По рекомендации одного хорошего и хорошо известного на АШ автора, публикую статьи с Хабра автора S0mbre (Искандер Шафиков). Статьи уважаемого S0mbre имеют сильный уклон на работу с данными при помощи языка программирования питон. Данные и их интерпретация интересные, но программирование для АШ это неформат, поэтому то, что касается кода и манипуляций данными при его помощи, буду приводить в спойлерах.
В питоне отступы значащие, а движок сайта не позволяет структурировать текст как того требует язык. Поэтому код, приводимый в тексте, может поломаться. Если интересует именно он, качайте исходники. У нас тут нет специальных блоков для кода, буду выделять его как цитаты.).
Данной статье пол-года, поэтому устареть она не успела, хотя страсти по BLM и приутихли.
Сама оригинальная статья выходила в трёх частях. Здесь собраны все три.
Часть 1.
Зная, насколько эта публикация может оказаться воспринятой как "политическая" и насколько разнятся мнения людей по определенным злободневным вопросам, сразу внесу следующие оговорки:
-
Автор публикации не является расистом, не считает, что представителей одних рас должны обладать какими-либо привилегиями или предпочтениями по сравнению с представителями других рас. Для меня все люди - братья!
-
Автор не стремится придать публикации политическую или социальную окраску, поддерживая ту или иную распространенную точку зрения на социально-политические темы, которые выходят за рамки этой публикации.
-
Цель публикации - статистический анализ данных из открытых источников и выявление взаимосвязей и закономерностей; широкие выводы предоставляется сделать читателям.
-
Все данные, использованные в статье, взяты из открытых источников, прямо указанных в самом тексте. Каждый из вас может их верифицировать. При этом автор не несет ответственность за валидность данных в самих источниках, принимая их "как есть" и не изменяя никакие исходные данные. Поэтому сомнения в валидности настоящего исследования должны относиться к исходным данным, на которые автор не может повлиять.
-
Я не считаю себя профессиональным Data Scientist и использую самые базовые инструменты анализа данных (при этом, наверное, не всегда наиболее оптимальным способом). Буду благодарен каждому за подсказки, как можно сделать то или иное более эффективно или углубить исследование!
Во времена Советского Союза нашим с вами, уважаемые читатели, папам и мамам, дедушкам и бабушкам неустанно и отовсюду напоминали о том, как "империалисты" притесняли и угнетали представителей иных рас, как уже после отмены крепостного права в Российской Империи американские капиталисты продолжали использовать рабский труд африканцев и их потомков, как и в нынешнем (на то время) двадцатом веке издевательства не прекращаются даже после формального упразднения рабства, выражаясь в самых возмутительных формах апартеида, унижений, расизма и ненависти... Классические романы вроде "Хижины дяди Тома" Гарриет Бичер-Стоу и "Убить пересмешника" Харпер Ли еще сильнее упрочняли негодование борцов за свободу по всему миру. Да, расизм со стороны белых процветал в США до 1960-х - 1970-х. Но и, конечно, эти притеснения были отличным подспорьем для социалистической пропаганды, не щадящей красок в живописании "зверств акул капитализма". С середины 1950-х в США началось сильное движение за борьбу с расовым неравенством, которое было в итоге поддержано властями и кардинально изменило ситуацию с социальными свободами к 1980-м. Обо всем этом можно прочитать хотя бы в Википедии. А что теперь?..

Иллюстрация к роману Г. Бичер-Стоу "Хижина дяди Тома". "Классическое" изображение рабского труда африканцев.
Почти все то же, что наши родичи читали со страниц "Правды" в 1960-х, сейчас мы слышим со всех американских СМИ. Расовая несправедливость! Насилие со стороны полиции и иных слуг закона! Как мы все видели, после гибели Джорджа Флойда в США начались массовые протесты, перешедшие местами в беспорядки и погромы под лозунгом Black Lives Matter. Итог официально озвучиваемого и поддерживаемого общественного мнения в США на сегодняшний день: полиция убивает чернокожих по причине массового расизма со стороны белых.
Цели исследования
Как и многим из вас (я уверен), мне часто хочется самостоятельно разобраться в каком-то вопросе, особенно если:
-
вопрос широко обсуждается и составляет предмет споров
-
освещение почти во всех СМИ носит явно окрашенный характер (т.е. налицо пропаганда той или иной позиции)
-
есть достаточное количество исходных данных, доступных для изучения
Интересно заметить, что эти три пункта связаны между собой: 1) злободневные вопросы почти всегда однобоко освещаются прессой, так как истинно свободной прессы почти нет (да и была ли когда-то?) 2) злободневные темы порождают сообщества активистов, которые начинают собирать и анализировать данные в поддержку своей точки зрения (или во имя справедливости); также данные начинают открывать / предоставлять публике официальные источники (чтобы их нельзя было обвинить в сокрытии оных). Об имеющихся данных поговорим чуть позже, а пока - цели исследования.
Я хотел для себя ответить на несколько вопросов:
- Какова статистика применения поражающего огня полицейскими против черных и белых в абсолютном выражении (т.е. количество случаев) и в удельном выражении (на количество представителей обеих рас)? Можно ли сказать, что полицейские убивают черных чаще, чем белых?
- Какова статистика совершения преступлений представителями обеих рас (в абсолютном и удельном выражениях)? Представители какой расы статистически чаще совершают преступления?
- Имеется ли взаимосвязь между статистикой совершения преступлений и статистикой гибели от рук полиции (в целом по США, а также отдельно для белых и черных)? Можно ли сказать, что полиция стреляет насмерть пропорционально количеству совершаемых преступлений?
- Каким образом найденные закономерности (по пунктам 1-3) распределены между отдельными штатами США?
На данный момент это все вопросы, однако, я не исключаю, что могут добавиться и другие в процессе исследования, которое пока выполнено лишь на самом поверхностном уровне.
Оговорки и допущения
Вы ведь прочитали дисклеймер в начале статьи? :) Кроме того, что там написано, вот еще несколько допущений и оговорок, принятых для исследования в основном в целях упрощения:
-
Исследование касается только США и не распространяется на другие страны.
-
Представителей чернокожей расы в США для краткости я могу называть "черными", а представителей белокожей расы - "белыми"; эти краткие наименования не отражают какого-то неуважения, а приняты именно для лаконичности.
-
Представители белокожей расы ("белые") включают латиноамериканцев (проживающих на территории США), но исключают представителей азиатских рас, американских индейцев, гавайцев, эскимосов и представителей смешанных рас, в соответствии с данными по населению в Википедии, взятыми из официальной переписи населения в США. Поскольку много комментариев к статье говорят о неправильности такого объединения, еще раз подчеркну: это объединение есть вынужденная мера, поскольку данные о преступности не делают такого разделения (выделяя расы строго по расовому, а не по этническому признаку).
-
Для настоящего исследования взяты только белая и черная расы; представители иных рас, а также те, чья раса не указана в источниках, не включены в исследование. Это ограничение сделано для упрощения, основываясь на том, что эти две категории составляют совместно более 80% всего населения США. При этом я не исключаю, что на будущих этапах будут добавлены и остальные расовые категории для полной картины.
Источники данных
Теперь поговорим о том, какие данные используются для исследования. Исходя из обозначенных целей нам нужны данные по:
-
совершенным преступлениям с указанием расовой принадлежности, видов преступления и штатов
-
гибели от рук полиции с указанием расовой принадлежности погибших и места события (штата)
-
численности населения по годам с указанием расовой принадлежности (для вычисления удельных показателей)
Для данных по преступлениям использовалась открытая база данных ФБР Crime Data Explorer, обладающая расширенным API и содержащая детальные данные по преступлениям, арестам, жертвам преступлений в США с 1991 по 2018 год.
Для данных по гибели от рук полиции использовалась открытая база данных на сайте Fatal Encounters, поддерживаемая сообществом. На настоящий момент база (доступная для скачивания) содержит более 28 тысяч записей начиная с 2000 года с подробной информацией о каждом погибшем, кратким описанием события, ссылками на СМИ, местом события и т.д. В Интернете есть и другие базы данных с тем же назначением, например, на сайте MappingPoliceViolence (около 8400 записей с 2013 г.) или БД Washington Post (ок. 5600 записей с 2015 г.). Но БД Fatal Encounters (FENC) на текущий момент самая подробная и имеет самый длинный период наблюдений (20 лет), поэтому я использовал ее. Кстати сказать, официальные источники (ФБР) также обещают открыть базу данных применения силы службами порядка, но это наступит только когда наберется представительная выборка данных. Прочитать об этой будущей официальной базе можно по ссылке.
Наконец, данные по общей численности представителей различных рас взяты из Википедии, которая в свою очередь, берет эти данные из официальных источников - Бюро переписи населения США. К сожалению, данные доступны только за промежуток с 2010 по 2018 год. В связи с этим в рамках данного исследования пришлось: 1) ограничить конечную точку наблюдений 2018 годом; 2) для промежутка с 2000 по 2009 год использовать данные по численности населения, смоделированные при помощи простой линейной регрессии (что вполне оправдано учитывая линейную природу прироста населения). Таким образом, мы будем исследовать все данные за период с 2000 г. (начальная точка в БД FENC) по 2018 г. (конечная точка в данных по численности населения). Все результаты будут основаны на наблюдениях за эти 18 лет.
Прежде чем приступить к анализу, необходимо загрузить вышеуказанные исходные данные в удобном виде и подготовить их для использования.
С данными по гибели от рук полиции все понятно: просто скачиваем всю БД с сайта и сохраняем как CSV (можно оставить и в XLSX, но я предпочитаю CSV для унификации и экономии). Здесь прямая ссылка на исходный датасет в Google Spreadsheets, здесь уже готовый CSV.
