







Появилась заметка от Сбера про их медицинский ИИ. Мол, все взрослые поликлиники Москвы, уже поставлены диагнозы десяткам миллионов пациентов, «95 наиболее часто встречающихся и значимых диагнозов», "3 наиболее вероятных диагноза из 256 наиболее частых", и прочие успехи на сберовских бюджетах. Но поскольку, в отличие от чат-гопоты, про медИИ особо не пишут, кроме разработчиков Сбера о самих себе, попробую восполнить тему.
Начнём с того, что медицина при капитализме весьма нажористый бизнес, одна только фарма (глобальный рынок около 2 триллионов долларов) обходит торговлю оружием (в пределах триллиона). Поэтому западный ИТ-крупняк не мог пройти мимо медицинских приложений. В тот или иной момент о разработке медИИ заявляли IBM, Микрософт, Амазон, и Гугл.
Но, в отличие от Сбера, крупняк об успехах не отчитывался. Хотя первые медицинские интеллектуальные системы известны с начала 70-ых годов прошлого века, а разрабатывались, соответственно, с конца 60-ых (MYCIN, Internist). Более того, IBM вместо победных реляций несколько лет назад списал в многомиллиардные долларовые убытки свой общедиагностический медИИ, оставшись только в сегменте медицинских изображений (по ссылке один из некрологов https://qz.com/2129025/where-did-ibm-go-wrong-with-watson-health).
Постановка задачи
При этом ответ на вопрос, зачем врачам медИИ, ну или в капиталистических терминах — за что клиент должен платить — особо не сформулирован. Впрочем, это не специфика медИИ, ту же чат-гопоту похоже, разрабатывали ради того, чтобы пройти тест Тьюринга. А то, что получили бредогенератор (оценка Игоря Ашманова), так соответствие информации на выходе реалу не прописано в техническом задании не только у ИИ, но и у барышень, когда они "включают блондинку". Но то, что и "блондинки", и чат-гопота проходят тест Тьюринга, не отменяет вопрос — ну а платить-то клиенту за что? Если с "блондинками" понятно — с ними веселей, то бредогенератор в медицине - это весело?
Поэтому сначала сформулируем, в чем может быть выигрыш медиков от использования ИИ, а потом посмотрим, насколько известные системы, в том числе Сбер медИИ, способны это обеспечить.
Ограниченность мозга против арифмометров можно описать в терминах DIF-анализа (Difficulty – Importance – Frequency, Сложность - Важность — Частота). Попросту, человек хорошо работает с тем, с чем встречается часто, и провисает с тем, что для него редко. На эту тему народная медицинская мудрость гласит, что аппендицит надо вырезать в районной больничке, там на этом рука набита, а не в центре кардиохирургии. Про то же русское народное "сделаешь раз сто - будет просто", и западная буржуйская "learing curve" ("кривая обучения") - снижение затрат в среднем на 13% при удвоении производства 1-2-4-8-16-32...
Соответственно участковые тётки в полубессознательном состоянии после 50+ пациентов за смену
на автопилоте диагностируют массовые ОРВИ/острый бронхит/ХОБЛ/пневмонию - но могут пропустить жизнеугрожающую деструктивную пневмонию, с которой встретятся пару раз за жизнь. И тем более им сложно сходу заподозрить муковисцидоз (если не было скрининга в роддоме), у которого частота примерно один пациент на 10 педиатрических участков, т. е. один случай на несколько поликлиник, а до взрослого состояния с такой болезнью доживает ещё меньше.
То есть, исходя из DIF-анализа, общедиагностические арифмометры для первичного звена здравоохранения надо накачивать тем, что важно (жизнеугрожающие/инвалидизирующие патологии), но редко. Благо, память у железяк хорошая, может вместить 11+ тысяч диагнозов МКБ-10/11, и 50+ пациентов за смену им мозги не вскипятят.
В идеале фельдшер Вася у подножия Хамардабана, потыкав омозолелым от колки дров и вскопки огорода пальцем в экран планшета, должен немедленно прям тут и сейчас ставить диагнозы любой редкости, сложности и важности на уровне топовых экспертов страны по всем разделам медицины. В пределах имеющихся у него методов диагностики - потому что даже в столичных навороченных медцентрах результаты анализов и инструментального обследования в большинстве случаев известны после, а не до первичного приёма врача. Поэтому для медИИ работа с неполной информацией это штатный режим.
Ограничение систем на частотности
А теперь смотрим, по какой колее покатилась фактическая разработка медИИ.
- В упомянутой в первом абзаце заметке от команды СберИИ фигурируют десятки миллионов пациентов, т. е. речь идёт о «больших данных» из взрослых поликлиник Москвы. Но из этих миллионов пациентов вытащили две с половиной сотни «наиболее часто встречающихся и значимых диагнозов», с которыми имеют дело участковые врачи - из 11+ тысяч диагнозов МКБ-10/11. Вместо требуемых по DIF-анализу редких важных патологий. Ну и? За что платить? За то, что участковые тётки без арифмометров с зашкваренным за смену мозгом на автопилоте диагностируют?
- У китайцев ситуация сходная, несколько лет назад была публикация, что обучили железяку пятидесяти наиболее частым диагнозам на всю педиатрию.
- В патенте IBM подбор похожих фрагментов в базе историй болезни на основании частотности, т.е. всё те же «большие данные», из которых вместо редкого и важного вытаскивали наиболее частое.
- Отечественный MEDAI это интернет-вариация системы Нейлора 80-ых годов на частотности.
- Самый первый былинный MYCIN конца 60-ых? Частотность плюс экспертные правила. Причём ещё тогда выяснили, что медицинские эксперты ни частотности не говорят, ни правила не формализуют. Но доблестные ИТ-шники креативно преодолели трудности, обусловленные косностью и жадностью медиков, которые не желали делиться знаниями, и придумали «нечёткую логику» с некими суррогатными «коэффициентами убеждённости» вместо частоты симптоматики. Тогда и родилось знаменитое британское «хайли лайкли».
