





Заметка подготовлена для более удобного обсуждения узкоспециальных тонкостей в ответ на вот это сообщение Алекса:
https://aftershock.news/?q=comment/12649466#comment-12649466
Исходим из предположения, что скрипт выборки текстов комментариев из базы уже есть и в базе для его работы имеется поле о статусе пользователя типа "забанен".
Что требуется делать дальше.
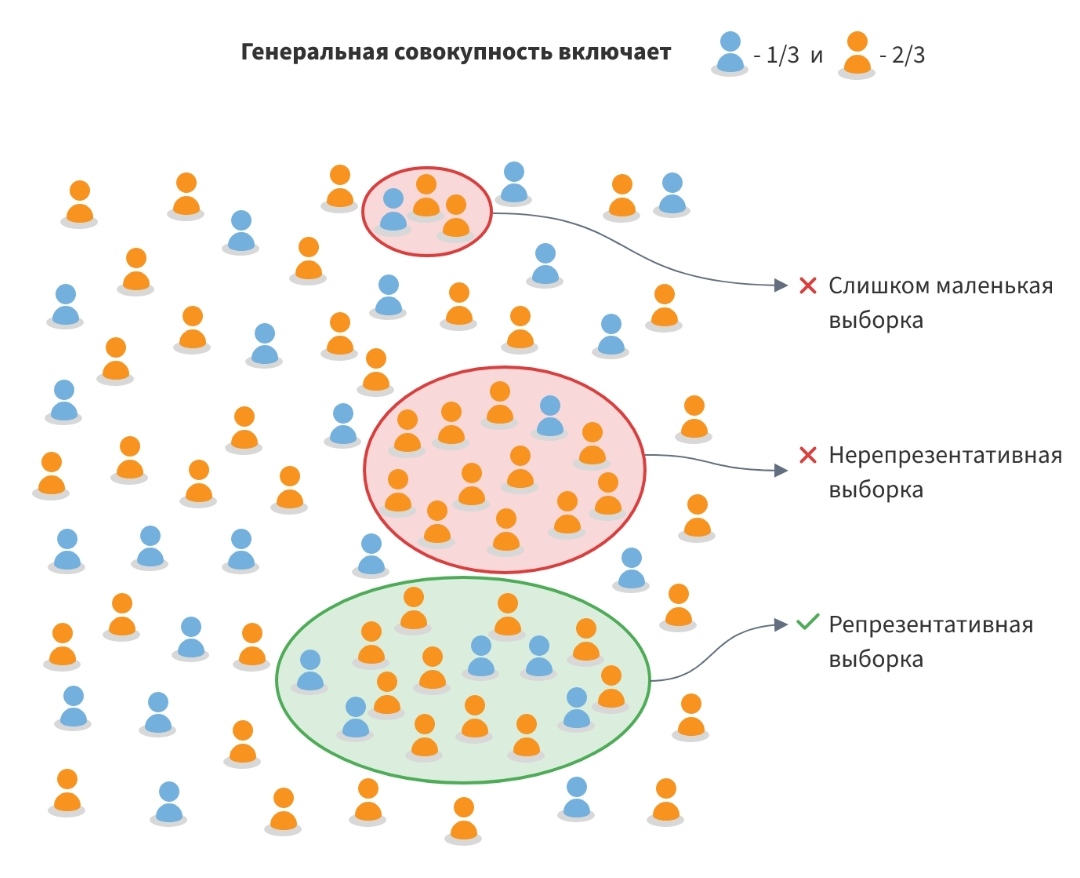
1. Самым базовым/фундаментальным требованием конкретно этого алгоритма математической статистики является необходимость сравнивать что-то одно с чем-то другим, вместо сравнения этого чего-то одного с чем-то неизвестным (неописанным в терминах этой маьематики). Совсем простыми словами - для любого критерия нужен хоть какой-нибудь противовес, иначе непонятно/невозможно вычислить численное значение меры похожести. Чуть сложнее - алгоритм хорошо работает в условиях закрытого множества решений, но плохо, если множество решений открытое (неограниченное, неизвестное).