Поля данных (использованные в анализе выделены жирным шрифтом):
-
Unique ID - ID в БД
-
Subject's name - имя жертвы
-
Subject's age - возраст жертвы
-
Subject's gender - пол жертвы
-
Subject's race - раса жертвы (официально указанная)
-
Subject's race with imputations - раса жертвы (официально указанная или заполненная экспертом)
-
Imputation probability - вероятность экспертной оценки расы
-
URL of image of deceased - фото жертвы
-
Date of injury resulting in death (month/day/year) - дата события
-
Location of injury (address) - адрес события
-
Location of death (city) - город события
-
Location of death (state) - штат события
-
Location of death (zip code) - почтовый индекс адреса события
-
Location of death (county) - округ события
-
Full Address - полный адрес события
-
Latitude - координата широты
-
Longitude - координата долготы
-
Agency responsible for death - правоохранительная служба, причинившая смерть
-
Cause of death - причина смерти
-
A brief description of the circumstances surrounding the death - краткое описание обстоятельств
-
Dispositions/Exclusions INTERNAL USE, NOT FOR ANALYSIS - исключения (НЕ ДЛЯ АНАЛИЗА)
-
Intentional Use of Force (Developing) - применение силы (намеренное)
-
Link to news article or photo of official document - ссылка на СМИ
-
Symptoms of mental illness? INTERNAL USE, NOT FOR ANALYSIS - симптомы помешательства жертвы (НЕ ДЛЯ АНАЛИЗА)
-
Video - видео
-
Date&Description - дата и описание
-
Unique ID formula - формула ID
-
Unique identifier (redundant) - НЕ ИСПОЛЬЗУЕТСЯ
-
Date (Year) - год события
Данные по численности населения я сохранил с Википедии и при помощи Excel дополнил модельными данными за 2000 - 2009 гг., применив простую регрессию. Здесь можете взять Excel и итоговый CSV.
Поля данных (использованные в анализе выделены жирным шрифтом):
-
Year - год
-
Whitepop - численность белых
-
Blackpop - численность черных
-
Asianpop - численность азиатов
-
Native Hawaiianpop - численность гавайцев
-
American Indianpop - численность индейцев и эскимосов
-
Unknownpop - численность других рас / без указания расы
Самое интересное - это скачать и подготовить данные по преступлениям с БД ФБР. Для этого я написал программу на Python, которая подключается к публичному API при помощи API-ключа (который я специально получил на том же сайте). API использует REST для запросов к различным имеющимся базам данных и возвращает данные в виде JSON. Программа скачивает и объединяет данные в единый DataFrame, который затем сохраняется в CSV. В тот же файл добавляются и данные по численности населения с вычислением удельных показателей по преступлениям. Здесь итоговый CSV.
Поля данных (использованные в анализе выделены жирным шрифтом):
-
Year - год
-
Offense - вид преступления, одно из:
-
All Offenses - все преступления
-
Assault Offenses - нападения
-
Drugs Narcotic Offenses - преступления, связанные с оборотом наркотиков
-
Larceny Theft Offenses - воровство
-
Murder And Nonnegligent Manslaughter - убийство
-
Sex Offenses - преступления на сексуальной почве
-
Weapon Law Violation - нарушение хранения / оборота оружия
-
Class - классификатор (здесь это раса, но может быть также возраст, пол и т.д.)
-
Offender/Victim - данные по преступникам или жертвам (в этом анализе речь пока только о преступниках)
-
Asian - количество преступлений, совершенных азиатами
-
Native Hawaiian - количество преступлений, совершенных гавайцами
-
Black - количество преступлений, совершенных черными
-
American Indian - количество преступлений, совершенных индейцами и эскимосами
-
Unknown - количество преступлений, совершенных представителями других рас
-
White - количество преступлений, совершенных белыми
-
Whitepop - численность белых на соответствующий год
-
Blackpop - численность черных на соответствующий год
-
Asianpop - численность азиатов на соответствующий год
-
Native Hawaiianpop - численность гавайцев на соответствующий год
-
American Indianpop - численность индейцев и эскимосов на соответствующий год
-
Unknownpop - численность представителей других рас на соответствующий год
-
Asian pro capita - удельное количество преступлений, совершенных азиатами (на 1 человека)
-
Native Hawaiian pro capita - удельное количество преступлений, совершенных гавайцами (на 1 человека)
-
Black pro capita - удельное количество преступлений, совершенных черными (на 1 человека)
-
American Indian pro capita - удельное количество преступлений, совершенных индейцами и эскимосами (на 1 человека)
-
Unknown pro capita - удельное количество преступлений, совершенных представителями других рас (на 1 человека)
-
White pro capita - удельное количество преступлений, совершенных белыми (на 1 человека)
Инструменты
Весь анализ я провожу с помощью Python 3.8, используя интерактивный Jupyter Notebook. Дополнительные библиотеки:
Все это "добро" (включая сам Python) доступно мне из дистрибутива WinPython, который я давно использую на Windows из-за его очевидных преимуществ. Вы, конечно, можете использовать любой другой на ваш вкус (например Anaconda) или вообще обойтись просто Python, установив нужные пакеты.
Вообще же, этот же анализ можно с легкостью выполнить с помощью любого другого статистического / математического ПО: R, MatLab, SAS и даже Excel. Как говорится, выбирайте свое оружие :)
Часть 2.
В первой части статьи я описал предпосылки для исследования, его цели, допущения, исходные данные и инструменты. Сейчас можно без дальнейших разглагольствований сказать гагаринское...
Поехали!
Импортируем библиотеки и определяем путь к директории со всеми файлами:
import pandas as pd, numpy as np
# путь к папке с исходными файлами
ROOT_FOLDER = r'c:\_PROG_\Projects\us_crimes'
Гибель от рук закона

Начнем с анализа данных по жертвам полиции.
Давайте подгрузим файл из CSV в DataFrame:
# Файл с БД Fatal Encounters (FENC)
FENC_FILE = ROOT_FOLDER + '\\fatal_enc_db.csv'
# грузим в DataFrame
df_fenc = pd.read_csv(FENC_FILE, sep=';', header=0, usecols=["Date (Year)", "Subject's race with imputations", "Cause of death", "Intentional Use of Force (Developing)", "Location of death (state)"])
Заметьте сразу, что мы не грузим все поля из БД, а только необходимые нам для анализа: год, расовая принадлежность (с учетом экспертной оценки), причина смерти (здесь пока не используется, но может понадобиться в дальнейшем), признак намеренного применения силы и штат, в котором имело место событие.
Здесь надо пояснить, что такое "экспертная оценка" расовой принадлежности. Дело в том, что официальные источники, откуда FENC собирает данные, не всегда указывают расу жертвы, отсюда получаются пропуски в данных. Для компенсации этих пропусков сообщество привлекает экспертов, оценивающих расу жертвы по другим данным (с определенной погрешностью). Более подробно на эту тему можете почитать на самом сайте Fatal Encounters или загрузив исходный Excel файл (во втором листе).
Переименуем столбцы для удобства и очистим строки с пропущенными данными:
df_fenc.columns = ['Race', 'State', 'Cause', 'UOF', 'Year']
df_fenc.dropna(inplace=True)
Теперь нам надо унифицировать наименования расовой принадлежности для того, чтобы в дальнейшем сопоставлять эти данные с данными по преступлениям и численности населения. Классификация рас в этих источниках немного разная. БД FENC, в частности, выделяет латиноамериканцев (Hispanic/Latino), азиатов и уроженцев тихоокеанских территорий (Asian/Pacific Islander) и среднеазиатов (Middle Eastern). Нас же интересуют только белые и черные. Поэтому сделаем укрупнение:
df_fenc = df_fenc.replace({'Race': {'European-American/White': 'White', 'African-American/Black': 'Black',
'Hispanic/Latino': 'White', 'Native American/Alaskan': 'American Indian',
'Asian/Pacific Islander': 'Asian', 'Middle Eastern': 'Asian',
'NA': 'Unknown', 'Race unspecified': 'Unknown'}}, value=None)
Оставляем только данные по белым (теперь с учетом латино) и черным:
df_fenc = df_fenc.loc[df_fenc['Race'].isin(['White', 'Black'])]
Зачем нам поле "UOF" (намеренное использование силы)? Для исследования мы хотим оставить только случаи, когда полиция (или иные правоохранительные органы) намеренно применяли силу против человека. Мы опускаем случаи, когда человек совершил самоубийство (например, в результате осады полицией) или погиб в результате ДТП, преследуемый полицейскими. Это допущение сделано по двум причинам: 1) обстоятельства гибели по косвенным причинам часто не позволяют провести прямую причинно-следственную связь между действиями правоохранительных органов и смертью (пример: полицейский держит на мушке человека, который затем умирает от сердечного приступа; другой пример: при задержании преступник пускает себе пулю в лоб); 2) при рассмотрении действий властей расценивается именно применение силы; так, например, будущая официальная БД по применению силы (которую я упомянул в предыдущей статье) будет содержать именно данные, отражающая намеренное применение смертельной силы против граждан. Итак, оставляем только эти данные:
df_fenc = df_fenc.loc[df_fenc['UOF'].isin(['Deadly force', 'Intentional use of force'])]
Для удобства добавим полные названия штатов. Для этого я приготовил отдельный CSV, который мы и подгрузим в наш датасет:
df_state_names = pd.read_csv(ROOT_FOLDER + '\\us_states.csv', sep=';', header=0)
df_fenc = df_fenc.merge(df_state_names, how='inner', left_on='State', right_on='state_abbr')
Отобразим начальные строки командой df_fenc.head(), чтобы получить представление о датасете:
|
|
Race
|
State
|
Cause
|
UOF
|
Year
|
state_name
|
state_abbr
|
|---|
|
0
|
Black
|
GA
|
Gunshot
|
Deadly force
|
2000
|
Georgia
|
GA
|
|---|
|
1
|
Black
|
GA
|
Gunshot
|
Deadly force
|
2000
|
Georgia
|
GA
|
|---|
|
2
|
Black
|
GA
|
Gunshot
|
Deadly force
|
2000
|
Georgia
|
GA
|
|---|
|
3
|
Black
|
GA
|
Gunshot
|
Deadly force
|
2000
|
Georgia
|
GA
|
|---|
|
4
|
Black
|
GA
|
Gunshot
|
Deadly force
|
2000
|
Georgia
|
GA
|
|---|
Нам не нужно разбирать отдельные случаи гибели, давайте агрегируем данные по годам и расовой принадлежности:
# группируем по году и расе
ds_fenc_agg = df_fenc.groupby(['Year', 'Race']).count()['Cause']
df_fenc_agg = ds_fenc_agg.unstack(level=1)
# конвертируем численные данные в UINT16 для экономии
df_fenc_agg = df_fenc_agg.astype('uint16')
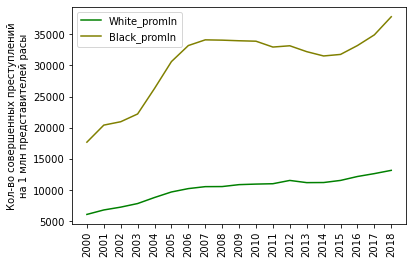
В итоге получили таблицу с 2 столбцами: White (количество белых жертв) и Black (количество черных жертв), индексированную по годам (с 2000 по 2020). Давайте взглянем на эти данные в виде графика:
# белые и черные жертвы полицейских по годам (кол-во гибелей)
plt = df_fenc_agg.plot(xticks=df_fenc_agg.index, color=['olive', 'g'])
plt.set_xticklabels(df_fenc_agg.index, rotation='vertical')
plt.set_xlabel('')
plt.set_ylabel('Кол-во жертв от рук полиции')
plt
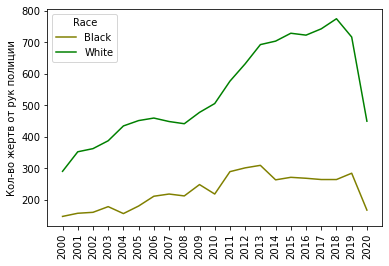
Промежуточный вывод:
В количественном (абсолютном) выражении белых жертв больше, чем черных.