Т.е. разработка медИИ с самого начала шла на основе столь любимой бриташками со времён вест-индских галеонов байесовщины, когда страховщики оценивали вероятность рисков по цепочке «пожар в порту отбытия — гибель в шторм — захват пиратами — пожар в порту прибытия». Причём риски можно рассчитать ретроспективно, и они не совмещены — утонувшему не суждено ни сгореть, ни быть повешенным. Утрированный пример — любит не любит 50 на 50, плюнет поцелует 50 на 50, даст не даст 50 на 50, итого с вероятностью 87,5% гандон на первое свидание брать не надо.
А дальше всплывают ограничения частотности. Например, статистику собирали на популяции малолеток раннего пубертатного возраста, а рекомендации выданы поручику Ржевскому при визите к мадам «Да, ужас. Но ведь не ужас-ужас-ужас!!!».
Или вылезшее ещё при разработке MYCINа отсутствие статистики — например, какая частота пневмоний у ДЧБД (длительно и часто болеющие дети) из семей с низкими доходами, посещающих дошкольные учреждения за Полярным кругом? Или при болезнях органов дыхания наиболее частая причина повышения температуры это ОРВИ - хотя у конкретного пациента перед врачом аспирационная пневмония.

Да и вообще, откуда статистика по редкой патологии, если она редкая? Вон, в "большой фарме" при клинических испытаниях лекарств от редкой патологии пациентов годами по всему глобусу набирают.
А ведь ещё есть сочетанная патология. Даже без экстрима в виде политравмы берём банальную хронь у населения среднего/старшего возраста из артериальной гипертензии, стенокардии, аритмии, ХОБЛ (хронический бронхит с астматическим компонентом), гастрита, сахарного диабета, мочекаменной и желчекаменной болезни, заболеваний суставов.
| КОЭФФИЦИЕНТЫ СМЕРТНОСТИ НАСЕЛЕНИЯ, на 100 000 населения в 2016 г. |
|
Возраст, 40-44 года |
Возраст, 60-64 года |
Изменение, %% |
|
| Общая смертность | 548,0 | 1 905,9 | 348% |
| Новообразования | 58,1 | 490,0 | 843% |
| Эндокринные заболевания и нарушение обмена веществ | 3,3 | 39,1 | 1185% |
| Заболевания нервной системы | 10,7 | 45,6 | 426% |
| Болезни органов кровообращения | 137,6 | 862,5 | 627% |
| Ишемическая болезнь сердца, инфаркты миокарда | 46,9 | 485,9 | 1036% |
| Болезни органов дыхания | 26,7 | 82,8 | 310% |
| Болезни органов пищеварения | 63,3 | 129,5 | 205% |
| Заболевания мочеполовой системы | 3,5 | 19,2 | 549% |
На это накладываются острые состояния и обострения/осложнения. То же ОРВИ на фоне ХОБЛ может спровоцировать пневмонию, и далее гипоксия потянет утяжеление стенокардии вплоть до инфаркта и/или тяжёлых аритмий, с прилагающейся острой сердечной недостаточностью, и отёком легкого. С чем пациента загрузят в реанимацию, там в подключичку поставят пластиковый катетер, на него сядет полирезистентный стафилококк (ну, живёт он там, нравится ему пластик, стандартный термин «полимер-ассоциированные инфекции»), который далее поплывёт по кровотоку, образуя вторичные очаги гнойной деструкции то ли в легких, то ли в почках. В общем, поверх хрони накладывается всё что угодно, от онкологии и сифилиса до перитонита, менингита и туберкулёза с эхинококкозом — причём везде будет повышение температуры, как при ОРВИ.
А теперь считаем по минимуму. Допустим, "букет" из 3-х патологий, и вопреки DIF-анализу работаем как Сбер медИИ только с наиболее частыми 256 амбулаторными диагнозами, забыв про МКБ-10/11 с 11+ тысячами. Открываем комбинаторику, число сочетаний, без повторов и порядок не имеет значения, формула С=n!/((n-k)!*k!), С=256!/((256-3)!*3!), итого надо знать вероятности/частоту для 2763520 комбинаций (ещё раз, медленно, прописью - больше двух миллионов вариантов). Если не 3, а 5 из 256, то 7+ миллиардов комбинаций. 5 из 1000 — 8+ триллионов. А если 7 из 11+ тысяч? Название для таких чисел есть, не говоря про вычислительные мощности? Причём эти цифры позволяют только оценить количество комбинаций, для которых надо рассчитать вероятности - про собственно постановку диагнозов и речи не идёт. Однако, «факториальный вычислительный взрыв».
Что объясняет, почему ещё при разработке MYCINа вылезло, что у медиков нет ни вероятностей, ни правил. И почему Сбер медИИ рапортует об успехах «3 наиболее вероятных диагноза из 256", а не о сочетанной патологии из 3-х диагнозов из МКБ-10/11. Байесовщина и частотность попросту не тот математический аппарат, который обрабатывает комбинации.
Ещё одна характеристика медицины (впрочем, и других предметных областей) связана с дифференциальной диагностикой. Например, обучаем медИИ диагностике пневмонии. Но пневмония похожа на острый бронхит, на обострение хронического, на застойные явления в лёгких при сердечной недостаточности и на отеки лёгких разной природы на фоне любой лихорадки, на ателектазы и туберкулёз, на онкологию и тромбоэмболию лёгочной артерии. Внутри собственно пневмоний бывают вирусные, от сцинтиовируса до ковидлы, грибковые, бактериальные, паразитарные. Бактериальные пневмонии с деструкцией и без неё, деструкция стафилококковая и клебсиеллёзная, внутри стафилокковых деструкций есть вызванные золотистым стафилококком, и есть — эпидермальным. Такая детализация не абстрактна, потому что всё требует разного лечения, что-то амбулаторного, что-то в реанимации, одни антибиотики против клебсиеллы, другие против золотистого стафилококка, третьи против стафилококка эпидермального. Т.е. одна только пульмонология с дифференциальной диагностикой тянет за собой свыше полсотни диагнозов, которые должен фильтровать медИИ. Сколько там у Сбера? 3 наиболее вероятных диагноза из 256 наиболее частых? На всю медицину, от неотложных состояний до дерматовенерологии (многие патологии, от коллагенозов и менингита до чумы, имеют кожную симптоматику). С дифференциальной диагностикой редких-важных, да?
