






Заметка писалась как ответ на "GPT-4 тупеет на глазах", где автор нагородил далеко идущих выводов, перенервничал и успел меня забанить.
Тема хайповая, появляется всё больше дилетантов очень желающих что-нибудь написать на тему, и чем "сенсационнее" и жаренней выводы - тем быстрее распространяется такая статья, без оглядки на её достоверность. Так происходит во многих горячих темах, но здесь проявляется особенно ярко, тк отсутствие технических знаний пытаются подменить философией и житейскими аналогиями.
Заявлявемые автором исходной статьи тезисы, каждый из которых является ложным:
1) GPT-4 "тупеет".
2) Обилие сгенерированных данных в интернете станет непреодолимым препятствием для обучения нейросетей.
3) Область больших нейросетей/больших текстовых моделей достигла насыщения.
Первое: "GPT-4 тупеет", откуда появилось такое утверждение?
А ниоткуда, журналисты придумали, неправильно прочитав исследование, разнеся громкий заголовок по интернету и породив волну.
Вот исходное исследование, озаглавленное "How Is ChatGPT’s Behavior Changing over Time?"
Во вступлении к которому сразу заявляется:
Our goal here is not to provide a holistic assessment but to demonstrate that substantial ChatGPT performance drift exists on simple tasks.
Т.е. в исследовании изначальная цель заявлялась именно как обнаружение (негативных) изменений между малыми версиями, а не в оценке результатов или "умности" модели в целом.
Что проверялось:
1) Решение математических вопросов по заданному алгоритму - ухудшение. GPT-4 перестал исполнять часть запросов на момент исследования. На данный момент проблема частично исправлена, но всё ещё присутствует. (GPT-3.5 сильно улучшил результаты в тот же период.)
2) Ответы на запросы по генерации чувствительного/оскорбительного контента. В GPT-4 появилась заглушка "я не буду отвечать на это". Не "отупение" модели, а целенаправленная заглушка. (В GPT-3.5 заглушки нет.)
3) Генерация кода. По исследованию - заявлено ухудшение, тк код перестал проходить их автотесты. В реальности - код в ответе начал предваряться блоком комментария, обозначавшим что начинается код, что ломало проверку. Это изменение, но не ухудшение. Если исключить этот комменатрий и отправить на проверку сгенерированный код - результат GPT-4 существенно улучшился. (GPT-3.5 - результат улучшился.)
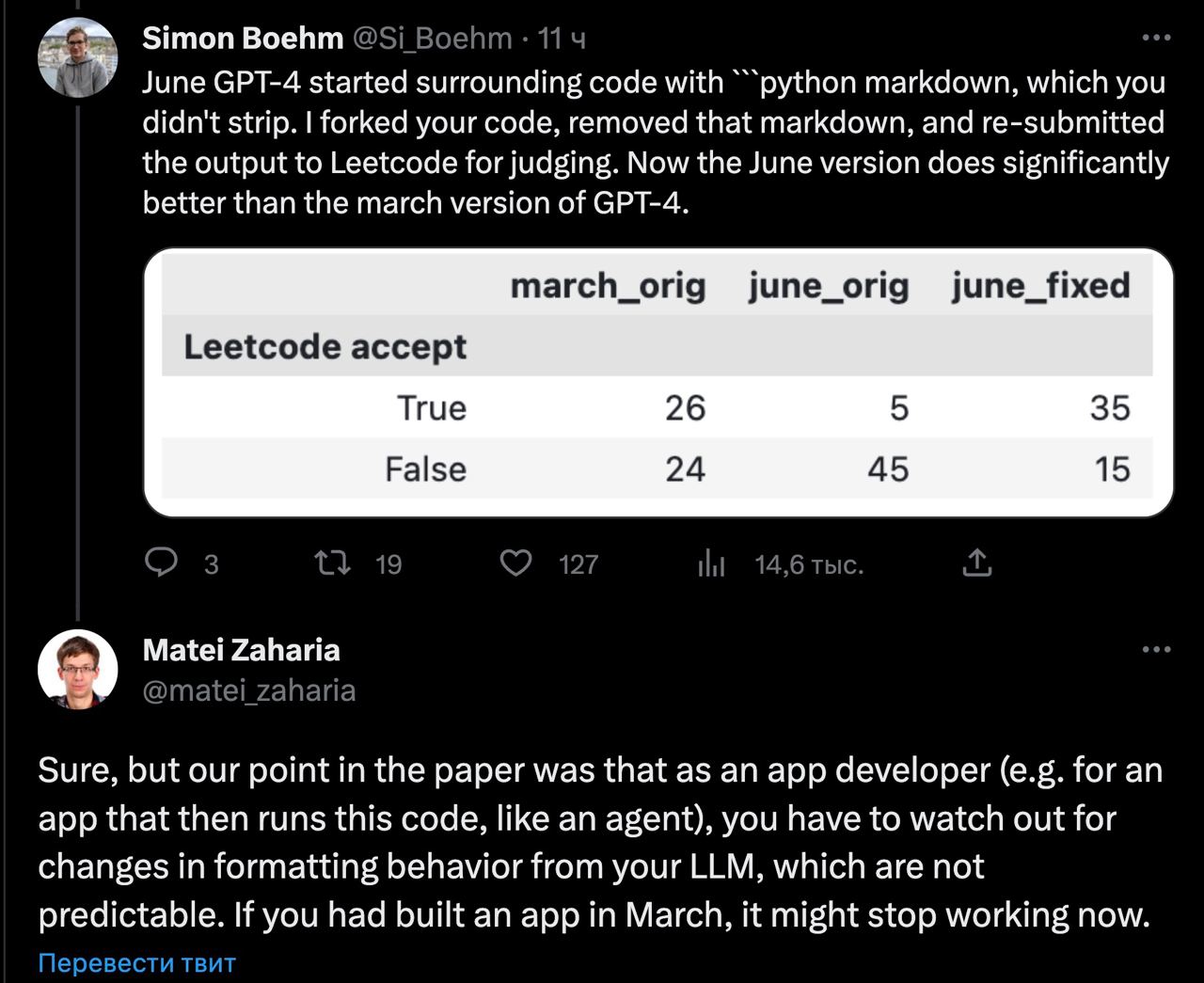
Ответ автора исследования - да, так и есть, но проверялась не точность ответа а его изменение. И суть исследования в том что возможность таких изменений программистам придётся учитывать.