Таким образом на самом первом этапе целесообразно предложить два следующих варианта, отличающихся вычислительной нагрузкой:
А) Вычисляется статистика 5-граммного распределения всех комментариев забаненных пользователей и такая же статистика для +-близкого количества (в штуках или символах) случайных комментариев незаблокированных пользователей. Не знаю порядки величин и язык скрипта, но на современных процессорах в Си++ и Питоне у меня ноутбук за единицы минут справляется с гигабайтными объемами кириллического текста. Важная оговорка - процесс прекрасно распараллеливается на любое доступное число ядер/потоков, так как получающиеся в результате первичного расчета матрицы можно поячеечно складывать. Недостаток варианта - слишком размытое, статистически малоэффективное/размытое представление обоих классов сообщений, так как в одну кучу будет свалено вообще всё - ковид, истерики, хохлы, набросы, возмущения, обиды, выяснения, разборки.
Б) На вкус любого человека выбираются несколько десятков наиболее характерных (об этом далее) сообщений забаненых пользователей, а в качестве противовеса им выбирается несколько случайных сообщений самого Алекса. Этот вариант предпочтительнее на первом этапе так как работать будет однозначно быстро, позволит оценивать производительность без расходования лишних ресурсов и в достаточной степени отладить саму математику в вашей реализации.
В) В базе пользовательских комментариев добавить следующие поля (это все-равно придется делать рано или поздно):
- причина блокировки, типа целочисленное, и вручную для нескольких десятков комментариев по каждой из причин проставить простые значения: 0 - нормальный комментарий, 10 - мат, 20 - оскорбления, 30 - повышенная эмоциональность(снова - об этом далее), 40 - ковид, 50 - хохлы. Или что-то похожее. Число в этом поле будет соответствовать номеру обучающей выборки, таким образом сразу формируются взаимные противовесы для классов. Десятичные значения выбраны изначально про запас, так как по мере освоения инструмента вы однозначно захотите доуточнить типы в классах и уже появится понимание как именно это делать.
- поля значений, удобнее всего поле типа список(вектор, строка/столбец, текст с разделителями, как в вашем языке удобнее), в него будет записано столько же величин в штуках, сколько разных значений будет установлено на предыдущем шаге. Чтобы не плодить поля в самой базе - проще их как-нибудь объединить в понятном для движка СУБД виде, чтобы потом отрабатывать запросы. Эти величины и будут показывать степень статистического приближения этого комментария к выбранным ранее сообщениям. Если одно из значений больше суммы всех остальных - то это однозначное попадание, т.е. значения сортируем по величине и первое сравниваем с суммой всех остальных. Ну а далее на ваш выбор, два самых больших отличаются не больше 30% и тоже больше суммы всех остальных - тоже хороший признак, здесь неограниченное поле для отладки численных параметров.
2. Каковы признаки "истеричности", эффективно обрабатываемые и выявляемые этим классом статистических алгоритмов?
На первом этапе очень просто - это превосходные степени прилагательных и наречий. Лучший, самый, никогда, всегда. Любым поисковиком находятся необходимые примеры из школьных учебников русского языка и добавляются в отдельное сообщение с параметром 30 (из моего примера причин блокировки).
Всё то же самое и с остальными причинами, на асом первом этапе нас интересуют наиболее характерные слова или словоформы, которые неспециалист может выделить как наиболее характерные для этой причины блокировки.
Самому алгоритму на первом этапе более чем достаточно отдельных слов, целиком комментарии можно даже не обрабатывать.
Думаю тут должно быть уже понятно, но готов дополнительно поразжёвывать если требуется.
3. Можно запускать обработку первого этапа. У сообщений в базе появились какие-то значения, отлично.
Вторым шагом отладки обучающих выборок в нашем случае будет анализ результатов.