А как оно там, промеж ушей?
А как же ставят диагнозы участковые тётки? У одного пациента может быть несколько основных диагнозов, для каждого осложнения, плюс сопутствующие диагнозы. Ещё для диагнозов есть клинические формы, стадии, активность процессов, типы течения. Под диагнозами подложка из симптомов и синдромов с их локализацией, интенсивностью, длительностью и динамикой, анамнез и факторы риска… Врачи что, на массовом приёме для всего этого вероятности высчитывают?
Это же элементарно, Ватсон! Смотрим на картинку, и без всякого знания частотностей и вычисления вероятностей понимаем, что вот это собачка, это котик, а вот то мерин и фурункулёз шеи, потому что «златая цепь на дубе том».

То же самое и участковые тётки, смотрят на то, что перед ними, и без частотностей и вероятностей понимают — вот то сопли, вот это бронхит, а тут фурункулёз шеи, потому что цепком натёрло.
Оказывается, кроме вероятностей есть и другой математический аппарат, который называется "линейный классификатор/сепаратор". Если на пальцах, без абстрактных математических функций и не влезая в развесовку коэффициентов, то это табличка с признаками, которые описывают объекты.
|
Зрачок |
Покров |
Когти |
|
| Кошечка | вертикальный | шерсть | втягиваются |
| Собачка | круглый | шерсть | не втягиваются |
| Рыбка | круглый | чешуя | не применимо |
| Насекомое |
неприменимо, фасетчатый глаз |
хитин | не применимо |
-
Во-первых, такая математика работает со множеством объектов, оно же с сочетанной патологией.
-
Во-вторых, для неё нужна не частотность из «больших данных», а уникальные признаки, пусть даже в единственном экземпляре (для того, чтобы научиться не совать пальцы в розетку, достаточно разового непередаваемого ощущения). Ну или уникальное сочетание не уникальных признаков - как круглый зрачок и шёрстка у собачки.
-
В-третьих, при наличии уникальных признаков можно работать с неполной информацией (что актуально для первичного медицинского приёма) — если определили вертикальный зрачок, то можно без шкурки и когтей. А отсутствие когтей позволяет исключить кошечку с собачкой, и далее прицельно дообследовать - то ли посмотреть в глазки, то ли погладить спинку/почесать животик, и поставить окончательный диагноз, кто из них пиранья, а кто скорпион. В медицине это называется «патогномоничные симптомы/синдромы».
- В-четвёртых, «В начале было слово», систему можно обучать как студентов на знании, кристаллизованном в символьно-абстрактном виде - вместо показа эксабайтов и зетабайтов сырых данных в виде картинок с котиками, собачками и фурункулами.
-
В-пятых, сочетание пунктов 2 и 4 позволяет реализовать такие системы на минимальном железе в кратчайшие сроки за счёт тех самых экспертных знаний, которых так жаждет фельдшер Вася у подножия Хамардабана.

"Это факап, бро", или то, что надо?
Исходя из пункта 5, системы на линейном классификаторе можно делать практически в режиме хобби - из своего кармана и во время, свободное от добывания хлеба насущного. По ссылке пример системы, в которой набита пульмонология от острого бронхита до патологии грудного лимфатического протока с обработкой сочетанной патологии, с дифференциальной диагностикой при неполной информации, с наложением троичных логик "Есть/Отсутствует/ХЗ" и "Плохо/Хорошо/ХЗ".
И тут возникает когнитивный диссонас. А чо, те ребята, которые на сберовском бюджете за несколько лет вытащили "3 наиболее вероятных из 256 наиболее частых" из миллионов московских историй болезней не знают о существовании линейного классификатора? Вообще-то о нём отечественным студентам отечественные преподаватели лекции читают. А то, что перед разработкой надо оценить предметную область, вдруг там вычислительный взрыв, неполная информация и дифференциальная диагностика - это секретное знание для тайных посвящённых высших степеней? Ну, в 80-ых годах прошлого века на первой же лекции по базам данных слушателям объясняли, что проектирование системы начинается с моделирования предметной области.
Поскольку у Сбера мощная кадровая служба с опытом рекрутинга 10 тысяч программистов, то вряд ли компетенции оценивали йуные эйчарочки после психфаков и пединститутов на основании "уверенности соискателя в себе". Поэтому логично предположить, что слова про линейный классификатор, вычислительный взрыв и неполную информацию разработчики Сбер медИИ слышали.
Так что вляпывание в частотности и вероятности может быть результатом банального следования модным трендам "все бегут":
Да и карго-культ никто не отменял, у Грефа то "тупицца тим" с аджайлом и скрумингом на 10 тысяч сберовских программистов, то Даня Милохин лицо современной российской молодежи прям как у всего прогрессивного человечества.
В общем, не занимаясь гаданиями кто что почём, итоги разработки медИИ пока можно подвести следующим образом. Первый раз Путин лично публично заслушал о разработке медИИ на заседании Совета по Нацпроектам весной 2015 года. А осенью 2023 года система на бюджете Сбера выдаёт "3 наиболее вероятных из 256 наиболее частых" - при 11+ тысячах диагнозов в МКБ-10/11, без сочетанной патологии, и без дифференциальной диагностики, покрывающей "важно-редко". За это же время пара человек в режиме хобби сделали систему, которая работает с сочетанной патологией при неполной информации с дифференциальной диагностикой, и которую можно наращивать в среднем темпе "один раздел медицины за 2 недели на одного к.м.н".