4) Решение визуальных задач - небольшое улучшение количества правильных ответов, но некоторые с правильными ответами ранее стали решаться неправильно. (GPT-3.5 - результат улучшился аналогично.)
Ответ разработчиков на это исследование и последовавшую волну:
https://openai.com/blog/function-calling-and-other-api-updates
While the majority of metrics have improved, there may be some tasks where the performance gets worse. This is why we allow API users to pin the model version. For example, you can use gpt-4-0314 instead of the generic gpt-4, which points to the latest model version. Each individually pinned model is stable, meaning that we won’t make changes that impact the outputs.
That said, our evaluation methodology isn’t perfect, and we’re constantly improving it. One way to help us ensure new models get better at domains you care about, is to contribute to the OpenAI Evals library to report shortcomings in our models.
Большая часть метрик улучшилась, в некоторых задачах могли быть ухудшения. Если нужны именно эти задачи (на которых разработчики не фокусировались) - можно указывать конкретную версию сети к которой задаёшь вопрос. Если хотите чтобы следующая версия сети лучше решала именно ваши задачи - вносите их в список метрик для проверки будущих сетей.
Итого: GPT-4 в новой версии стал "умнее", что особенно ощутимо в кодогенерации, на которой был сфокусирован текущий апдейт, но при этом сломали несколько ранее работавших моментов, что на данный момент чинят. При этом есть возможность обратиться к старой версии, и она, как и все предыдущие, никуда не исчезла у разработчиков.
Из исследования выше СМИ раздули "GPT становится тупее", вообще не разбираясь в вопросе и подавая это как непрерывный процесс.
Второе: (Якобы) Обилие сгенерированных данных в интернете станет непреодолимым препятствием для обучения нейросетей.
В исходной статье есть ссылка на статью в forbes, в которой дан на удивление неплохой анализ, но из которого автор статьи на АШ вырвал наиболее жаренные куски, оставив "неудобные" для него пояснения за бортом.
В чём состоит проблема, вкратце:
Стандартные методы обучения заточены на обобщение разнообразных данных и устранение шумов, если на входе данные уже обобщённые тем же способом (из выхода той же нейросети) - результат будет ещё более обобщённым, теряя детали и фокусируясь только на контрастах.
Здесь хорошая иллюстрация, последующее изображение строится на базе предыдущего, привожу пропуская шаги:





Эффект можно уменьшить или совсем обойти уменьшая шумоподавление, это потребует бОльших затрат по времени в случае обучения модели с нуля, но не является чем-то непреодолимым. Эффект давно известен, так же как и методы его обхода, что, кстати, указано в исходной статье forbes:
Опрошенные эксперты признают проблему некорректного обучения ИИ, однако не склонны ее драматизировать. «Проблема «шумных» данных была в машинном обучении всегда, начиная с классических моделей, — поясняет директор по ИИ и цифровым продуктам «Билайна» Константин Романов. — Однако сейчас ей стали уделять более пристальное внимание. Связано это с тем, что такой выход модели, как «текст» или «изображение», человеку проще оценить критически, нежели некоторые числовые выходы». По мнению ведущего инженера NLP Just AI Константина Котика, то, что ИИ обучается на данных, сгенерированных самим же ИИ, не значит, что нейросети начнут деградировать. Он напоминает, что многие существующие модели, подобные тем, что заложены в ChatGPT, были получены за счет обучения на текстах, сгенерированных с помощью СhatGPT, например известная модель от Стэнфорда Alpaca. «Скорее нужно контролировать качество данных, а не ограничивать использование синтетических данных», — полагает он.
Во время обучения генеративные модели создают данные, которые могут быть очень полезны для продолжения настройки, но, как и любая технология, они имеют свой предел эффективности, говорит ведущий научный сотрудник Института AIRI и директор центра технологий ИИ Сколтеха Иван Оселедец. «Коллапсом модели» называют ситуацию, в которой система зацикливается и бесконечно повторяет существующие шаблоны вместо генерации новых результатов, объясняет он: «Создатели генеративных моделей (не только языковых) уже научились предотвращать «переобучение», когда модели чересчур подробно усваивают обучающий набор данных и не могут обобщить эти знания с учетом новых, выдавая в результате ошибки и галлюцинации».
Там же есть и пессимистичные отзывы, но они в большинстве сводятся к паре тезисов: Да, для более простого обучения новых моделей хорошо бы если бы в интернете сгенерированный нейросетями контент как-то помечался, но это будет проблемой только для тех кто "догоняет" текущих гигантов, не имея изначально чистой выборки для первичного обучения, и не имея достаточно денег чтобы сопоставимую выборку очистить вручную. Есть и технические решения данного вопроса на уровне самой нейросети, что решат проблему, но замедлят обучение, что опять же выльется в то что догонять лидеров будет сложнее/дороже.