Разница между этими данными составляет в среднем 2.4 раза. Напрашивается справедливое заключение о том, что это связано с разницей в численности белых и черных. Что же, давайте посмотрим теперь на удельные показатели.
Подгрузим данные по численности населения (по расам):
# файл CSV с данными по населению (1991 - 2018)
POP_FILE = ROOT_FOLDER + '\\us_pop_1991-2018.csv'
df_pop = pd.read_csv(POP_FILE, index_col=0, dtype='int64')
Добавим эти данные в наш датасет:
# выбираем только данные по числ-ти белых и черных за 2000 - 2018 гг.
df_pop = df_pop.loc[2000:2018, ['White_pop', 'Black_pop']]
# объединяем датафреймы, выкидываем строки с пропусками
df_fenc_agg = df_fenc_agg.join(df_pop)
df_fenc_agg.dropna(inplace=True)
# конвертируем данные по численности в целочисленный тип
df_fenc_agg = df_fenc_agg.astype({'White_pop': 'uint32', 'Black_pop': 'uint32'})
ОК. Осталось создать 2 столбца с удельными значениями, разделив количество жертв на численность и умножив на миллион (количество жертв на 1 млн. человек):
df_fenc_agg['White_promln'] = df_fenc_agg['White'] * 1e6 / df_fenc_agg['White_pop']
df_fenc_agg['Black_promln'] = df_fenc_agg['Black'] * 1e6 / df_fenc_agg['Black_pop']
Смотрим, что получилось:
|
|
Black
|
White
|
White_pop
|
Black_pop
|
White_promln
|
Black_promln
|
|---|
|
Year
|
|
|
|
|
|
|
|---|
|
2000
|
148
|
291
|
218756353
|
35410436
|
1.330247
|
4.179559
|
|---|
|
2001
|
158
|
353
|
219843871
|
35758783
|
1.605685
|
4.418495
|
|---|
|
2002
|
161
|
363
|
220931389
|
36107130
|
1.643044
|
4.458953
|
|---|
|
2003
|
179
|
388
|
222018906
|
36455476
|
1.747599
|
4.910099
|
|---|
|
2004
|
157
|
435
|
223106424
|
36803823
|
1.949742
|
4.265861
|
|---|
|
2005
|
181
|
452
|
224193942
|
37152170
|
2.016112
|
4.871855
|
|---|
|
2006
|
212
|
460
|
225281460
|
37500517
|
2.041890
|
5.653255
|
|---|
|
2007
|
219
|
449
|
226368978
|
37848864
|
1.983487
|
5.786171
|
|---|
|
2008
|
213
|
442
|
227456495
|
38197211
|
1.943229
|
5.576323
|
|---|
|
2009
|
249
|
478
|
228544013
|
38545558
|
2.091501
|
6.459888
|
|---|
|
2010
|
219
|
506
|
229397472
|
38874625
|
2.205778
|
5.633495
|
|---|
|
2011
|
290
|
577
|
230838975
|
39189528
|
2.499578
|
7.399936
|
|---|
|
2012
|
302
|
632
|
231992377
|
39623138
|
2.724227
|
7.621809
|
|---|
|
2013
|
310
|
693
|
232969901
|
39919371
|
2.974633
|
7.765653
|
|---|
|
2014
|
264
|
704
|
233963128
|
40379066
|
3.009021
|
6.538041
|
|---|
|
2015
|
272
|
729
|
234940100
|
40695277
|
3.102919
|
6.683822
|
|---|
|
2016
|
269
|
723
|
234644039
|
40893369
|
3.081263
|
6.578084
|
|---|
|
2017
|
265
|
743
|
235507457
|
41393491
|
3.154889
|
6.401973
|
|---|
|
2018
|
265
|
775
|
236173020
|
41617764
|
3.281493
|
6.367473
|
|---|
Последние 2 столбца - наши удельные показатели на миллион человек по каждой из двух рас. Пора посмотреть на графике:
plt = df_fenc_agg.loc[:, ['White_promln', 'Black_promln']].plot(xticks=df_fenc_agg.index, color=['g', 'olive'])
plt.set_xticklabels(df_fenc_agg.index, rotation='vertical')
plt.set_xlabel('')
plt.set_ylabel('Кол-во жертв от рук полиции\nна 1 млн представителей расы')
plt
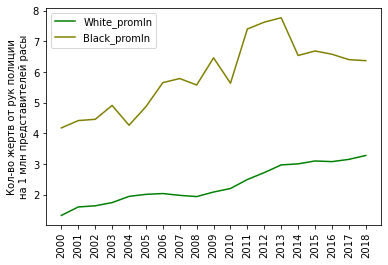
Также выведем основную статистику по этим данным:
df_fenc_agg.loc[:, ['White_promln', 'Black_promln']].describe()
|
|
White_promln
|
Black_promln
|
|---|
|
count (количество)
|
19.000000
|
19.000000
|
|---|
|
mean (среднее арифм.)
|
2.336123
|
5.872145
|
|---|
|
std (станд. отклонение)
|
0.615133
|
1.133677
|
|---|
|
min (мин. значение)
|
1.330247
|
4.179559
|
|---|
|
25%
|
1.946485
|
4.890977
|
|---|
|
50%
|
2.091501
|
5.786171
|
|---|
|
75%
|
2.991827
|
6.558062
|
|---|
|
max (макс. значение)
|
3.281493
|
7.765653
|
|---|
Промежуточные выводы:
1. В среднем от рук полиции погибает 5.9 на 1 млн. черных и 2.3 на 1 млн. белых (черных в 2.6 раз больше).
2. Разброс (отклонение) в данных по черным жертвам в 1.8 раз выше, чем в данных по белым жертвам. (На графике видно, что кривая по белым жертвам гораздо более плавная, без резких скачков.)
3. Максимальное количество жертв среди черных - в 2013 г. (7.7 на миллион); максимальное количество жертв среди белых - в 2018 г. (3.3 на миллион).
4. Жертвы среди белых монотонно растут (в среднем на 0.1 - 0.2 в год), в то время как жертвы среди черных вернулись на уровень 2009 г. после пика в 2011 - 2013 гг.
Итак, на первый поставленный вопрос мы ответили:
- Можно ли сказать, что полицейские убивают черных чаще, чем белых?
- Да, это верный вывод. От рук закона черных гибнет в среднем в 2.6 раз больше, чем белых.
Держа в голове эти промежуточные выводы, идем дальше - посмотрим данные по преступлениям, чтобы понять, как они соотносятся с расовой принадлежностью и жертвами от рук стражей закона.
Данные по преступлениям

Загружаем наш CSV по преступлениям:
CRIMES_FILE = ROOT_FOLDER + '\\culprits_victims.csv'
df_crimes = pd.read_csv(CRIMES_FILE, sep=';', header=0, index_col=0, usecols=['Year', 'Offense', 'Offender/Victim', 'White', 'White pro capita', 'Black', 'Black pro capita'])
Здесь опять-таки используем только необходимые столбцы: год, вид преступления, классификатор и данные по количеству преступлений, совершенных черными и белыми (абсолютные - "White", "Black" и удельные на человека - "White pro capita", "Black pro capita").