Управление инновациями, когда через 8 с половиной лет под приглядом Государя у одних бапки без годного продукта, а у других работающий продукт без бапок для масштабирования, можно охарактеризовать по модному, по заграничному: "Это факап, бро". Ну, просто чтобы оставаться в нормативной области великого и могучего.
Правда, это если оценивать от подножия Хамардабана вместо "пиар/навар" для "своих да наших"тм. А если наоборот, без фельдшера Васи и его пациентов, то с инновациями всё хорошо - и с бюджетом придворных не обижают, и картинка "миллионы пациентов" красивая. Однако, свобода выбора логик для принятия решений.
"Пойди туда, не знаю куда, принеси то, не знаю что"
Можно предложить и третий вариант оценки управления инновациями на примере медИИ. Для этого приведём одну из классификаций инноваций:
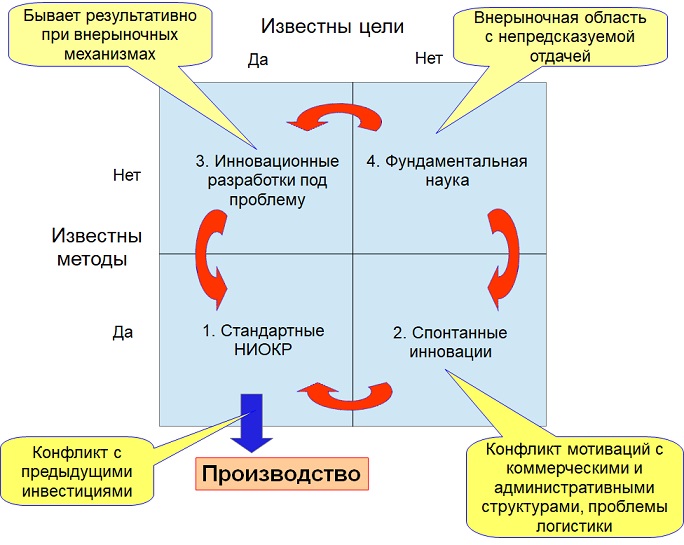
В качестве иллюстрации - был в истории России Государь Иосиф Грозный, который как-то собрал товарищей учёных, и сказал им: "Хочу бомбу, как те, которые американцы сбросили на Хиросиму и Нагасаки. И ещё хочу беспилотные самолёты, как те, которыми немцы Лондон бомбили. А как вы это сделаете, вы расскажете товарищу Берии, он вас внимательно выслушает". На картинке это соответствует полю с номером 3 - известно, что нужно на выходе, но непонятно, как это сделать.
Для того, чтобы выполнить хотелки Государя, из лагерей вытащили Сергея Павловича Королёва. Который в молодости начитался Цандера с Циолковским, на планерах парил аки птица, и в ГИРДе что-то зачем-то запускал, то ли на Марс хотел, то ли просто враг народа, и потому шарахнул ракетой по блиндажу с проверочной комиссией. В общем, Сергей Павлович до призыва в ракетно-ядерный проект шарился в зоне номер 2, где всякие Кулибины и Левши нечто делают, а какая с этого общественная польза, непонятно.
А ещё для выполнения хотелок Государя из поля с номером 4 вытащили отмороженных на всю башку ботанов. Которые удовлетворяли за чужой счёт собственное любопытство "ой, а чойтотам такое черненькое белеется?", и в столовке рисовали на салфетках формулы про строение ядра, которого даже в микроскоп не видно, не то что пощупать.
И под чутким взглядом Лаврентия Палыча вольнопарящие аки птицы из зоны 2 и интеллектуальные беспредельщики-ботаны из сектора 4 сделали атомную бомбу и запустили человека в космос. И теперь Россия по завету хруща кукурузного лепит ракеты как сосиски, чтобы всем хватило, и никто из радетелей за свободу и демократию не ушёл не обиженным Империей Зла (сектор 1, связка прикладные НИОКР/производство, федеральные проекты по микроэлектронике, станкостроению, Уралвагонзавод, Коломна, Комсомольск-на-Амуре и прочие места трудовой славы на необъятных просторах нашей бескрайней Родины).
А теперь позиционируем разработку медИИ в такой классификации инноваций.
Сказать, что не известны методы построения ИИ некорректно. Теорема Байеса это 1763 год, а Ллойд отметился на страховании британского пиратства и работорговли ещё раньше, с 1693 года. Тот же медИИ от Нейлора это 80-ые годы прошлого века - и в рамках загруженной в него частотности оно работало.
Линейный классификатор это одно из приложений линейной алгебры, на которой ещё в 19 веке в Российской Империи межотраслевые балансы начали разрабатывать, и на методах оптимизации во Вторую Мировую рассчитывали бомбовую нагрузку авиации. Так что поле 4 отпадает по причине понимания того, как можно сделать.
Скорее, речь идёт о непонимании того, что надо от разработки, т.е. медИИ находится в поле 2. В котором методом тыка прикручивают к предметной области то, кто что умеет. Бриташки умеют в частотность с байесовщиной - в MYCINе и системе Нейлора её и прикрутили. Те, кто умеет в линейный классификатор - приспособили его к распознаванию изображений, в том числе медицинских. IBM научился по частотности предсказывать следующие слова - стали подбирать похожие куски в массиве историй болезни. Герман Греф почётный каргокультист России - получили копипасту западоидных систем на частотности в виде Сбер медИИ. Кто-то с опытом в медицине опухел от частотности: "А чо, участковые тётки вероятности высчитывают? Да не, бред какой-то!" - и прикрутил линейный классификатор к медицинским экспертным знаниям, представленным в абстрактно-символьном виде. Т.е. в наличии типичный для поля 2 рабочий хаос "пойди туда - не знаю куда, принеси то, не знаю что".