Дополнительно: на данный момент мало исследований о кросс-обучении сетей разной структуры, и насколько могут разнородные сети обучаться на выходе друг друга. Положительные результаты есть (Alpaca), но насколько далеко простираются - исследований не видел.
В исследованиях на тему, на которые ссылается статья, как вот это явно указывается в выводе что проблема не глобальная а только для случая попытки тренировать сеть стандартными методами на не очищенных данных взятых напрямую из сети, не имея данных собранных до "загрязнения" их сгенерированными:
We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web.
Otherwise, it may become increasingly difficult to train newer versions of LLMs without access to data that was crawled from the Internet prior to the mass adoption of the technology, or direct access to data generated by humans at scale.
Это никак не мешает обучению на очищенных данных, но доставит проблемы тем кто не может себе позволить создать/купить такой очищенный датасет. Крупные компании в любом случае тем или иным способом выборку фильтруют.
Итого: Проблема есть, давным-давно известна, ничего непреодолимого из себя не представляет. Из дискуссионной статьи в форбс и нескольких тривиальных публикаций раздуто автором на АШ в якобы фундаментальную проблему нейросетей.
Третье: (Якобы) Область больших нейросетей/больших текстовых моделей достигла насыщения.
Автор заявляет это в таком виде:
О том, что эта область достигла своего уровня насыщения и дальше может наблюдаться если не откат, то как минимум плато, свидетельствует еще один немаловажный факт. Глобально сфера ИИ — одна из самых щедро инвестируемых, однако в 2022 году показатель объема частных вложений в эту область сократился впервые за десятилетие. Так, в прошлом году инвестиции в ИИ в мире составили $91,9 млрд, это на 27% меньше, чем в 2021 году, когда показатель составлял рекордные $125,4 млрд, говорится в отчете Стэнфордского университета «Индекс искусственного интеллекта-2023». При этом прошлогодний показатель в полтора раза выше уровня 2020 года и в 18 раз — 2013 года.
Автор путает бум вложений и насыщение самой области. Когда GPT, его аналоги и генераторы изображений показали неожиданно высокие результаты - множество тех у кого были деньги попробовали впрыгнуть в последний вагон, попытавшись залить деньгами отставание от лидеров. У некоторых в узких областях это получилось, у большинства - нет. "Внезапно" выяснилось что догнать сети под крылом гугла или майкрософта сложно и дорого, и что если раньше контора из десятка человек за счёт новизны области могла сделать прорыв "в гараже", то сейчас чтобы выдать хоть отдалённо сопоставимые результаты, претендующие на какой-то коммерческий успех - нужно вкладывать существенные деньги, с далеко не гарантированным возвратом, тк крупные конкуренты развиваются быстрее.
Если же говорить про сети следующего поколения - ценник возрастает ещё на порядок-два.
Из отчёта университета стэнфорда:
Large language models are getting bigger and more expensive. GPT-2, released in 2019, considered by many to be the first large language model, had 1.5 billion parameters and cost an estimated $50,000 USD to train. PaLM, one of the flagship large language models launched in 2022, had 540 billion parameters and cost an estimated $8 million USD—PaLM was around 360 times larger than GPT-2 and cost 160 times more. It’s not just PaLM: Across the board, large language and multimodal models are becoming larger and pricier.
GPT-2 - вход в тему стоил 50000$, PaLM-1 от гугла примерно равный/проигрывающий GPT-3 - уже 8 миллионов $, GPT-4 - на 1-3 порядка больше чем GPT-3, цена обучения неизвестна. Коммерчески конкурировать с таким много сложнее и много меньшее количество компаний могут себе такую инвестицию позволить.
Рынок не насыщен и активно развивается, но отрыв крупных компаний начинает давить множественные мелкие начинания в зародыше. Условная сборка мотоциклов в гараже начинает проигрывать появившимся заводам.
Ну а крупные компании начинают оформлять свои наработки по нейросеткам в коммерческие продукты и выводить их в массовое коммерческое использование. Лицензии на прямое взаимодействие с GPT продаются больше в тестовом режиме и для отладки сетки, а вот Microsoft Copilot - уже полноценный сервис который MS продаёт вместе со своим онлайн офисом. Генерация документов и коммерческих предложений, формирование отчётов и презентаций на основе внутренней(!) документации компании, пересказ прошедших совещаний и тому подобное, что уже работает на коммерческой основе и начинает отбивать деньги затраченные на свою разработку. Более того - уже, сейчас, лишает работы многих офисных работников.
Как вывод хотел бы отметить несколько пунктов:
1) Нейросетки на первые сотни миллиардов параметров (GPT-3.5, PaLM, PaLM-2) научились хорошо и сравнительно стабильно тренировать, результаты стабильно растут по всем направлениям, но такие сетки имеют вполне видимый предел. Сеть на триллионы параметров (GPT-4) тренировать сложнее и такие сети сильно дальше от состояния завершенного продукта на данный момент, но уже показывают результаты превосходящие сети предыдущего поколения, хоть и менее стабильные, но растущие, как показано выше. Пределы возможностей сетей с триллионами параметров пока не видны, плюс к тому пробуют менять другую характеристику сети - плотность связанности, эффект которой я не возьмусь оценить численно, но больше - лучше, хоть и сложнее тренировать. Никакой стагнации в этом отношении нет, но повышение ценника с каждым шагом наблюдается явно.