Взглянем на данные (`df_crimes.head()`):
|
|
Offense
|
Offender/Victim
|
Black
|
White
|
Black pro capita
|
White pro capita
|
|---|
|
Year
|
|
|
|
|
|
|
|---|
|
1991
|
All Offenses
|
Offender
|
490
|
598
|
1.518188e-05
|
2.861673e-06
|
|---|
|
1991
|
All Offenses
|
Offender
|
4
|
4
|
1.239337e-07
|
1.914160e-08
|
|---|
|
1991
|
All Offenses
|
Offender
|
508
|
122
|
1.573958e-05
|
5.838195e-07
|
|---|
|
1991
|
All Offenses
|
Offender
|
155
|
176
|
4.802432e-06
|
8.422314e-07
|
|---|
|
1991
|
All Offenses
|
Offender
|
13
|
19
|
4.027846e-07
|
9.092270e-08
|
|---|
Нам пока не нужны данные по жертвам преступлений. Убираем лишние данные и столбцы:
# оставляем только преступников (убираем жертв)
df_crimes1 = df_crimes.loc[df_crimes['Offender/Victim'] == 'Offender']
# берем исследуемый период (2000-2018) и удаляем лишние столбцы
df_crimes1 = df_crimes1.loc[2000:2018, ['Offense', 'White', 'White pro capita', 'Black', 'Black pro capita']]
Получили такой датасет (1295 строк * 5 столбцов):
|
|
Offense
|
White
|
White pro capita
|
Black
|
Black pro capita
|
|---|
|
Year
|
|
|
|
|
|
|---|
|
2000
|
All Offenses
|
679
|
0.000003
|
651
|
0.000018
|
|---|
|
2000
|
All Offenses
|
11458
|
0.000052
|
30199
|
0.000853
|
|---|
|
2000
|
All Offenses
|
4439
|
0.000020
|
3188
|
0.000090
|
|---|
|
2000
|
All Offenses
|
10481
|
0.000048
|
5153
|
0.000146
|
|---|
|
2000
|
All Offenses
|
746
|
0.000003
|
63
|
0.000002
|
|---|
|
...
|
...
|
...
|
...
|
...
|
...
|
|---|
|
2018
|
Larceny Theft Offenses
|
1961
|
0.000008
|
1669
|
0.000040
|
|---|
|
2018
|
Larceny Theft Offenses
|
48616
|
0.000206
|
30048
|
0.000722
|
|---|
|
2018
|
Drugs Narcotic Offenses
|
555974
|
0.002354
|
223398
|
0.005368
|
|---|
|
2018
|
Drugs Narcotic Offenses
|
305052
|
0.001292
|
63785
|
0.001533
|
|---|
|
2018
|
Weapon Law Violation
|
70034
|
0.000297
|
58353
|
0.001402
|
|---|
Теперь нам надо превратить удельные показатели на 1 человека в удельные на 1 миллион (так как именно эти данные используются во всем исследовании). Для этого просто умножаем на миллион соответствующие столбцы:
df_crimes1['White_promln'] = df_crimes1['White pro capita'] * 1e6
df_crimes1['Black_promln'] = df_crimes1['Black pro capita'] * 1e6
Чтобы увидеть целую картину, как соотносится количество преступлений между белыми и черными по видам преступлений (в абсолютном выражении), просуммируем годовые наблюдения:
df_crimes_agg = df_crimes1.groupby(['Offense']).sum().loc[:, ['White', 'Black']]
|
|
White
|
Black
|
|---|
|
Offense
|
|
|
|---|
|
All Offenses
|
44594795
|
22323144
|
|---|
|
Assault Offenses
|
12475830
|
7462272
|
|---|
|
Drugs Narcotic Offenses
|
9624596
|
3453140
|
|---|
|
Larceny Theft Offenses
|
9563917
|
4202235
|
|---|
|
Murder And Nonnegligent Manslaughter
|
28913
|
39617
|
|---|
|
Sex Offenses
|
833088
|
319366
|
|---|
|
Weapon Law Violation
|
829485
|
678861
|
|---|
Или в виде графика:
plt = df_crimes_agg.plot.barh(color=['g', 'olive'])
plt.set_ylabel('Вид преступления')
plt.set_xlabel('Кол-во совершенных преступлений (за 2000 - 2018 гг)')
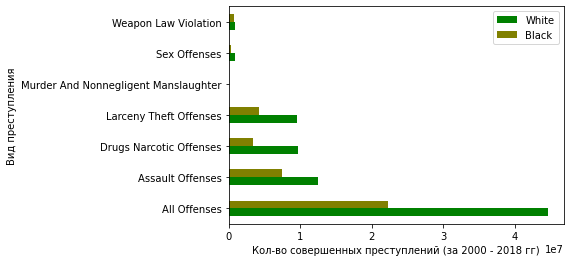
Итак, видим, что:
-
В количественном отношении нападения, наркотики, воровство и "все преступления" сильно превалируют над преступлениями, связанными с убийством, оружием и сексом
-
В абсолютных значениях белые совершают больше преступлений, чем черные (ровно в 2 раза для категории "все преступления")
Опять понимаем, что без информации о численности никакие выводы о "криминальности" рас не сделаешь. Соответственно, посмотрим на удельные показатели:
df_crimes_agg1 = df_crimes1.groupby(['Offense']).sum().loc[:, ['White_promln', 'Black_promln']]
|
|
White_promln
|
Black_promln
|
|---|
|
Offense
|
|
|
|---|
|
All Offenses
|
194522.307758
|
574905.952459
|
|---|
|
Assault Offenses
|
54513.398833
|
192454.602875
|
|---|
|
Drugs Narcotic Offenses
|
41845.758869
|
88575.523095
|
|---|
|
Larceny Theft Offenses
|
41697.303725
|
108189.184125
|
|---|
|
Murder And Nonnegligent Manslaughter
|
125.943007
|
1016.403706
|
|---|
|
Sex Offenses
|
3633.777035
|
8225.144985
|
|---|
|
Weapon Law Violation
|
3612.671402
|
17389.163849
|
|---|
И на графике:
plt = df_crimes_agg1.plot.barh(color=['g', 'olive'])
plt.set_ylabel('Вид преступления')
plt.set_xlabel('Кол-во совершенных преступлений на 1 млн представителей расы (за 2000 - 2018 гг)')
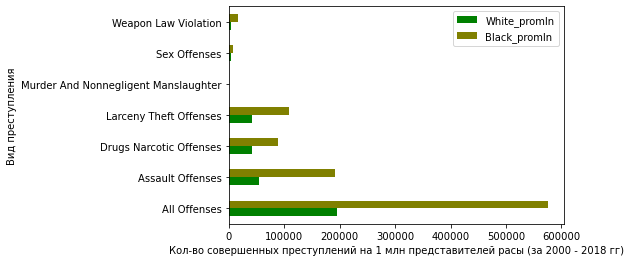
Здесь уже совсем иная картина. По всем видам преступлений (из анализируемых) черные совершают больше, чем белые. По категории "все преступления" эта разница составляет почти 3 раза.
Давайте теперь оставим только категорию "все преступления" (All Offenses) как наиболее представительную, только удельные показатели по преступлениям (на миллион человек) и сгруппируем данные по годам (так как в исходных данных на каждый год может быть несколько записей - по количеству служб, предоставивших данные).
# оставляем только 'All Offenses' = все преступления
df_crimes1 = df_crimes1.loc[df_crimes1['Offense'] == 'All Offenses']
# чтобы использовать другую выборку, можем, например, оставить нападения и убийства:
#df_crimes1 = df_crimes1.loc[df_crimes1['Offense'].str.contains('Assault|Murder')]
# убираем абсолютные значения и агрегируем по годам
df_crimes1 = df_crimes1.groupby(level=0).sum().loc[:, ['White_promln', 'Black_promln']]
Полученный датасет:
|
|
White_promln
|
Black_promln
|
|---|
|
Year
|
|
|
|---|
|
2000
|
6115.058976
|
17697.409882
|
|---|
|
2001
|
6829.701429
|
20431.707645
|
|---|
|
2002
|
7282.333249
|
20972.838329
|
|---|
|
2003
|
7857.691182
|
22218.966500
|
|---|
|
2004
|
8826.576863
|
26308.815799
|
|---|
|
2005
|
9713.826255
|
30616.569637
|
|---|
|
2006
|
10252.894313
|
33189.382429
|
|---|
|
2007
|
10566.527362
|
34100.495064
|
|---|
|
2008
|
10580.520024
|
34052.276749
|
|---|
|
2009
|
10889.263592
|
33954.651792
|
|---|
|
2010
|
10977.017218
|
33884.236826
|
|---|
|
2011
|
11035.346176
|
32946.454471
|
|---|
|
2012
|
11562.836825
|
33150.706035
|
|---|
|
2013
|
11211.113491
|
32207.571607
|
|---|
|
2014
|
11227.354594
|
31517.346141
|
|---|
|
2015
|
11564.786088
|
31764.865490
|
|---|
|
2016
|
12193.026562
|
33186.064958
|
|---|
|
2017
|
12656.261666
|
34900.390499
|
|---|
|
2018
|
13180.171893
|
37805.202605
|
|---|
Посмотрим на графике:
plt = df_crimes1.plot(xticks=df_crimes1.index, color=['g', 'olive'])
plt.set_xticklabels(df_fenc_agg.index, rotation='vertical')
plt.set_xlabel('')
plt.set_ylabel('Кол-во совершенных преступлений\nна 1 млн представителей расы')
plt
Промежуточные выводы:
1. Белые совершают в 2 раза больше преступлений, чем черные, в абсолютном выражении, но в 3 раза меньше в относительном выражении (на миллион представителей своей расы).
2. Преступность среди белых относительно монотонно растет на протяжении всего периода (выросла в 2 раза за 18 лет). Преступность среди черных также растет, но скачкообразно: с 2001 по 2006 г. резкий рост, с 2007 по 2016 она даже убывала, с 2017 года опять резкий рост. За весь период преступность среди черных выросла также в 2 раза (аналогично белым).
3. Если не принимать во внимание спад среди черной преступности в 2007-2016 гг., преступность среди черных растет более быстрыми темпами, чем среди белых.
Итак, мы ответили на второй вопрос:
- Представители какой расы статистически чаще совершают преступления?
- Черные статистически совершают преступления в 3 раза чаще белых.
Криминальность и гибель от рук полиции
Теперь мы подошли к самому важному: необходимо ответить на третий поставленный вопрос, а именно "Можно ли сказать, что полиция стреляет насмерть пропорционально количеству совершаемых преступлений?"
То есть надо как-то проследить корреляцию между двумя нашими наборами данных - данных по жертвам полиции и данных по преступлениям.