Управленческие методы работы с неопределённостью в полях 2 и 4 известны. Российские Государи посылали небольшие казачьи команды в направлении восходящего солнца за Урал "под российским небесным флагом нас вывозит Авось!". Иосиф Грозный содержал шараги, в которых небольшие группы параллельно работали над сходными проектами. Нынешние транснацики финансируют рой небольших университетских лабораторий. Западоидные инвесторы вкладываются в рой небольших стартапов. Т.е. во всех случаях речь идёт о множестве относительно дешёвых независимых групп, для каждой из которых успех не гарантирован, но расчёт на то, что кто-то из роя сделает прорыв. И только потом можно со всей госдуревой/транснациковой дури ломиться в уже открытую дверь (поля 3 и 1) .
Т.е. c управленческой точки зрения ошибка IBM и отечественного государства в лице Сбер ИТ не в том, что они вляпались в частотность - пока не сделаешь, не узнаешь, что заработает, а что нет, это не прикладные НИОКР из сектора 1. А в том, что для работы с неопределённостью вместо роя из мелочи были вброшены массивные ресурсы в единственный вариант, как будто уже имелись гарантии успеха, как у Сталина, который знал об успешной реализации ФАУ и атомной бомбы. Есть и вторая ошибка, уже только Сбера - там, где IBM честно сказал "ну не шмогла я, не шмогла", и списал миллиарды зеленью в убытки, Сбер рисует радужную картинку "3 наиболее вероятных из 256 наиболее частых" с миллионами пациентов.
А при чём тут Рикардо и демография?
Можно взглянуть на ИИ в целом, и медИИ в частности с точки зрения общего развития человечества. Ешё до Маркса был такой Рикардо, который писал об аккумуляции предыдущего труда в орудиях производства. Один объем труда аккумулирован в топоре, другой в бензопиле, третий в лесоповальном комбайне.
Причём чем дальше, тем больше аккумулируется интеллектуальный труд. Знания для производства топоров передаются внутри кузни, а знания для массового производства бензопил уже имеют под собой пирамиды из подготовки спецов от геологоразведки до сопромата и логистики - Сфера знаний и технологий имеет степенные функции по поверхности и объему:
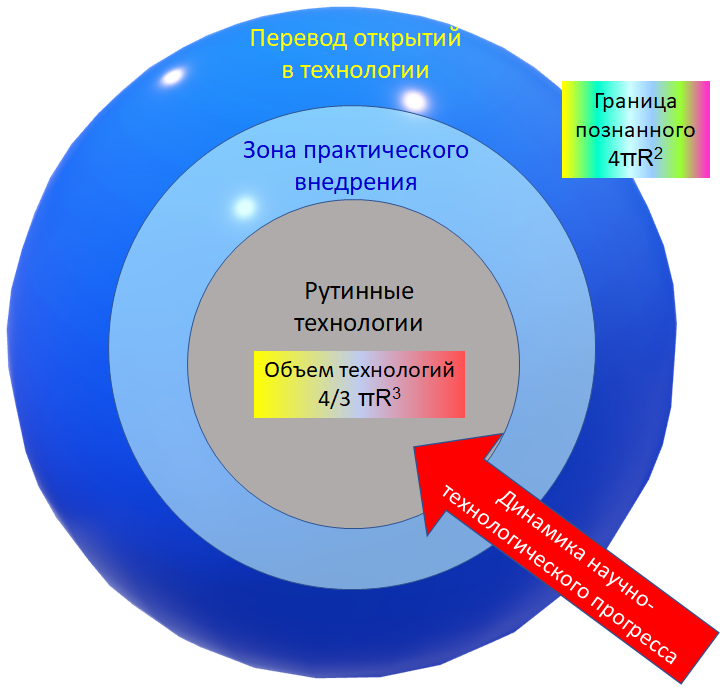
Что напрямую отражается на демографии. Там, где раньше профессионально коровку доили и сено скирдовали в 15 годков, и, соответственно, выходили на уровень экономической самодостаточности, теперь на уровень среднего профессионализма выходят к 25 - 30 годам.

Механизмы аккумуляции интеллектуального труда в обществе, будь то книгопечатание или образование от детсадов до формирования научно-инженерно-технологических школ позволяет человечеству наращивать доступную для него Сферу. При таком взгляде ИИ это логичное развитие систем аккумуляции и распространения предыдущего интеллектуального труда. Которое позволяет меньшим количеством народа работать с нарастающими специализированными знаниями, передавая их от единичных экспертов штучной выделки широкому слою пользователей, в том числе фельдшеру Васе у подножия Хамардабана.
Так что развитие ИИ относится к стратегическим направлениям для успеха страны вдолгую.
А как это делать, пусть думают государевы люди, они деньги за это получают. Может, надо дополнительно 100 миллиардов Сберу выделить на развитие ИИ? Может, пусть ВТБ, Сбер и Мэрия Москвы организуют хакатон на базе Сколково для разработчиков медИИ с общим призовым фондом в один миллион рублей для пяти лучших команд? Может, ещё какие идеи есть, или появятся в будущем?
Комментарии
Это тупиковый путь. Простая статистика непонятного будет давать много ошибок. Если болезнь изучена, механизм понятен, то у нее найдутся бесспорные симптомы. По ним определить ее сможет и врач, и ИИ.
Проблема в том, что механизм самых злобных болезней, онкологий, ССЗ, ХОБЛ либо вообще непонятен, либо описывается десятками противоречивых признаков. Врач ставит диагноз по инструкции, и за свою ошибку не отвечает. А на ИИ посыпятся все шишки.
По логике ответственность у ИИ на экспертных знаниях не больше, чем у учебника или авторов инструкции - которые по сути тоже экспертные знания.