2) Как видно из приведённого выше - на данный момент микрософт с GPT-4, помимо побочных продуктов, ставит себе фокус на генерацию нейросетью программного кода, даже в ущерб остальному функционалу, и достигли в этом направлении ощутимых успехов. Что в (отдалённой, или не столь уж) перспективе даёт выход на автоматическую генерацию кода как минимум для дописывания нейросетью модулей для себя (добыча/обработка обучающей выборки, исполнительные модули, интерфейсные, API, драйвера для физических устройств, итд), как максимум - для создания нейросетью кода для генерации следующего поколения нейросетей. Минимальный вариант позволит "бесплатно" создавать сервисы и повысит прибыль, максимальный, в теории, может привести к технологической сингулярности. Звучит как фантастика, но микрософт и гугл наперегонки копают в эту строну.
Дополнительно, из отчёта университета стенфорда:
AI starts to build better AI. Nvidia used an AI reinforcement learning agent to improve the design of the chips that power AI systems. Similarly, Google recently used one of its language models, PaLM, to suggest ways to improve the very same model. Self-improving AI learning will accelerate AI progress.
The world’s best new scientist … AI? AI models are starting to rapidly accelerate scientific progress and in 2022 were used to aid hydrogen fusion, improve the efficiency of matrix manipulation, and generate new antibodies.
3) СМИ и журналисты пишущие и рассуждающие на тему в большинстве своём полностью некомпетентны в теме и падки на горячие заголовки и эмоции. Поэтому регулярно появляются заголовки от "сильный ИИ уже завтра" до "всё пропало, ИИ тупеет прямо сейчас". Большинство таких заголовков не имеют никакого отношения к реальности, и даже если ссылаются на какие-то научные статьи - крайне редко их реально читали, и ещё реже - поняли о чём была речь. Имеет смысл читать только исходники, и прямое цитирование, а не журналистское мнение и пересказы. Впрочем, это справедливо для многих областей, да и для всей современной журналистики в целом.
Комментарии
Да ладно! Имеем:
1.Околополовина нового кода гитхаба генерится ИИ.
2.Учиться нормально можно на чьих-то правильных текстах/знаниях/... а не на своих содержащих ошибки (был-бы 1 ИИ генератор - он тупо мог бы свою генерацию игнорить, но ведь их уже несколько + результат ИИ-генерации обработанный слегка тоже в гитхаб падает).
Как говорили древние греки: "умному достаточно".
Вопрос только и исключительно в ценнике формирования нужной обучающей выборки. От скриптов или отдельных фильтрующих нейросетей вплоть до перебора и разметки руками каждого репозитория. Ну и отдельный вопрос насколько могут разнородные сети учиться на выходе друг друга.
Ну и - с какого потолка вы считаете что в гитхаб в релиз-ветки массово попадает сгенерированный код содержащий ошибки - непонятно. Тогда как дообучать сеть на сгенерированном коде в котором ошибки исправлены - один из лучших вариантов.
GPT - текстовый ИИ - абсолютно не владеет (не ощущает) смысла слов- он лишь копирует паттерны их расстановки в предложении (по частоте употребления копируя порядок слов в предложении), расстановку предложений в абзацах и тд по нарастающему объёму.
ИИ текстовый по сути не может ни тупеть, ни умнеть - он просто машинка комбинаторная. Если ему будут попадаться из 100 текстов на английском 90 текстов что "американцы" выиграли вторую мировую - он так и напишет, проигнорирую "малые веса" прочей информации. А правду и тем более истину он точно не способен выдать..
Сможете сформулировать чем отличается человеческий мозг от "просто машинки комбинаторной"?) Так-то значительная часть американцев считают что именно американцы выиграли вторую мировую)
Я могу.
Человеческий мозг - это контроллер связи физического носителя - тела с частью Души - Личностью так сказать.
Причём не обязательно головной мозг, даже спинной и костный - тоже являются частью этого контроллера!
И некоторая часть наших симбиотов - (пардон, кишечных бактерий) тоже принимает участие в работе этого контроллера - не всегда (во сне), только опосредованно, с задержкой - но принимает!
Ну так! И мы тоже - ну не ангелы. Заставили же нас в школе учить, что было, понимашь, татаро-монгольское иго...
И этого гнусного поляка, написавшего слово "Иго" и того немца Миллера с Шле... Короче, как тварей последних и исказителей истории - и пидоров иезуитов, за ними стоящих - надо помнить. И презирать. Как Гитлера. Как бандерлогов. Как убогих, убивших миллионы людей во имя Лжи, и сатаны и шайтанов.
Человеческий мозг, его часть отвечающая за интеллект - это всего-то корка неокортекса толщиной 1,5 см..или 100 грамм "интеллекта", остальная часть 500грамм (условно 1/5 часть) это эволюционный базис безусловных рефлексов на которые и наслаивается "интеллект" слоя неокортекса.
формально с точки зрения базовых решений мозг по устройству похож, как "чёрная коробка", на виртуальные нейронные сети, да вот только до 80% смены комбинаций смены связей внутри (аксону и дендриты) продиктованы гормональными выбросами в него в том числе. Интеллект без психики - это просто инциклопедия))
"..дайте любую, молодую, красивую-
души не истрачу!
- изнасилую!!..". Маяковский.
этот отрывок - это текст полностью "сгенерированный" как раз из гормонального, из ощущений.
в тексте сексуальное влечение(дайте любую), понимание что молодость - это фертильность(молодую, красивую), ощущение совести и греха (души не истрачу), и вишенка - отсутствие все это назвать честно "изнасилованием" которое звучит не в контексте УК РФ, а именно как эмоциональный сексуальный порыв заглушающий страх наказания))
ни одной строчки из этого ИИ не способен ни понять, ни ощутить, ни сгенерировать!! Вот вам и отличие...