Наиболее простая оценка - это выборка из базы по несколько десятков сообщений с самыми большими и самыми малыми значениями по каждому из параметров причин блокировки. Вот уже что-то будет видно, в самых первых рядах окажутся сами наши обучающие сообщения (они максимально похожи сами на себя и минимально похожи на любые другие).
Но и это уже очень важно - к ним добавятся ещё какие-то новые сообщения, ранее отсутствовавшие в обучающей выборке этого типа причины блокировки.
Сравнивайте, похоже ли и соответствует ли это вашему восприятию достаточности такого комментария для блокировки.
Если считаете, что достаточно - то ставьте этим новым сообщениям такую же причину в соответствующее поле. Если нет - то любую другую.
Эти ваши действия принципиально важны, формально они называются дообучением, но на самом деле вы подстраиваете статистики и ваши весы начнут склоняться в нужную сторону либо больше, либо меньше. Т.е. сам алгоритм не изменяется, а вот исходные данные для него будут другими и это начнет влиять на результаты обработки.
4. По мере удовлетворённости результатами повторять корректировку обучающих выборок, подчищать базу когда некоторые сообщения портчт статистику и приводят к смешению классов причин блокировки, а-ля мущинку порвало про беспилотный ковид в окопах.
;)
Всех обнял, оппонирование приветствуется!
Комментарии
Тэги возьмите в качестве классификатора тем.
Да, это будет вторым шагом применения алгоритма, но уже не к комментариям, а к самим статьям.
Рубрикация.
"мягкое" введение в теорию обработки текстов на базе МЛ для пользователей АШ? :)
Да, перед интегральным исчислением надо освоить абак, столбик, узелки и прочую арифметику.
В теории интересно, практика и эффективность под вопросом.
Где-то есть уже внедренный и работающий алгоритм, который можно было бы оценить?
Ну Алекс, я же не могу показать вам коммерческие решения с тамошними обучающими базами.
В админке ныне запрещенной лицо-книги пользовательские комментарии для цензуры обрабатываются весьма похожим образом.
Atorn'а Вам в помощь, в разбивке на категории. Он вроде заинтересовался.))
Так этого нет в БД
Ну возьмите в качестве разных противовесов не все имеющиеся комменты, а комментарии Вас, меня и ВладиславаЛ.
Так это ж ручная работа:
Даёшь им десяток забаненых хохло-ботов(тех.задание) и они делают матрицу.
Или иначе: они дают тебе готовую "машинку" и ты загружаешь комменты для матрицы по интересующему тебя признаку.
Как-то так я их понял.))
Советы болтунов не требуются. Нужна работа.
Если берёшься за это, то мы спасибо скажем, со всем нашим пролетарским уважением! вот такой смайлик выпал на твоей не совсем корректно работающей матрице на смартфоне.
вот такой смайлик выпал на твоей не совсем корректно работающей матрице на смартфоне. за сим откланиваюсь.))
за сим откланиваюсь.))
Mail. Ru использует автоматические алгоритмы для банов игроков в своих играх за использование неправильного читерского софта.
Заметте, тут именно софт, а не эфемерные понятия типа уровня истеричности или превосходных степеней прилагательных. То есть всё должно быть намного надёжней. Но результат предсказуем. Из огромной массы знакомых за реально читерский софт забанены ы десятки раз меньше людей, чем забаненых по ошибке. Потому что программе что-то там показалось. То есть Баны идут не за действия игроков, а за ошибки в алгоритме программы
Получается широкий гребень, который на 1 виновного будет банить 10 невиновных. В итоге читеров конечно серьёзно проредили, хотя они постоянно придумывают что-то новое. Но ценой постоянных банов нормальных игроков, которых это мягко говоря бесит . Ну а если вешаются вечные Баны, то приходится муторно доказывать свою невиновность или платить деньги за разблокировку. Или уходить в другие проекты.
Еще раз повторю, мы обсуждаем не автоматические баны.
Обсуждается алгоритм автоматизации поиска вызывающего поведения по разным критериям.