Другое дело что арифмометр может аккумулировать экспертные знания в таких объемах, которые в одну голову не влезают.
Да, это так. Но грамотные пациенты не будут верить этому ИИ. Уже 40% не ходят и к врачам, обращаются лишь в крайних случаях, а в остальных - лечатся сами. На врача можно нагавкать, на инструкцию - нажаловаться, а перед ИИ пациент абсолютно беспомощен. ИИ сказал "в морг" - значит в морг. Жалобу на него не примут.
МедИИ вообще не должен работать в автономке, только в качестве поддержки для медика. Та система, которая указана по ссылке в тексте, в явном виде указывает пробелы в симптоматике, закрытие которых позволяет дифференциальную диагностику с той или иной сходной патологией. Сама железяка эти пробелы не закроет, и, в отличие от системы Нейлора/MEDAI, самостоятельно не убирает из поля зрения врача симптоматику и диагнозы, даже сильно не похожие. Потому что при дообследовании много чего вылезти может, и тогда оценки сместятся.
Это возможно. Но что делать врачу. когда он видит, что ИИ ошибается?
В системе по ссылке в явном виде представлена симптоматика, почему железяка указывает на тот или иной диагноз, включая пробелы в обследовании. Если пробелов в обследовании нет, а врач несогласный, то либо врач не прав, либо патология выходит за рамки того, чему обучена железяка. Поэтому нельзя обучать систему одной патологии, или их узкому набору а-ля "3 наиболее вероятных из 256 наиболее частных", или "дата сет для обучения сепсису" на сайте МЗ РФ. Та система, которая по ссылке, обучена пульмонологии с пробелами в симптоматике, с сочетанной патологией и диф. диагностикой - но без рикошета по легким от сердечных дел, интоксикаций, паразитологии и других органов и систем, поэтому там вывешено предупреждение, что демонстрационный вариант.
В любом случае, арифмометр работает только в рамках того, что в него ввёл врач, который имеет возможность обследовать пациента, соответственно конечная ответственность на враче, и он имеет полные юридические права и ответственность посылать на й арифмометры, учебники и инструкции.
В общем, роль арифмометра расширить диапазон того, чем оперирует врач при диагностике, а не принимать решение за него.
Да, ИИ должен работать справочником. Не снимая с врача ответственности. Потому что в нем всегда будут ошибки.
ИскИны НЕ должны "ставить диагнозы" - они должны валидизировать диагноз жЫвого врача.
Т.е. что бы "замотанная тетка из поликлиники" решила написать ОРВИ, а у неё в компе вдруг вспыхнула предупреждающая табличка: "Тётя!!! Внематочнее!! А то вот на этом случае (есть вероятность) дипломчик посеешь!"
И фсё.
P.S. И давно мечтаю о автоматизированной системе предприёма пациентов. Т.е. человек приходит в поликлинику, заходит в зал-холл, а там кабинки, меж которых ходит медсестра-консультант. Он, болезный, заходит в кабинку и понеслась! На выходе он имеет талончик к специалисту+направление на анализы+ если нужно - ЭКГ,спиро, пульсокисметрию, вес/рост и т.д. Вот ТУТ ИскИн вписался бы просто отлично...
ИМХО, вы не совсем понимаете, как работают нейросети.
Начхать им глубоко на количество комбинаций...
Сетка, по тому сколько раз и в какое время вы доите корову, какие передачи смотрите по ящику и цвету волос вашей бабы может определить, что у вас ХОБЛ
Там участвуют связи, о наличии которых вы даже не подозреваете...
Не, я не спорю, что волхвы по звездам определили, в каком именно хлеву и когда именно родился младенец Иисус.
Берем матрицу размером во Вселенную, в одном куске там прописано движение светил, в другом куске рождение Христа, по известному куску реконструируем пропущенные данные - вот и здравствуй, младенец Иисус!
Правда, на случай встречи с прокурором хотелось бы несколько иной аргументации в постановке диагноза, чем дойка коровы, которой у меня нет.
Это уже где-то было...
Про прокурора и нейросети.
Законодательство изменят и все.
Уже меняют, пока под беспилотные грузовики.
За ними пойдут легковушки.
И где-то там в очереди медицинский AI.
И по другому тут никак.
Вам, конечно могут вывалить итоговую функцию, только какой вес в ней за что отвечает, даже Богу не известно, просто потому, что так даже вопрос ставить нельзя в данном случае.
Будет по-другому.
Введут "ГОСТы" - столько-то ответов, удовлетворяющих критерию "не навреди", - даже не "помоги", а остальным X% просто не повезло и запустят в пром.
Ну плюс страхование ответственности. Так оно и сейчас есть...
На это и государство может раскошелиться, пока все только начинаться будет.
И никаким луддитам этот прогресс не остановить
Видите ли, помимо прокурора врачи ещё иногда хотят почесать свою гордыньку, как они классно лечат - но постановка диагноза на основе дойки коровки и просмотра телевизора в это не вписывается.
Впрочем, никто не мешает лично вам получить медицинское образование и лечить на основе подобной симптоматики.
Перестаньте очеловечивать роботов! Никакого изменения законов для автомобилей-роботов НЕ НАДО. Потому, что есть ПДД. И робот должен всегда, при любых условиях их соблюдать. Т.е. робот всегда неуиноват!!! А если он нарушит ПДД, еще и, не дай Перун, с последствиями, то отвечать должен тот, кто так его запрограммировал - т.е. всегда человек.
Вы бредите.
При чем тут нахрен вообще ПДД..?
Всем глубоко насрать на ПДД.
И автору статьи тоже.
Вопро совсем другой: КТО будет отвечать за трупы?
А по ПДД их штабелями навалили или нарушая - никого не волнует.
И вот уж кто точно не будет за это отвечать, так это программисты.
Посадите одного программиста и завтра будете звонить по проводному телефону и кричать в трубку "барышня, соедините". И это только цветочки...