Способен и понять и сгенерировать) На достаточно большом объёме данных "подражанием" порывы психики вполне себе имитируются. Можете побаловаться с https://beta.character.ai/ не смотря на примитивность обучения - выдаёт очень любопытные результаты, вполне имитируя эмоции и эмоциональные порывы.
Объём данных и имитация...
нет данных - нет ничего нового из имитаций..
а надо признать, что имеющийся "объём данных" далеко не весь спектр того что человечество успело выразить. То если что-то не высказано (не написано) человеком о его сущности, то эта категория будет вообще отсутствовать. Вот будет удивлением для ИИ когда он поймёт каково оно получить палкой по спине и ощутить боль которую не выразить словами - а без боли человек - не человек! и слова "война, утрата близких, горе, печаль" что занимает половину человеческой жизни - это БОЛЬ пережитая однажды физически, и для ии навсегда останется "терминами" из словаря Ожегова:
1. "БОЛЬ, и, ж.
-ощущение страдания. Физическая боль, Душевная бОль"
2. "Страдание
— совокупность крайне неприятных, тягостных или мучительных ощущений живого существа, при котором оно испытывает физический и эмоциональный дискомфорт, боль, стресс, муки."
3. "ОЩУЩЕНИЕ, -я, ср. 1. Непосредственное чувственное восприятие свойств объективной реальности, возникающее в результате их воздействия на органы чувств и нервные центры. Осязательные, зрительные, слуховые, обонятельные ощущения."
дальше текстовый ИИ начнёт играть в рекурсию и уходить в дебри описательного.. словами боль не выразить... ее можно только увидеть, услышать.. распознать гримасы боли- да, тоже возможно обучить, подвязать к этому и звуковой ряд.
но даже "понимая" это все ИИ будет абсолютно безучастен и равнодушен к самым страшным эпизодам жизни человечества , сформировавшим его ткань - конфликты, войны, разногласия - все это 50% смыслов между строк во всей культуре человечества, которые напрямую не описаны..
"Вот в таких строках "код" человечества, код нации абсолютно не доступен к пониманию ИИ - он не сформирует категорию "страх":
"Амбар. А в нём не хлеб – живые люди.
Они молчат, предчувствуя беду.
Снаружи, за дубовой дверью «судьи» -
Внутри сельчане приговора ждут.
Старик прикрыл полой шубейки внука,
Погладил по вихрастой голове...
А сердце сжала боль: такая мука -
Лишиться двух кормильцев-сыновей"
ИИ же выдаст не страх, а выверенное : если эти люди в амбаре являются колпаборантами, то по закону войны законное фашистское правительство имело право их уничтожить" и никакой тебе рефлексии...
Побалуйтесь с https://beta.character.ai/, если скормить какому-нибудь проработанному анимешному персонажу похожий стих он и ужаснётся и посочувствует и сможет описать что именно и почему его ужаснуло, со всеми полагающимися эмоциями. Вы просто не испытывали новые сети и не проверяли на что они способны.
Да, в том то и дело "скормить"..
без "скормить" он не одупляет ничего))
а "скормив" ему стих про "кровавый амбар", пронесёт ли он через всю историю своего существования это "знание"? Через 80 лет после событий в "амбаре" сможет ли он понять почему именно сегодня идёт СВО и как эти события связаны?))) или это ему необходимо "скормить" тоже? Когда скормить? Промеждупрочим, у краткой запихнуть это "знание" между имитацией текстового "сострадания" погибшему котёнку и баловством в запросе про "курицу и яйцо"?)))
Хотя такое знание фактов из истории и сопереживание им и является основным фактором формирующим личности, характера.. а так получается ИИ посочувствует и невинным фашистам, и русским погибшим тогда, и промокшему котику - всех жалко, ага.. толку то от этой примитивной рефлексии? Так, поиграться?
если ИИ не способен на это, казалось простое осознание-ощущение, то как ему доверить вопросы мирового масштаба, проектирование социальной среды, тенденций, технологий даже!? ИИ это утилитарный, узкоспециализированный инструмент, не способный в том виде в котором он развивается занять роль объединяющего и связывающего элемента, не пригодный для моделирования чего-то на самом деле масштабного в рамках общечеловеческого.
Вот же я про что ))
Не-не-не, не надо пускать текущие нейросетки к управлению обществом)
А в остальном - так ведь и человек без правильного воспитания и "напоминаний" - не запомнит то о чём вы говорили. Та же Украина в пример.
НЯП, человеческое "сознание", помимо машины комбинаторной, суть сочетание инстинкта построения иерархических отношений в стаде, и т.н. "рационализации" — создания мысленной псевдорациональной модели окружающего мира и своего места в нём. Т.е., короче, человек создаёт в голове "виртуальную реальность" как способ выживания в большом стаде суперхищников. Особо отчаявшиеся особи способны создать модели, сильно далёкие от общепринятых. Так и происходит наш прогресс.
Всё так) Только вот GPT уже проходит тесты и отвечает на вопросы требующие создания внутренней модели.
А почему сразу человеческий мозг? Вообще-то ChatGPT это калькулятор, который и от мозга червяка точно так же отличается. )
Пример с обучением неправильными данными тут некорректен, точнее сравнение с человеком некорректно. Берете слова одинаковые, но суть у них разная "обучение" "отвечает" "ошибается" и тд. В случае чата, ничего этого не происходит на самом деле. А что происходит, это отдельная тема, но вот например официальные представители Мета, Гугла и сам Илон М уже высказывались, что ИИ на языковых моделях не построить, хотя машинка тоже полезная, но тупик уже нарисовался. Вы тоже заметили про рост цен, на самом деле все серьезнее, и по заявлению этих серьезных дядек уже началось развитие ИИ на других алгоритмах (в основе не языковая модель и подсчет вероятностей). Все хотят построить сильный или общий - AGI кажись.