Начнем с того, что объединим эти два датасета в один:
# объединяем датасеты
df_uof_crimes = df_fenc_agg.join(df_crimes1, lsuffix='_uof', rsuffix='_cr')
# удаляем лишние столбцы (абс. показатели по жертвам)
df_uof_crimes = df_uof_crimes.loc[:, 'White_pop':'Black_promln_cr']
Что получили?
|
|
White_pop
|
Black_pop
|
White_promln_uof
|
Black_promln_uof
|
White_promln_cr
|
Black_promln_cr
|
|---|
|
Year
|
|
|
|
|
|
|
|---|
|
2000
|
218756353
|
35410436
|
1.330247
|
4.179559
|
6115.058976
|
17697.409882
|
|---|
|
2001
|
219843871
|
35758783
|
1.605685
|
4.418495
|
6829.701429
|
20431.707645
|
|---|
|
2002
|
220931389
|
36107130
|
1.643044
|
4.458953
|
7282.333249
|
20972.838329
|
|---|
|
2003
|
222018906
|
36455476
|
1.747599
|
4.910099
|
7857.691182
|
22218.966500
|
|---|
|
2004
|
223106424
|
36803823
|
1.949742
|
4.265861
|
8826.576863
|
26308.815799
|
|---|
|
2005
|
224193942
|
37152170
|
2.016112
|
4.871855
|
9713.826255
|
30616.569637
|
|---|
|
2006
|
225281460
|
37500517
|
2.041890
|
5.653255
|
10252.894313
|
33189.382429
|
|---|
|
2007
|
226368978
|
37848864
|
1.983487
|
5.786171
|
10566.527362
|
34100.495064
|
|---|
|
2008
|
227456495
|
38197211
|
1.943229
|
5.576323
|
10580.520024
|
34052.276749
|
|---|
|
2009
|
228544013
|
38545558
|
2.091501
|
6.459888
|
10889.263592
|
33954.651792
|
|---|
|
2010
|
229397472
|
38874625
|
2.205778
|
5.633495
|
10977.017218
|
33884.236826
|
|---|
|
2011
|
230838975
|
39189528
|
2.499578
|
7.399936
|
11035.346176
|
32946.454471
|
|---|
|
2012
|
231992377
|
39623138
|
2.724227
|
7.621809
|
11562.836825
|
33150.706035
|
|---|
|
2013
|
232969901
|
39919371
|
2.974633
|
7.765653
|
11211.113491
|
32207.571607
|
|---|
|
2014
|
233963128
|
40379066
|
3.009021
|
6.538041
|
11227.354594
|
31517.346141
|
|---|
|
2015
|
234940100
|
40695277
|
3.102919
|
6.683822
|
11564.786088
|
31764.865490
|
|---|
|
2016
|
234644039
|
40893369
|
3.081263
|
6.578084
|
12193.026562
|
33186.064958
|
|---|
|
2017
|
235507457
|
41393491
|
3.154889
|
6.401973
|
12656.261666
|
34900.390499
|
|---|
|
2018
|
236173020
|
41617764
|
3.281493
|
6.367473
|
13180.171893
|
37805.202605
|
|---|
Давайте вспомним, что хранится в каждом поле:
-
White_pop - численность белых
-
Black_pop - численность черных
-
White promln_uof - количество жертв полиции среди белых (на 1 млн)
-
Black promln_uof - количество жертв полиции среди черных (на 1 млн)
-
White promln_cr - количество преступлений, совершенных белыми (на 1 млн)
-
Black promln_cr - количество преступлений, совершенных черными (на 1 млн)
Наверное, можно было бы не полениться и дать этим столбцам русские названия... Но я надеюсь, читатели меня простят :)
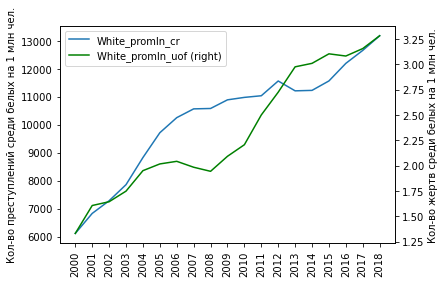
Взглянем, как соотносятся графики преступлений и жертв полиции для каждой расы. Начнем с белых - в шахматном порядке :)
plt = df_uof_crimes['White_promln_cr'].plot(xticks=df_uof_crimes.index, legend=True)
plt.set_ylabel('Кол-во преступлений среди белых на 1 млн чел.')
plt2 = df_uof_crimes['White_promln_uof'].plot(xticks=df_uof_crimes.index, legend=True, secondary_y=True, style='g')
plt2.set_ylabel('Кол-во жертв среди белых на 1 млн чел.', rotation=90)
plt2.set_xlabel('')
plt.set_xlabel('')
plt.set_xticklabels(df_uof_crimes.index, rotation='vertical')
plt
То же самое на диаграмме рассеяния:
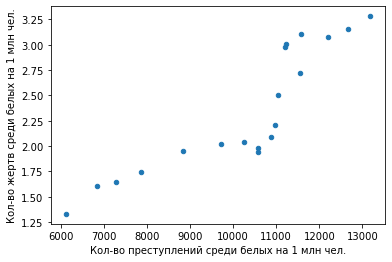
Отметим мимоходом, что определенная корреляция есть. ОК, теперь то же для черных:
plt = df_uof_crimes['Black_promln_cr'].plot(xticks=df_uof_crimes.index, legend=True)
plt.set_ylabel('Кол-во преступлений среди черных на 1 млн чел.')
plt2 = df_uof_crimes['Black_promln_uof'].plot(xticks=df_uof_crimes.index, legend=True, secondary_y=True, style='g')
plt2.set_ylabel('Кол-во жертв среди черных на 1 млн чел.', rotation=90)
plt2.set_xlabel('')
plt.set_xlabel('')
plt.set_xticklabels(df_uof_crimes.index, rotation='vertical')
plt
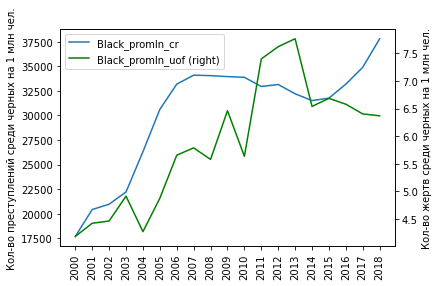
И скаттерплот:
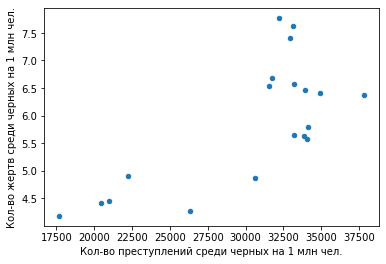
Здесь все намного хуже: тренды явно "пляшут", хотя общая тенденция все равно прослеживается: пропорция здесь явно прямая, хотя и нелинейная.
Давайте воспользуемся методами матстатистики для определения величины этих корреляций, построив корреляционную матрицу на основе коэффициента Пирсона:
df_corr = df_uof_crimes.loc[:, ['White_promln_cr', 'White_promln_uof', 'Black_promln_cr', 'Black_promln_uof']].corr(method='pearson')
df_corr.style.background_gradient(cmap='PuBu')
Получаем такую картинку:
|
|
White_promln_cr
|
White_promln_uof
|
Black_promln_cr
|
Black_promln_uof
|
|---|
|
White_promln_cr
|
1.000000
|
0.885470
|
0.949909
|
0.802529
|
|---|
|
White_promln_uof
|
0.885470
|
1.000000
|
0.710052
|
0.795486
|
|---|
|
Black_promln_cr
|
0.949909
|
0.710052
|
1.000000
|
0.722170
|
|---|
|
Black_promln_uof
|
0.802529
|
0.795486
|
0.722170
|
1.000000
|
|---|
Коэффициенты корреляции для обеих рас выделены жирным: для белых = 0.885, для черных = 0.722. Таким образом, положительная корреляция между гибелью от полиции и преступностью прослеживается и для белых, и для черных, но для белых она гораздо выше (статистически значима), в то время как для черных она близка к статистической незначимости. Последний результат, конечно, связан с большей неоднородностью данных как по жертвам полиции, так и по преступлениям среди черных.
Напоследок для этой статьи попробуем выяснить, какова вероятность белых и черных преступников быть застреленным полицией. Прямых способом это выяснить у нас нет (нет данных по тому, кто из погибших от рук полиции был зарегистрирован как преступник, а кто как невинная жертва). Поэтому пойдем простым путем: разделим удельное количество жертв полиции на удельное количество преступлений по каждой расовой группе (и умножим на 100, чтобы выразить в %):
# агрегированные значения (по годам)
df_uof_crimes_agg = df_uof_crimes.loc[:, ['White_promln_cr', 'White_promln_uof', 'Black_promln_cr', 'Black_promln_uof']].agg(['mean', 'sum', 'min', 'max'])
# "вероятность" преступника быть застреленным
df_uof_crimes_agg['White_uof_cr'] = df_uof_crimes_agg['White_promln_uof'] * 100. / df_uof_crimes_agg['White_promln_cr']
df_uof_crimes_agg['Black_uof_cr'] = df_uof_crimes_agg['Black_promln_uof'] * 100. / df_uof_crimes_agg['Black_promln_cr']
Получаем такие данные:
|
|
White_promln_cr
|
White_promln_uof
|
Black_promln_cr
|
Black_promln_uof
|
White_uof_cr
|
Black_uof_cr
|
|---|
|
mean
|
10238.016198
|
2.336123
|
30258.208024
|
5.872145
|
0.022818
|
0.019407
|
|---|
|
sum
|
194522.307758
|
44.386338
|
574905.952459
|
111.570747
|
0.022818
|
0.019407
|
|---|
|
min
|
6115.058976
|
1.330247
|
17697.409882
|
4.179559
|
0.021754
|
0.023617
|
|---|
|
max
|
13180.171893
|
3.281493
|
37805.202605
|
7.765653
|
0.024897
|
0.020541
|
|---|
Отобразим полученные значения в виде столбчатой диаграммы:
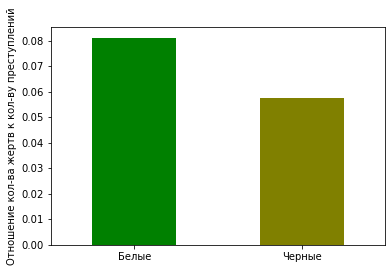
plt = df_uof_crimes_agg.loc['mean', ['White_uof_cr', 'Black_uof_cr']].plot.bar(color=['g', 'olive'])
plt.set_ylabel('Отношение кол-ва жертв к кол-ву преступлений')
plt.set_xticklabels(['Белые', 'Черные'], rotation=0)
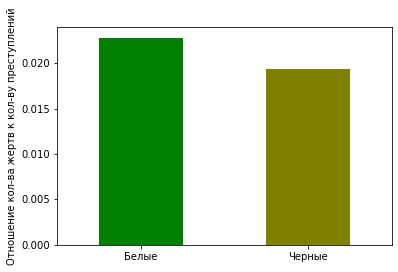
На диаграмме видно, что вероятность белого преступника быть застреленным несколько выше, чем черного преступника. Конечно, этот анализ весьма условный, но все же дает какое-то представление.