Вы абсолютно не знакомы со спецификой производства ПО.
Щаз разберемся. кто тут бредит..
При том, что ответственность наступает по закону. На дороге закон - это ПДД.
Не нарушены ПДД - НЕТ ОТВЕТСТВЕННОСТИ.
Так яснее, кто тут бредит? А если нет ответственности, то не о чем и говорить... А робот нарушить закон не может - это может сделать только программист этого робота.
Добрый день!
Спасибо! Интересный взгляд, согласен. Искать, заподозрить _ редкое_- поможет сдвинуть ситуацию принципиально, сделать помощника для медиков.
А "помощь для самолечения" типа "у Вас вероятно ОРВИ, артрит и гипертония"- и правда очевидны и врачам, и самим людям...
Вы упустили (или недостаточно подчеркнули) такое явление, как суженность мышления профессиональных дата-сатанистов. Они НИЧЕГО не знают, кроме нейросетей и соответствующих питоновских библиотек. Ибо - символ веры у них такой.
===============
Лично читал статью нейросетеплётов, которая ясно указало на то, что они - занимаясь компьютерной обработкой речи!!! - не слышали о теореме Котельникова/частоте Найквиста.
Причем дата-сатанисты попались честные - они в статье явно написали, что не понимают причин расхождения результатов двух экспериментов.
================
Сбер - активен, креативен и остромоден.
Поэтому он, разрабатывая медИИ, принципиально не заморачивался ознакомлением с предметной областью.
Понимаете, это - символ веры такой. Дата-сатанисты веруют в то, что вся необходимая для решения информация представлена в обучающем корпусе.
Это - безумная идеализация, но иначе им никак. Одни и те же люди плетут нейросети для разных предметных областей, а хотя бы поверхностно с ними знакомиться - это ж надо время и труд тратить. Лучше добавить десяток стандартных блоков в нейросеть.
Да куда уж больше, я ж в явном виде указал, что ещё в 80-ых прошлого века на первой же лекции по базам данных говорили, что разработка системы начинается с модели предметной области. Без этого нынешние вляпались в факториальный вычислительный взрыв, неполные данные и отсутствие дифференциальной диагностики.
Вот тут Вы совершенно правы. Моделей нет, но программистам сильно кушать хочется.
Да блин же ж... всё, что требуется - почитать написанное на тему Экспертных Систем лет тридцать назад. Если б наработанное тогда применить сейчас. "Это стол? Это стул? Это кот? Это кит?"
Я в своё время примерно прикидывал, как уложить это в обычные таблицы типовой СУБД - и нормально получалось. Справочник симптомов, справочник диагнозов - и пары из них в отдельной таблице. Выбираешь симптом, делается выборка в парах, отбираются возможные диагнозы, по ним делается выборка свойственных для них симптомов - и выдаётся списком для врача. И дальше отбираются только те диагнозы, где встречаются отобранные из указанных в списке симптомы. Несколько итераций - и ответ получен.
Собственно, схему легко доработать до "присутствует/не присутствует/хз". Вполне очевидная, легко реализуется - а данными набивается хотя бы теми же студентами.
Чистая база данных без развесовки не прокатит, см. пример в тексте, где удельный вес вертикального зрачка у кошечки, и уникальное сочетание "круглый зрачок+шёрстка" у собачки перекрывают всё остальное - что позволяет работать с неполными данными и сочетанной патологией.
Плюс в реальной медицинской системе многоэтажный конструктор по переводу симптомов то ли боль то ли кашель то ли одышка с уточнениями а-ля слева/справа/ночью/утром/при физической нагрузке/в покое/при месячных в синдромы со многоуровневыми вложениями логической обработки и/или, и "Есть/отсутствует/ХЗ" с интерпретацией "плохо/хорошо/ХЗ".
Хотя таки да, для того, чтобы убедиться, что можно реализовать систему для сочетанной патологии с неполными данными, модельку сбацали без программирования в Акссессе, чисто студенческий уровень.
А вот сажать студентов на семантику не стоит, всё равно эксперту платить, после них вычищать - ну и зачем лишние расходы на студней?
Ну, можно добавить в справочник сочетаний поле "Удельный вес", проставлять его для симптома в диагнозе - и уточняющий список сортировать по этим весам. Более того, в справочник сочетаний можно добавить поля с комментариями спеца - так что, наводя на симптом, врач мог увидеть его (спеца) соображения. По факту, это был бы справочник с продвинутой системой отбора. А если бы там ещё были ссылки на примеры из практики, так и вовсе было бы идеально.
В тексте есть ссылка на систему, которая работает с пробелами симптоматики, сочетанной патологией и дифференциальной диагностикой. Она всё объясняет на выходе как вы пишите (ну, без примеров, у врача на приёме примеры перед ним, и в коридоре сидят) - но только при её обучении медицинскому эксперту не надо себе голову коэффициентами забивать, вычислительное ядро само развесовку делает.
А мы фактически уже подошли к моменту SIFO(shit in shit out), когда полный цикл обучения мульти модальной модели невозможен. Есть итоговые черные ящики от больших игроков и их пытаются встроить в необходимую задачу + параллельно экономя вычислительные ресурсы.
И тут возникает рекомендация поручику Ржевскому не брать гандон на первое свидание к мадам из анекдота "Да, ужас. Но ведь не ужас-ужас-ужас!!!". Потому что никто не проверял, что обучающая выборка для чёрного ящика у транснациков совпадает с контекстом практического применения в Больших Бебенях.
Так и я аПчем. Уже давно невозможна верификация и на базе одних черных ящиков генерируются другие. Те модели вроде как есть а методологий, датасетов нет. Как они признаки отбирали, как нормализировали, как ошибку считали тайна великая ) А как итог подопытной модели скармливаешь фотку с болезненным ожирением, а она тебе отвечает, на фотке немного полноватый гендерно-нейтральный хуман )
:)
Тут надо идти последовательно. Сначала автоматизировать бесспорные вещи, диагнозы с хорошо изученным механизмом. А потом изучать то, что пока не бесспорно.