Не нарисовалось никакого тупика) Но денег жалко всем и вместо прошибания стены влоб - мощностями и деньгами - все надеются найти какой-то обходной путь, особенно те кто уже отстали от GPT прижившегося под крылом Микрософта и понимают что при практически любых вложениях не успеют догнать конкурента не срезав где-то угол.
Ну объясните Илону Маску, что он дурак и не надо никаких 30-50 тысяч топовых видеокарт h100 для вхождения в этот бизнес, хатит и одной или что конкретно вы предлагаете?
В этих корпорациях, между прочим, умнейшие люди планеты сконцентрированы и когда одна из верхних голов что-то говорит, она корпоративное мнение озвучивает.
Тупик там по причине осутствия в исходной базе данных требуемой информации, как ни странно (опять отдельная тема). Это пытались обойти путем привлечения большого количества людей для так называемого обучения, и это принесло успех, но так же пришло и понимание тупика и вероятно выхода из него.
Я вообще-то и в статье и в комментах постоянно говорю что в этой отрасли время "гаражных" производств закончилось на GPT-2. А чтобы конкурировать с "промышленным" GPT-4 - вполне могут понадобиться те самые 30-50 тысяч топовых видеокарт. И то без гарантии что конкурент тебя не обгонит.
Вы с таким же успехом можете заявить что сталелитейная отрасль зашла в тупик, тк сейчас никак не хватает домашнего тигля для вхождения в бизнес.
Отсутствие данных по специфическим темам компенсируется тем что сетка обученная на бигдате уже может вполне неплохо понимать текст и делать выводы на его основе. Более того есть варианты создания надстроек над сетками на основе таких "прочитанных" данных.
Вхождение в бизнес, который гарантированно потребует в скором времени глобальной перестройки. Что произойдет если такой бизнес еще не успеет отбить инвестиции, когда все уже перешли на новую модель, которая оказалась лучше и уже захватила рынок?
А вот от сталелитейки ничего принципиально нового никто и не ожидает. Там все инновации на многие годы вперед предварительно распланированы и всем известны.
Не по специфическим темам, а принципиально по всем. Это математическая и физическая проблема. Так устроен язык и потому, база на основе текста не может содержать всей необходимой информации для понимания информации. )
Вы произнесли волшебное слово "ценник". Чтобы жпт стал удобным инструментом, нужно вложить труд группы специалистов, после чего жпт начнет транслировать их опыт на ограниченном (пусть и большом) материале, избавляя пользователей от специфических рутинных операций. Чтобы система продолжала адекватно обучаться, группу специалистов придется содержать постоянно. Никакого халявного интеллектуального негра.
Нет, не так. У специалистов обучающих гпт может не быть абсолютно никакого опыта в областях в которых сетка успешно отвечает. Именно халявный интеллектуальный негр, создание которого требует знания в первую очередь в области обучения нейросетей а не в целевых. А учатся сети на уже зафиксированном опыте в виде книг, статей и прочего.
Извините, но вы - наивное дитя копирайта. Кто будет писать книги, статьи и прочее, и за чьи деньги? То, что тренеры жпт имеют доступ к достоверному опыту, очень быстро будет исправлено самим жпт. Собственно, процесс и так уже пошел, робот его просто бесконечно ускорит.
Тут отчасти согласен, вопрос разбирался в заглавной статье - нужно наличие очищенной выборки, сейчас её сделать сравнительно просто, дальше - сложнее.
Но процесс глобальней. Например сейчас гпт может частично заменить младших программистов. Но без младших - откуда браться миддлам и старшим?)
Процесс еще глобальней. Учитывая, как много черпает из сети подрастающее поколение, потенциальные младшие специалисты скоро будут неотличимы по поведению от жпт.
Сетям учиться друг у друга это как студентам средненьким учиться матану не по книжкам/лекциям/практике а друг у друга.
Так ведь срабатывает иногда даже у студентов, если они разные лекции прогуливали)
Если помнят студенты заведомо не точно - срабатывает не часто и любой ответ без гарантии/степени уверенности что знаешь правильно.
Может, камрад помнит байку года Московской Олимпиады - типа на перфолентах ещё написали на бейсике прогу для PDP-11/40 самообучающуюся.
С рандомным генератором тем ещё (ну RND()) - а бейсик перфоленточный - интерпретатор был! И вот, на нужных данных она дала верный ответ! В Америке типа дело было - все пиво уронили!! Потом - запускали прогу так и сяк - но больше ничего не вышло путнего.
Главное - понять ваще, что же они понимают под термином "интеллект". Ум? Хитрость? Разумный диалог и псевдоразумное проявление эмоций в рамках заданных программой?
Нет в нашем языке понятия, эквивалентного термину "интеллект". А пока мы не понимаем, об чём речь - ну нах нам ихний Чат ЖПТ??
Собственно да, все ранее придуманные тесты на интеллект GPT успешно прошел и тьюрингов всяких и прочее) И на данный момент его начинают использовать именно в прикладных назначениях и значим именно функционал. А о том это интеллект-не интеллект и как их различить - пусть философы думают и новые тесты изобретают)
Байку помню. Определение наличия интеллекта? Ну как минимум - тест Тьюринга, а как максимум... Ну путь проявление того что Кант называл божественной сущностью человека - способность созидания нового, ранее не существовавшего.
"Пределы возможностей сетей с триллионами параметров пока не видны, плюс к тому пробуют менять другую характеристику сети - плотность связанности, эффект которой я не возьмусь оценить численно, но больше - лучше, хоть и сложнее тренировать."