1. Как я понял автора по ранним заметкам, статистику N-грамм предполагается вести на уровне именно букв.
Тогда маловат охватываемый контекст - одно слово или переходный участок между словами.
2. Если вести статистику N-грамм на уровне корней слов, то надо связываться с предварительным морфологическим анализом, который хорошо проработан, но утяжеляет обработку.
==============
3. основная проблема тут - закрытость словаря. Всё равно всё рано или поздно упрется в простом случае в наличие слов-признаков искомой "истеричности", а в сложном случае - будет еще учитываться и место такого слова в структуре предложения.
Все методы с закрытым словарем легко и просто обходятся, это хорошо известно всем писателям на форумах с мат-контролем. Первые версии мат-контроля были настолько слабы, что заменяли звездочками слово "херувим".
Но люди приспособились, язык наш синонимами богат + словоупотребления ad hoc.
Для борьбы с этой проблемй тут смотрится что-то вроде word2vec, подход на основе труднопереводимого импортного термина embedding.
Для первичной статистики по коротким текстам переходы оказываются важны, так как корни слов (тезаурус) ложатся в свои ячейки матрицы данных, а приставки/суффиксы/окончания - в другие и эти отличия оказываются важными.
Но, не вопрос, по желанию или статистически обнаруженной необходимости добавляются 3-, 7- или 9-граммы.
В принципе, запрет истеричности может ударить и по художественным текстам, а-ля Луис Альберто. С другой стороны, не стоит задача убрать всю истеричность, 80% уже было бы за щастье, ибо манипулятивные тексты в основном на эмоции и бьют.
Молодец. Вручите оружие информационной войны в руки запада на блюдечке с голубой каемочкой (все конечно рассматриваю с точки зрения презумпции виновности что делаете вы это не ради России), когда один дурак (равно ЦИПсОшник) столько вопросов задаст что сто мудрецов не разберут, а главное не захотят этого делать и тем более без эмоций.
Мат в армии и эмоции заменяют 1000 слов и логических рассуждений и объяснений, особенно когда это актуально в информационной войне, где все ресурсы ограничены, а вот ресурсы противника наоборот не ограничены. И война ведется на территории России. Если перевести её строго в область интеллектуальных войн то здесь АШ можно закрывать.
Запрет на эмоции это то же самое что отрицательный отбор на ЛОМов. Вы их тупо помножите на ноль. Вырвите зубы рунету. Это ваша настоящая цель?
Ну и многих покусали этими зубами рунета? Может быть партнёры хотя бы испугались протёртых диванов?
:)
Никто вам ничего не запрещает, не нагнетайте на ровном месте.
Найдут, измерят и занесут в личное дело на ресурсе, вот и всех делов.
В целом - да, задача ограничения эмоциональности не стоит и не ставилась.
Поставленная задача - это автоматизация выявления излишней эмоциональности.
А вооб-ще, уд-ивите-льно для м-еня, делат-ь ана-лиз н-а прос-тых 5--букв с-ловах...
Правильно разбил на 5 буквия?
Хех, нет, неправильно.
Скользящее окно должно быть не с шагом 5 символов, а с шагом 1 символ. Т.е. из текста выбираются по очереди все пересекающиеся фрагменты.
Можно показать. Пример.
можно
ожно
жно п
но по
о пок
пока
показ
оказа
Ааа, понял. Спасибо. :)
Да не за что!
Эта простейшая моделька из 199х-200х-ных годов при всей своей вычислительной легковесности и очевидной простоте даже сейчас позволяет получать мощнейшие метрики с высоким уровнем статистической достоверности.
Шутки шутками, но если учитывать знаки препинания и заглавные буквы, то количество используемых параметров легко достигает 1 млрд, что уже сопоставимо с моделью GPT-2 и при этом вполне работоспособно на однопроцессорных +-современных компьютерах.
Шинглы уже не в моде. Word2vec!
Не заставляйте бегать не научившегося хотя бы самостоятельно стоять.
https://aftershock.news/?q=comment/12652031#comment-12652031