Промежуточные выводы:
1. Гибель от рук полиции связана с криминальностью (количеством совершаемых преступлений). При этом эта корреляция неоднородна по расам: для белых она близка к идеальной, для черных далека от идеальной.
2. При рассмотрении совмещенных диаграмм гибели от полиции и преступности видно, что фатальные встречи с полицией растут "в ответ" на рост преступности, с лагом в несколько лет (особенно видно по данным среди черных). Это согласуется с логическим предположением о том, что власти "отвечают" на преступность (больше преступлений -> больше безнаказанности -> больше стычек с представителями закона -> больше смертельных исходов).
3. Белые преступники немного чаще встречают смерть от рук полиции, чем черные. Однако эта разница почти несущественна.
Итак, ответ на третий вопрос:
- Можно ли сказать, что полиция стреляет насмерть пропорционально количеству совершаемых преступлений?
- Да, такая корреляция наблюдается, хотя она неоднородна по расам: для белых почти идеальная, для черных - почти неидеальная.
Часть 3.
Сегодня, как я обещал, посмотрим на географическое распределение этих данных по отдельным штатам США, что должно либо подтвердить, либо опровергнуть выводы, сделанные в масштабах всей страны.
Однако, прежде чем мы займемся этой географией, давайте сделаем шаг назад и посмотрим, что будет, если вместо категории "все преступления" (All Offenses) в качестве исходных данных по преступности взять только самые "злодейские". Многие из моих читателей указали в комментариях, что это будет правильнее, так как "все преступления" включают, например, мелкое воровство или торговлю наркотиками, что (по логике) не должно быть связано с агрессивным поведением, провоцирующим полицейских на стрельбу. Хотя я лично не могу целиком с этим согласиться и считаю, что любое совершенное преступление может повлечь за собой повышенное внимание со стороны полиции (которое, в свою очередь, может кончиться не лучшим образом)... все же, давайте проявим любопытство и посмотрим!
Нападения и убийства вместо "всех преступлений"
Итак, в том месте, где мы формируем датасет по преступлениям, вместо строки
df_crimes1 = df_crimes1.loc[df_crimes1['Offense'] == 'All Offenses']
пишем:
df_crimes1 = df_crimes1.loc[df_crimes1['Offense'].str.contains('Assault|Murder')]
Таким образом, наш новый фильтр включает виды преступлений, связанных с нападением (Assault) и убийством (Murder). Замечу сразу, что этот набор данных не включает непредумышленное убийство и убийство в рамках самозащиты, а только умышленное убийство.
Весь остальной код оставляем без изменений. Вот что дает перерасчет данных.
Удельное количество преступлений на миллион представителей расы:
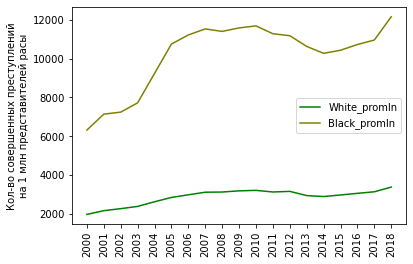
Видим, что порядок меньше, но графики почти идентичны предыдущим (по всем преступлениям).
Связь между преступностью и жертвами полиции:

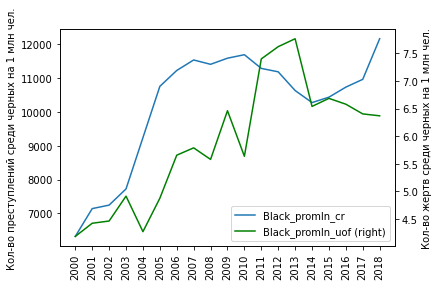
Корреляционная матрица:
|
|
White_promln_cr
|
White_promln_uof
|
Black_promln_cr
|
Black_promln_uof
|
|---|
|
White_promln_cr
|
1.000000
|
0.684757
|
0.986622
|
0.729674
|
|---|
|
White_promln_uof
|
0.684757
|
1.000000
|
0.614132
|
0.795486
|
|---|
|
Black_promln_cr
|
0.986622
|
0.614132
|
1.000000
|
0.680893
|
|---|
|
Black_promln_uof
|
0.729674
|
0.795486
|
0.680893
|
1.000000
|
|---|
Как видим, согласованность в этом случае хуже (0.68 против 0.88 и 0.72 по данным всех преступлений). Но радует здесь, по крайней мере, что коэффициенты корреляции почти не различаются между белыми и черными, т.е. можно сказать, что между преступлениями и жертвами полиции есть некая постоянная корреляция.
Ну, и наш "самодельный" индекс - отношение количества жертв полиции к количеству преступлений:
Здесь разница между расами выглядит еще более заметной, чем в прошлый раз. Вывод тот же - белые преступники чаще гибнут от рук полиции, чем черные.
Таким образом, все сделанные выводы остаются в силе.
Что ж, теперь - уроки географии! :)
Для анализа преступности по штатам я использовал другие исходные датасеты из базы данных ФБР, а именно:
К сожалению, получить качественные данные по совершенным преступлениям, штатам и расовому признаку не удалось, как я ни бился: возвращаемые результаты далеко не полные, в частности, отсутствует информация по некоторым штатам. Но и этих данных вполне достаточно для нашего скромного анализа.
Первый набор содержит данные о количестве преступлений по всем 51 штату с 1991 по 2018 год, по следующим видам преступлений:
-
violent crime: все насильственные преступления (убийство, грабеж, изнасилование и нападение с отягчающими обстоятельствами), см. определение на сайте ФБР;
-
homicide: убийство
-
rape legacy: изнасилование (по старым меркам - до 2013 г.)
-
rape revised: изнасилование (по новым меркам - начиная с 2013 г.)
-
robbery: грабеж
-
aggravated assault: нападение с отягчающими обстоятельствами
-
property crime: преступления против собственности
-
burglary: взлом / проникновение в собственность
-
larceny: хищение
-
motor vehicle theft: угон автотранспорта
-
arson: поджог
Для целей настоящего исследования мы будем использовать количество насильственных преступлений (violent crime), что согласуется с вышеизложенной логикой.
Второй набор содержит данные по количествам преступлений по 51 штату с 2000 по 2018 год, с разбивкой по расам (выделяемые расовые категории - см. в предыдущей статье). Поскольку БД по арестам имеет несколько другую разбивку по типам преступлений и не имеет готового набора по насильственным преступлениям, исходный запрос и результаты содержат 4 вида соответствующих правонарушений (убийство, грабеж, изнасилование и нападение с отягчающими обстоятельствами).
География преступности без расовой принадлежности
Для начала посмотрим на количество совершаемых преступлений насильственного характера по штатам без расовой принадлежности преступников:
import pandas as pd, numpy as np
CRIME_STATES_FILE = ROOT_FOLDER + '\\crimes_by_state.csv'
df_crime_states = pd.read_csv(CRIME_STATES_FILE, sep=';', header=0,
usecols=['year', 'state_abbr', 'population', 'violent_crime'])
Загруженные данные:
|
|
year
|
state_abbr
|
population
|
violent_crime
|
|---|
|
0
|
2016
|
AL
|
4860545
|
25878
|
|---|
|
1
|
1996
|
AL
|
4273000
|
24159
|
|---|
|
2
|
1997
|
AL
|
4319000
|
24379
|
|---|
|
3
|
1998
|
AL
|
4352000
|
22286
|
|---|
|
4
|
1999
|
AL
|
4369862
|
21421
|
|---|
|
...
|
...
|
...
|
...
|
...
|
|---|
|
1423
|
2000
|
DC
|
572059
|
8626
|
|---|
|
1424
|
2001
|
DC
|
573822
|
9195
|
|---|
|
1425
|
2002
|
DC
|
569157
|
9322
|
|---|
|
1426
|
2003
|
DC
|
557620
|
9061
|
|---|
|
1427
|
2016
|
DC
|
684336
|
8236
|
|---|
1428 rows × 4 columns
Добавим полные названия штатов (CSV перечня штатов здесь - уже использовали в прошлый раз). Также почистим и отсортируем данные:
df_crime_states = df_crime_states.merge(df_state_names, on='state_abbr')
df_crime_states.dropna(inplace=True)
df_crime_states.sort_values(by=['year', 'state_abbr'], inplace=True)
Поскольку в датасете есть данные о численности населения, вычислим удельные значения преступности на миллион человек:
df_crime_states['crime_promln'] = df_crime_states['violent_crime'] * 1e6 / df_crime_states['population']
Наконец, отобразим данные в виде двумерного массива за период с 2000 по 2018 год, переместив названия штатов в столбцы и убрав лишние столбцы:
df_crime_states_agg = df_crime_states.groupby(['state_name', 'year'])['violent_crime'].sum().unstack(level=1).T
df_crime_states_agg.fillna(0, inplace=True)
df_crime_states_agg = df_crime_states_agg.astype('uint32').loc[2000:2018, :]
Получили таблицу с 19 строками (по количеству наблюдений, т.е. лет с 2000 по 2018) и 51 столбцом (по количеству штатов).