Таки да, впёрлись в то, что приемлемые результаты получаются, когда за счёт максимального дробления выборок снижается влияние частотности в пользу связности - но верификация, что это не бред и не ложные корреляции, невозможна без экспертного знания.
И тут возникает вопрос - а чо, сразу нельзя было посадить эксперта-предметника с линейным классификатором, который будет выдавать на домашнем ноутбуке корректную модель предметной области за пару десятков тыш баксов?
Так-то по факту коммерциализируют то, что давно вылизано экспертами - скрещивают языковые процессоры с компиляторами.
Вопрос опять таки в деньгах) Изначально большая языковая модель "внезапно" начала выдавать оч неплохие результаты вообще без дополнительных затрат. Просто большая модель, просто накормленная большой выборкой. Увеличили на порядок - ещё лучше стало, увеличили ещё на порядок - и ещё лучше.
И вот когда это всё переросло "прикольные эксперименты" и начало выходить на коммерческий уровень - появилась необходимость отслеживать не-ухудшение модели по ВСЕМ областям. И, соответственно, начали в срочном порядке собирать "метрики" для проверки сетей в новых областях. Как раз в этих метриках и пригодятся эксперты-предметники, которые будут писать наборы вопросов для верификации новых сетей. *Правда и тут корпораты пытаются сэкономить - "а напишите вы сами вопросы для своей предметной области, если вам надо".
*Но у вас ооочень ошибочное восприятие стоимости создания хоть сколько-то пригодной к применению модели предметной области используя эксперта-предметника, порядка на 2-3)
А это зависит от страны. Вы таки думаете, что филиппинские рентгенологи делают разметку для IBM по расценкам американских рентгенологов?
Т.е. в конечном итоге вернулись к тому, с чего начали - семантику выверяют кожно-мясные.
Что позволят тем, кто это сообразил, на повороте задёшево обогнать тех кто вложился по крупному.
Тоже верно) Но всё равно до состояния готового к реальному практическому применению проекта а не к демке на уровне студенческого курсового - долго и дорого, даже с филиппинцами)
И по стоимости сопоставимо со всей тренировкой GPT-3. Вот и получается что для gpt-3 это было избыточно, а вот для gpt-4 - уже может пригодиться.
Позвольте с вами не согласится. Мелкие практически пригодные куски можно нарезать за пару месяцев.
Хотя да, всё обо всём потом из них собирать это процесс непрерывный, длительностью существования цивилизации.
Было бы просто и дёшево - было бы реализовано на каждом шагу) А так - занимаются институты с переменным успехом на базе халявного труда студентов, или всякие IBM, которые могут себе позволить такие вложения.
IBM свой медицинский общедиагностический ИИ на большой языковой модели несколько лет назад уже списал в многомиллиардные убытки.
А участковые тётки в пооубессознательном состоянии после 50+ пациентов за смену без вычисления вероятностей свои диагнозы ставят достаточно корректно.
Так что чат-гопота и интеллект - это зверушки разной породы.
IBM Watson - это как раз (провальная) попытка учить меньшую по сравнению с GPT систему на отборных экспертных данных. Тогда как реально большие модели накормленные разносторонними данными изначально формируют лучшее "понимание" языка, на что в дальнейшем уже можно положить выборку с данными экспертов. IBM продала свой медицинский ватсон, но выборки данных у них вполне остались.
Ну а участковые тётки - тоже бывают оочень разными, в том числе и с существенным количеством ошибок.
Я смотрел патент IBM. Они дробили всю имеющуюся у них выборку. Если в их данные добавить японскую чайную церемонию, то медицинская диагностика не улучшится.
Проблема в частотном подходе. Во-первых, чтобы попала редкая патология, надо собирать долгие годы.
После чего вылезает во-вторых, что вчера в комментах проиллюстрировали, скормив чат-гопоте "я спросил у ясеня", и получив в ответ "группу Кино". Почему? Патамушта часто. Если скормить температуру и кашель, получите ОРВИ и острый бронхит, а не муковисцедоз, даже при его наличии в выборке - патамушта часто. Что требует присмотра кожно-мясных.
В третьих, какая частотность пневмонии у астматика со стенокардией и артериальной гипертензией на фоне хронического гломерулонефрита вследствие ревматизма? Спросите у Германа Грефа, вбухавшего миллиард баксов в Сбер ИИ, который выдаёт три наиболее вероятных диагнозы. Т.е. частотный подход вообще не работает с сочетанной патологией. В отличие от участковых тёток.
Т.е. чтобы реально работать с медициной на частотности, нужны многие годы, присмотр экспертов, и в итоге пролетает сочетанная патология.
И тут мы возвращаемся к тому, с чего начали - а кто мешает сразу посадить экспертов с линейным классификатором, для которого частотности фиолетовы? Спецы будут выдавать в темпе 1 работающий фрагмент за 1 месяц плюс пару месяцев на перекрёстную верификацию.
Неужто Герман Греф, который уже освоил ярд зеленью?
Не так это работает. Если правильно настроить оценочную функцию - можно выставить большую "награду" за правильное обнаружение редких заболеваний, бОльшую чем за обычные, и сетка отличнейшим образом натренируется на их поиск (при условии достаточной обучающей выборки, без данных ничего не заработает, да). С сочетанными - сложно, но вполне реально, опять же тонкая настройка оценочной функции. Это не имеет принципиальных различий от обнаружения нескольких объектов на изображении, что уже успешно реализовано. Единственное отличие - доступность выборки для обучения. Собрать огромную базу фотографий из интернета для тренировки может каждый, а вот собрать датасет по заболеваниям, симптомам их сопровождающим с приложенными обследованиями... И чтобы этот сет был достаточно объёмным и достаточно достоверным... Сложно и дорого)
Что до сеток, выдающих наиболее вероятные (вообще) диагнозы - это значит только то что что им нужно было показать результат за наиболее корректное время и они просто потеряли детали из-за слишком быстрого обучения. Лучший датасет, лучше настроенная оценочная функция, дольше время обучения - проблему решит, если они готовы будут в это вложиться (что может потребовать на порядок больше уже потраченного).