Да тут уже все отработано, сперва настраивается сбор первички, далее классификация-кластеризация, далее прогнозирующие модели, далее QA модели. И это работает с текстом картинками-видео, даже сопроматом. А вот мед данные, мнится мне, упираются в кучу законодательных запретов. Нужна проводить обезличивание и т д. + Верификация прогнозов и прочего требует экспертной оценки, это не просто увидеть светофор на картинке или прослушать текстовый отрывок.
Мед данные упираются в сочетанную патологию, неполную информацию, и дифференциальную диагностику.
А их типа дают первому встречному DS )? И Все эти законы о перс и мед данных тут не работают ?
Ps я просто не имел касательство к мед данным, интересно.
Вон, Сбер деперсонализированные данные с миллионов историй болезни обрабатывает "3 наиболее вероятных из 256 наиболее частых", на сайте МЗ РФ выложены дата сеты от питерского центра Алмазова по отдельным патологиям, MEDAI перекладывает Нейлора на интернет по крайне мере с 2004 года.
Ну и? Хотите встать в очередь за MYCINом, Нейлором/MEDAI, IBM, Сбер медИИ и прочими "все бегут"?
Да боже упаси. Я уже давно не верю в фразу "Все легко и просто", всегда есть нюансы и подводные камни. Вот и интересуюсь у разбирающегося человека. )
Если отработано, надо внедрять. Не торопясь.
Было бы отработано, IBM не списал бы миллиарды зеленью в убытки, и в лидерах числились бы Микрософт, Амазон и Гугл. А пока только Сбер медИИ рапортует об успехах "3 наиболее вероятных из 256 наиболее вероятных" - при 11+ тысячах в МКБ.
Чисто оффтопом. Вы сравниваете теплое с мягким. IBM решил делать все и сразу. MS/Amazon пока строят инфраструктуру на базе общедоступного железа, обкатывают на GPT. Google занимается разработкой железа сам, обкатывает на Midjourney. Те транснацки пошли по пути выстраивания инфраструктуру, а не попытки объять необъятное.
А сбер... Я честно не знаю, как у них с этим медИИ, но уж больно часто они мышей рожают.
Что инфраструктура сделает с факториальным вычислительным взрывом, пробелами в симптоматике на первичном приёме, и отсутствием частотности по редкой-важной патологии?
Это был оффтоп.
Вообще-то это по теме, разные стратегии разработки ИИ под разные задачи.
Какие задачи у чат-гопоты не очень ясно, даже чисто информационное обеспечение с учётом бредогенерации не прокатывает. В другом случае фельдшер Вася на уровне сразу всех топовых экспертов.
Надо идти по МКБ-10/11, если там есть, то кто-то что-то об этом знает. Хотя на практике эксперты лезут глубже МКБ (например, там нет разграничения между пневмониями, вызванными Pseudomons aeruginosa и Burkholferia cepacia - обе НГОБины, а антибиотикотерапия радикально разная), а фельдшера поверхностней. В идеале медИИ должен выводить фельдшеров на экспертный уровень.
Во всяком случае, МКБ надо брать в качестве главного ориентира.
Все упирается в датасеты. Из пары миллионов смогли надергать данных лишь на 256. И если с картинками/текстами можно посадить тысячи обезьянок за 3 копейки, то с мед данными видимо все гораздо сложнее.
"С мед данными видимо все гораздо сложнее"
Потому что сочетанная патология с факториальным вычислительным взрывом, если обрабатывать на методиках для частотности, дифференциальная диагностика с тем, что выходит за пределы того, что МЗ РФ выложил в качестве дата-сета для обучения арифмометров сепсису, и неполные данные, потому что на первичном приёме еще нет ни анализов, ни снимков и сканов.
Ну да, что-то такое я и подозревал.
Очень интересная выкладка про демографию, да и вообще хорошо написано, спасибо, перечитаю ещё!
Спасибо, я старался
давным давно, мы с мужем только расписались, и его послали в командировку в ригу( в ссср еще) в качестве ит специалиста при врачах. Посчупать такскать систему первичной диагностики для диспансеризации населения, коя тогда в латсср пробовалась.
Касмон называлась. Там было что-то вроде как аффтар описал. Анкета с вопросами типа да нет незнаю + первичные данные рост вес возраст давление. И на основе некоторой модели система выдавала направления к узким специалистам. Муж даже привез тексты программ на бейсике для искры 226. Там этот девайс тогда использовался. Вот это уж лет скоро сорок назад.
У того же Нейлора, который 80-ые годы, линейный классификатор строчек на 90 на бейсике. Правда, свой медИИ он сделал на частотности на 800 строчек. Статистик, однако, без понимания медицины.
Опять же - а за што должен платить клиент? Вопрос не только не стал яснее, после прочтения текста, а гораздо более запутался. Чего же конкретное все эти цЫфровики-финансисты должны сделать, штоб медицЫна перешла на новый уровень, не технологический (с этим всё просто), а медицинский? Пока просматривается только углубленный сбор персональных данных, желательно в онлайн режиме...
По логике платить надо за то, чтобы фельдшер Вася у подножия Хамардабана работал на уровне лучших экспертов страны сразу по всем разделам медицины.
А что для этого надо финансистам от цифры - может, их это вообще не интересует?
Ну, т.е. цель технологически недостижима. Точнее, для этого фельдшер Вася должен уметь работать на указанном уровне, на базе знаний полученных им при обучении и дальнейшем самообучении. Т.е. опять - цель недостижима. Финансистов от цЫфры очень волнует некоторые, секторальные аспекты медицЫны, но сама медицина, канешно, нет. Учет и контроль на новом технологическом уровне...
Страницы