Давайте отобразим топ-10 штатов по среднегодовому количеству преступлений:
df_crime_states_top10 = df_crime_states_agg.describe().T.nlargest(10, 'mean').astype('int32')
|
|
count
|
mean
|
std
|
min
|
25%
|
50%
|
75%
|
max
|
|---|
|
state_name
|
|
|
|
|
|
|
|
|
|---|
|
California
|
19
|
181514
|
19425
|
153763
|
165508
|
178597
|
193022
|
212867
|
|---|
|
Texas
|
19
|
117614
|
6522
|
104734
|
113212
|
121091
|
122084
|
126018
|
|---|
|
Florida
|
19
|
110104
|
18542
|
81980
|
92809
|
113541
|
127488
|
131878
|
|---|
|
New York
|
19
|
81618
|
9548
|
68495
|
75549
|
77563
|
85376
|
105111
|
|---|
|
Illinois
|
19
|
62866
|
10445
|
47775
|
54039
|
64185
|
69937
|
81196
|
|---|
|
Michigan
|
19
|
49273
|
5029
|
41712
|
44900
|
49737
|
54035
|
56981
|
|---|
|
Pennsylvania
|
19
|
46941
|
5066
|
39192
|
41607
|
48188
|
51021
|
55028
|
|---|
|
Tennessee
|
19
|
41951
|
2432
|
38063
|
40321
|
41562
|
43358
|
46482
|
|---|
|
Georgia
|
19
|
40228
|
3327
|
34355
|
38283
|
39435
|
41495
|
47353
|
|---|
|
North Carolina
|
19
|
37936
|
3193
|
32718
|
34706
|
38243
|
40258
|
43125
|
|---|
Давайте также посмотрим на графике для наглядности:
df_crime_states_top10 = df_crime_states_agg.loc[:, df_crime_states_agg_top10.index]
plt = df_crime_states_top10.plot.box(figsize=(12, 10))
plt.set_ylabel('Кол-во насильственных преступлений (2000 - 2018)')
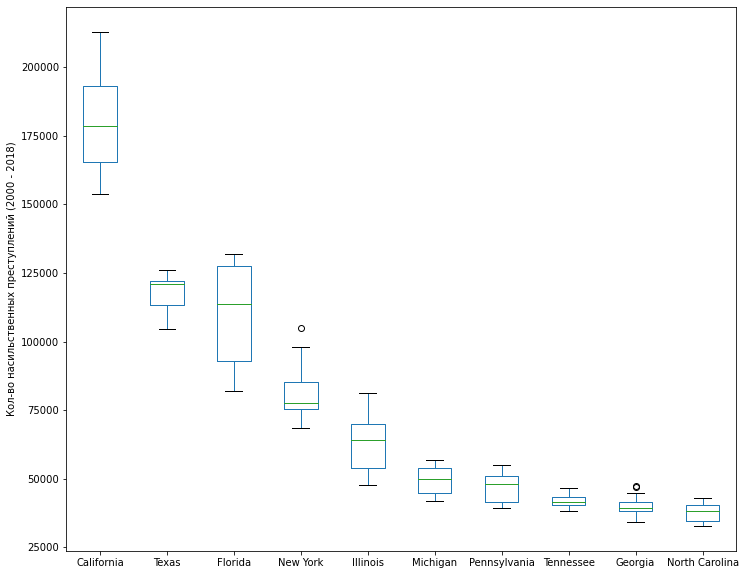
"Голливудский" штат намного опережает по этой печальной статистике все остальные. Тройка лидеров - южные штаты (Калифорния, Техас и Флорида); именно про эти штаты снято большинство американских фильмов про бандитов :)
Также видно, что в некоторых штатах уровень преступности существенно изменился за наблюдаемый период (Калифорния, Флорида, Иллинойс), в то время как в других он остался почти на том же уровне (например, в Джорджии).
Подозреваю, что преступность непосредственно связана с численностью населения. Давайте посмотрим на топ-10 штатов по населению в 2018 году:
df_crime_states_2018 = df_crime_states.loc[df_crime_states['year'] == 2018]
plt = df_crime_states_2018.nlargest(10, 'population').sort_values(by='population').plot.barh(x='state_name', y='population', legend=False, figsize=(10,5))
plt.set_xlabel('Население (2018)')
plt.set_ylabel('')

Как говорится, те же фаберже, только в профиль. Удостоверимся в корреляции между преступностью и населением:
# группируем данные по штатам за 2000 - 2018 гг (среднее арифметическое по полям)
df_corr = df_crime_states[df_crime_states['year']>=2000].groupby(['state_name']).mean()
# смотрим корреляцию между столбцами "население" и "кол-во преступлений"
df_corr = df_corr.loc[:, ['population', 'violent_crime']]
df_corr.corr(method='pearson').at['population', 'violent_crime']
- получаем коэффициент корреляции 0.98. Что и требовалось доказать!
А вот удельные показатели преступности дают совсем другой топ-лист:
plt = df_crime_states_2018.nlargest(10, 'crime_promln').sort_values(by='crime_promln').plot.barh(x='state_name', y='crime_promln', legend=False, figsize=(10,5))
plt.set_xlabel('Кол-во насильственных преступлений на 1 млн. чел. (2018)')
plt.set_ylabel('')
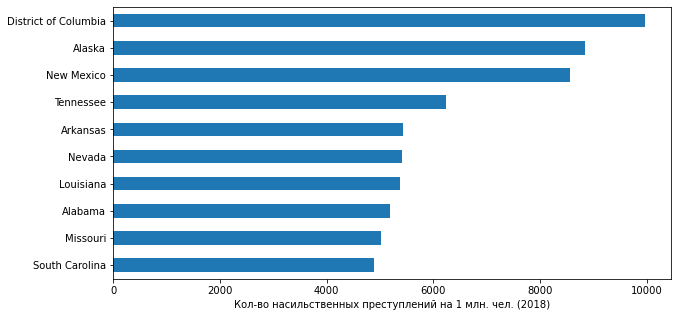
Вот так дела! По удельным значениям впереди штаты с небольшой численностью населения: Округ Колумбия (т.е. столица США) и Аляска (в обоих по 700+ тыс. человек на 2018 г.) и один штат со средней численностью (Нью-Мексико с 2 млн. чел.) Из нашего предыдущего топа здесь засветился только Теннесси, что придает этому штату, мягко говоря, не очень хорошую репутацию...
Отобразим наши наблюдения на карте США.
Для этого необходимо импортировать библиотеку folium:
import folium
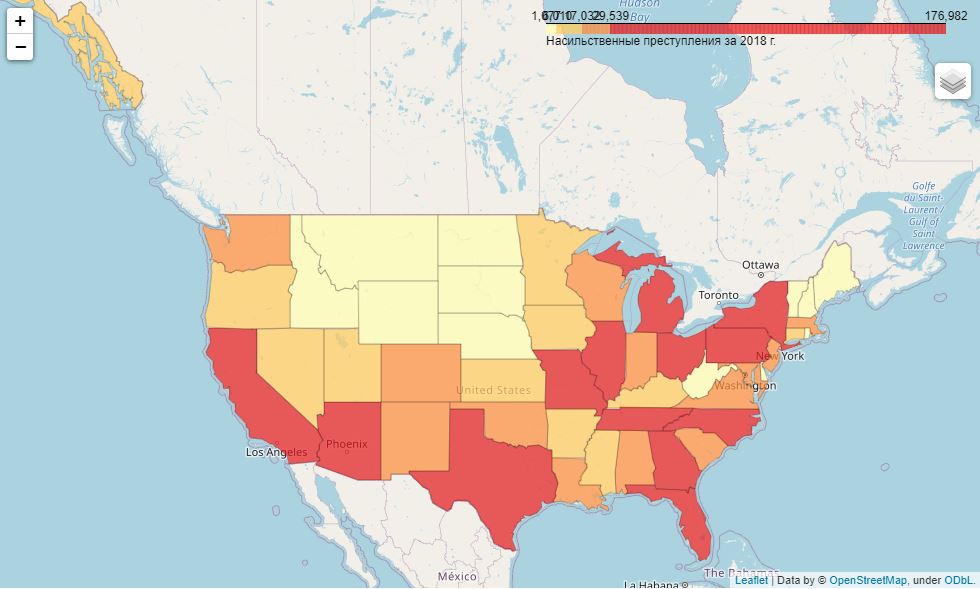
Сначала - преступления за 2018 г. в абсолютных значениях:
FOLIUM_URL = 'https://raw.githubusercontent.com/python-visualization/folium/master/examples/data'
FOLIUM_US_MAP = f'{FOLIUM_URL}/us-states.json'
m = folium.Map(location=[48, -102], zoom_start=3)
folium.Choropleth(
geo_data=FOLIUM_US_MAP,
name='choropleth',
data=df_crime_states_2018,
columns=['state_abbr', 'violent_crime'],
key_on='feature.id',
fill_color='YlOrRd',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='Насильственные преступления за 2018 г.',
bins=df_crime_states_2018['violent_crime'].quantile(list(np.linspace(0.0, 1.0, 5))).to_list(),
reset=True
).add_to(m)
folium.LayerControl().add_to(m)
m
Теперь то же в удельных значениях (на 1 млн человек):
m = folium.Map(location=[48, -102], zoom_start=3)
folium.Choropleth(
geo_data=FOLIUM_US_MAP,
name='choropleth',
data=df_crime_states_2018,
columns=['state_abbr', 'crime_promln'],
key_on='feature.id',
fill_color='YlOrRd',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='Насильственные преступления за 2018 г. (на 1 млн. населения)',
bins=df_crime_states_2018['crime_promln'].quantile(list(np.linspace(0.0, 1.0, 5))).to_list(),
reset=True
).add_to(m)
folium.LayerControl().add_to(m)
m
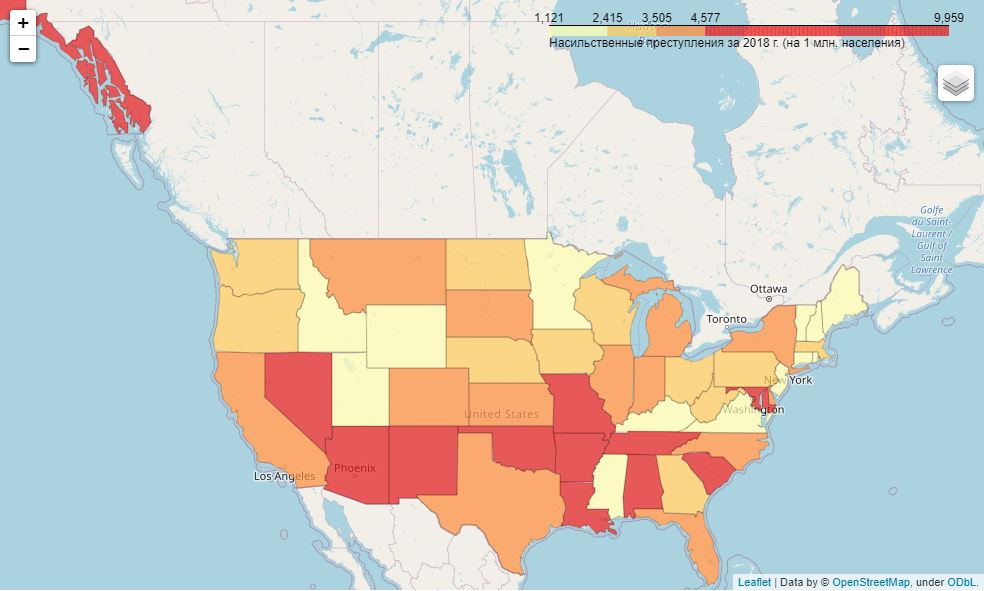
Видим, что в первом случае примерно поровну северных и южных штатов, а во втором случае - одни южные штаты плюс столица США и Аляска.
