность ради самой сложности. Просто потому что мы можем это сделать.
Все это я к тому, что наш антропоцентризм и антропоморфизм мешает нам увидеть суть явления и построить адекватные теории. У нас нет верной "системы координат" для понимания.
Пропустил слово "сложность" Так в том то и мякотка. Еще лет 15-20 назад эта статья превратился бы в огромный талмуд к программно аппаратному комплексу для сурового энтерпрайза, а сейчас ноутбук + пара скриптов. )
Ну да, дети добрались до "забавных игрушек" и уровня экзофлоповой производительности. И теперь пробуют создавать разные "сложности". Но только это совсем не игра и не игрушки. История с появлением LLM явно намекает что это совсем не игра.
Интересная прикладушка. Спасибо!
Большое спасибо, Роман, очень хороший обзор, очень полезно _лично_ для меня
Спасибо, очень интересный обзор технологии. Повеяло духом свободы древнего интернета. 😊
По идее, первичную информацию нельзя сплошняком читать даже профессиональным аналитикам, так как современные мозгопромывательные технологии промывают мозги уже вне зависимости воли читающего/смотрящего и стараются сломать, то что не могут промыть. Так что фильтры нужны даже для личной гигиены и наверно любопытно и полезно посмотреть, что же тебе на самом деле пытаются втюхать. 😊
Только бумажные книжки переведенные в эпоху существования живых советских переводчиков, остальное невозможно читать.
Школьником поверил в машинный перевод, теперь собачий язык учить поздно.
Для работы хватает машинного.
Но литературу переводят как правило несведующие машины, а затем правят далекие от темы люди, получается нынче отвратненько, прямо скажем...
К слову... Смотрел недавно американский фильм "Поезд на Юму" 1957г. Сначала начал смотреть с советским дубляжом... ну и, что-то прямо не так, что-то неуловимо нелогично... начал смотреть современный перевод... так и есть, косяки со словами т.к. перевод губной, вырезано куча кадров. Мда.
"Люби Бога и делай что хочешь."
это не падение, просто в том же английском есть 20 разных английских на которых теперь разговаривают люди со всё падающей культурой речи. Появилась куча динамического слэнга, и привет - от классического английского уже ничего не остаётся, наступила полная эрозия. Применили прямое фонетическое транскрибирование, но (внезапно) оказывается, что у людей и с дикцией-то всё не очень хорошо.
Для нейросетей вроде как раз слэнг не проблема в отличии от классических распознавалок текста в аудио.
Но использованный whisper2 тоже на базе нейросети...
не, они тоже ж0стко фейлятся, и в общем случае, нейросеть должна на лету подхватить диалект, акцент, тематику, слэнг, это слишком дорого пока, наверное. Поэтому откатились на прямую транскрипцию. А виспер работает лучше, потому что там относительно классическая речь, это более простая задача. Ну и в русском эрозии не так много
Мне кажется наличие srt на ютубе всегда было связанно с системой рекомендаций. Когда классификатору стало достаточно упрощенной версии откатились на нее, экономика должна быть экономной. Ну и последние классификаторы смотрят не только на текст но и на всякие смены кадров, цветокор, эмоциональную наполненность и т д, там текст вообще не участвует.
это из комментов доставали, кмк
Ну комменты да, но имхо больше уже для кластеризации полученных классов/векторов.