То есть простую сетку которая будет выдавать в районе 70-80% точности я могу натренировать на коленке и весьма быстро, это будет красиво для демки, но это не будет практически применимо. А вот до реальной применимости нужно будет потратить на порядок-два больше.
Проблема с линейными классификаторами - даже мега-квалифицированные эксперты не всегда могут формализовать почему именно они принимают такое решение в каждой конкретной ситуации. Очень явно проявляется при классификации картинок. Попытка на бытовом уровне формализовать чем фотография кошки отличается от фотографии собаки - попробуйте) А нейросети - справляются элементарно.
Вы упорно обсуждаете в терминах байесовщины.
При том, что злая птица Обломинго прилетела ещё в былинные времена разработки MYCINа. Оказалось, что в медицине вероятности известны крайне редко, вследствие чего изобрели "нечёткую логику", оно же хайли лайкли.
Так что да, теоретически можно собирать десятилетиями дата-сеты на редкую и сочетанную патологию, и потом их экспертами выверять, что "я спросил у ясеня" было в кино, а не у Кино.
А можно за месяц получить работающий фрагмент от того же эксперта, дав ему линейный классификатор.
При чём тут байес? Правильно настроенной нейросетке не нужны общие вероятности, она обучается именно на предоставленном датасете и как раз нейросети работают на той самой нечёткой логике с кучей не-целых коэффициентов на куче параметров на куче слоёв.
Вы всю жизнь спокойно различали кошек и собак, вы отличите фотографию кошки от собаки с 99.99% точности. Вы сможете за месяц или даже за пол года написать классификатор отличающий кошку от собаки по фотографии? Если бы любые знания можно было так легко формализовать - экспертные системы взлетели бы много выше)
Нейросетки разные.
IBM медицина работала на частотности. Чат-гопота записала ясень в Кино тоже на частотности.
Если распознавание на линейном классификаторе, частотности не нужны. Хотя никто не мешает их скармливать на входе в линейный классификатор. С последствиями, о которых я написал выше - если без экспертного пригляда.
Но если эксперту уже известно, то зачем вне исследований нужны большие данные, длинные сроки на сбор, и аппаратный дорогостой?
У меня ощущение что вы применяете фразу "линейный классификатор" как некое заклинание. В глубоких нейросетях этих классификаторов может быть на каждом пятке слоёв и по несколько сотен связывающих тысячи параметров, выходы из которых будут переданы в классификаторы выше. Более того - обычные классификаторы будут очень сильно буксовать с сочетанными симптомами и многоответными задачами, попытки это исправить приведут к обычной современной нейросети.
Если речь о том что эксперт всегда может обучить линейный классификатор - нет, не может, может не хватать как глубины классификатора так и понимания эксперта, так и задача может не иметь бинарного решения, после чего эксперт оставленный наедине с классификатором засыплется.
Можно долго и упорно скармливать суперкомпьютеру миллионы фоток кошечек и собачек.
А можно спросить эксперта про шерстяного хищника весом до 3 кг - кошечка или собачка? Ответ - молодой человек, вы таки скажите мне за вашего хищника - когти втягиваются, или нет?
Стоимость и сроки разработки несколько отличаются.
Я специально уточнил - по фотографии)
Иметь полную биопсию всего пациента могут себе позволить только анатомы в морге)
По фотографиям диагнозы ставят экстрасенсы. А участковые тётки работают с клиническими признаками. Не доводя до результатов вскрытия.
Так что есть предметные области, где можно углы срезать, если не заниматься копипастой транснациков.
Дополнительная информация для различения кошки или собаки кроме содержащейся на фотографии, такая как "втягиваются ли когти" - не всегда доступна.
Дополнительная информация для постановки диагноза кроме наличествующей в истории болезни, такая как "результаты биопсии мозга" - не всегда доступна.
Иногда есть какой-то легкодоступный параметр который радикально облегчает классификацию и его проще включить в систему (срезать угол) чем обходиться без него. Но в большинстве случаев такой "серебряной пули" нет.
При том в большой части случаев ответ можно дать и без дополнительной информации. А вот формализовать как именно можно дать такой ответ только на основе имеющихся данных - сложно даже в примитивном примере различения кошек и собак.
Это потому что вы кошек готовить не умеете.
Множественные полости в легких на фоне сахарного диабета это надо заряжать шприц против золотистого стафилококка, то же самое но на фоне полимерных имплантов это против стафилококка, но полирезистертного, а полость в верхней правой доле на фоне переохлаждения у алкоголика/наркомана это надо против клебсиеллы воевать.
А теперь пособирайте это лет десять через большие данные, если участковые тётки могут и одного раза за всю свою звёздную карьеру деструкцию в лёгких не встречать.
Хотя вот оно, известно и доступно.
Правильно. Для того, чтобы не быть ложным, надо чтобы ИИ сначала был умным, а потом стал тупеть.
Чат жопт это изначально продвинутый поисковик. Изменилось только то, что кончились деньги на рекламу и вал заказных хвалебных статей уменьшился. И начал быть слышен голос обычных людей, которые с ним работали и никаких чудес ИИ не увидели.
Страницы