Жертвы полиции по штатам (без расовой принадлежности)
Давайте сейчас поглядим, что происходит в конкретных штатах в отношении полицейской стрельбы на уничтожение.
добавим в наш существующий датасет по гибели от рук закона (см. предыдущую часть) полные наименования штатов, сгруппируем количество случаев по штатам, выделим период с 2000 по 2018 год и отобразим удобным образом.
df_fenc_agg_states = df_fenc.merge(df_state_names, how='inner', left_on='State', right_on='state_abbr')
df_fenc_agg_states.fillna(0, inplace=True)
df_fenc_agg_states = df_fenc_agg_states.rename(columns={'state_name_x': 'State Name'})
df_fenc_agg_states = df_fenc_agg_states.loc[:, ['Year', 'Race', 'State', 'State Name', 'Cause', 'UOF']]
df_fenc_agg_states = df_fenc_agg_states.groupby(['Year', 'State Name', 'State'])['UOF'].count().unstack(level=0)
df_fenc_agg_states.fillna(0, inplace=True)
df_fenc_agg_states = df_fenc_agg_states.astype('uint16').loc[:, :2018]
df_fenc_agg_states = df_fenc_agg_states.reset_index()
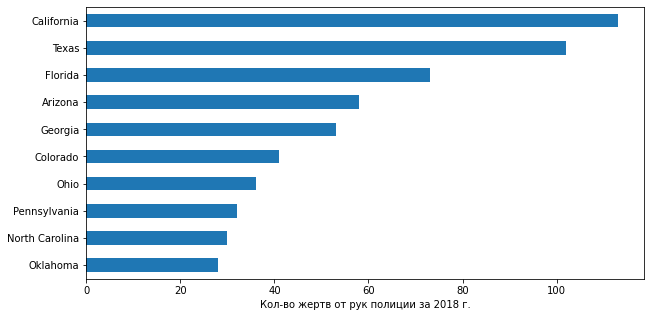
Отобразим топ-10 штатов за 2018 год:
df_fenc_agg_states_2018 = df_fenc_agg_states.loc[:, ['State Name', 2018]]
plt = df_fenc_agg_states_2018.nlargest(10, 2018).sort_values(2018).plot.barh(x='State Name', y=2018, legend=False, figsize=(10,5))
plt.set_xlabel('Кол-во жертв от рук полиции за 2018 г.')
plt.set_ylabel('')
Также посмотрим на данные за весь период в виде "ящиков с усами":
fenc_top10 = df_fenc_agg_states.loc[df_fenc_agg_states['State Name'].isin(df_fenc_agg_states_2018.nlargest(10, 2018)['State Name'])]
fenc_top10 = fenc_top10.T
fenc_top10.columns = fenc_top10.loc['State Name', :]
fenc_top10 = fenc_top10.reset_index().loc[2:, :].set_index('Year')
df_sorted = fenc_top10.mean().sort_values(ascending=False)
fenc_top10 = fenc_top10.loc[:, df_sorted.index]
plt = fenc_top10.plot.box(figsize=(12, 6))
plt.set_ylabel('Кол-во жертв от рук полиции (2000 - 2018)')

Ну что же, та же "великолепная троица": Калифорния, Техас и Флорида плюс еще два южных штата - Аризона и Джорджия. Лидеры обнаруживают, как и прежде, больший разброс по годам, демонстрируя изменения.
Связь между жертвами полиции и криминалом
Как и в предыдущей статье, будем исследовать связь между гибелью от рук полиции и криминальностью. Начнем пока без выделения расового признака, чтобы посмотреть есть ли связь в целом и как она распределяется по штатам.
Для начала необходимо объединить данные по преступлениям (насильственного характера) с данными по жертвам полиции, попутно указав диапазон с 2000 по 2018 год (этот же период анализировался в предыдущей части исследования).
# добавляем в исходный датасет полные названия штатов
df_fenc_crime_states = df_fenc.merge(df_state_names, how='inner', left_on='State', right_on='state_abbr')
# переименовываем столбцы
df_fenc_crime_states = df_fenc_crime_states.rename(columns={'Year': 'year', 'state_name_x': 'state_name'})
# обрезаем период до 2000-2018
df_fenc_crime_states = df_fenc_crime_states[df_fenc_crime_states['year'].between(2000, 2018)]
# агрегируем количество смертей по годам и штатам
df_fenc_crime_states = df_fenc_crime_states.groupby(['year', 'state_name'])['UOF'].count().reset_index()
# добавляем данные по преступлениям
df_fenc_crime_states = df_fenc_crime_states.merge(df_crime_states[df_crime_states['year'].between(2000, 2018)], how='outer', on=['year', 'state_name'])
# заполняем пробелы нулями
df_fenc_crime_states.fillna({'UOF': 0}, inplace=True)
# приводим типы данных
df_fenc_crime_states = df_fenc_crime_states.astype({'year': 'uint16', 'UOF': 'uint16', 'population': 'uint32', 'violent_crime': 'uint32'})
# сортируем
df_fenc_crime_states = df_fenc_crime_states.sort_values(by=['year', 'state_name'])
На выходе:
|
|
year
|
state_name
|
UOF
|
state_abbr
|
population
|
violent_crime
|
crime_promln
|
|---|
|
0
|
2000
|
Alabama
|
7
|
AL
|
4447100
|
21620
|
4861.595197
|
|---|
|
1
|
2000
|
Alaska
|
2
|
AK
|
626932
|
3554
|
5668.876369
|
|---|
|
2
|
2000
|
Arizona
|
11
|
AZ
|
5130632
|
27281
|
5317.278651
|
|---|
|
3
|
2000
|
Arkansas
|
4
|
AR
|
2673400
|
11904
|
4452.756789
|
|---|
|
4
|
2000
|
California
|
97
|
CA
|
33871648
|
210531
|
6215.552311
|
|---|
|
...
|
...
|
...
|
...
|
...
|
...
|
...
|
...
|
|---|
|
907
|
2018
|
Virginia
|
18
|
VA
|
8517685
|
17032
|
1999.604353
|
|---|
|
908
|
2018
|
Washington
|
24
|
WA
|
7535591
|
23472
|
3114.818732
|
|---|
|
909
|
2018
|
West Virginia
|
7
|
WV
|
1805832
|
5236
|
2899.494527
|
|---|
|
910
|
2018
|
Wisconsin
|
10
|
WI
|
5813568
|
17176
|
2954.467893
|
|---|
|
911
|
2018
|
Wyoming
|
4
|
WY
|
577737
|
1226
|
2122.072846
|
|---|
Напомню, что столбец UOF (от "Use Of Force" - применение силы) содержит количество смертей от рук служб правопорядка (которых я иногда кратко называю "полицией", хотя здесь есть и другие службы, например ФБР) в результате намеренного применения силы.
Сразу создадим и датафрейм со среднегодовыми данными:
df_fenc_crime_states_agg = df_fenc_crime_states.groupby(['state_name']).mean().loc[:, ['UOF', 'violent_crime']]
Отобразим графики преступлений и жертв полиции (среднегодовые значения для всех штатов):
plt = df_fenc_crime_states_agg['violent_crime'].plot.bar(legend=True, figsize=(15,5))
plt.set_ylabel('Среднегодовое кол-во насильственных преступлений')
plt2 = df_fenc_crime_states_agg['UOF'].plot(secondary_y=True, style='g', legend=True)
plt2.set_ylabel('Среднегодовое кол-во жертв от рук полиции', rotation=90)
plt2.set_xlabel('')
plt.set_xlabel('')
plt.set_xticklabels(df_fenc_crime_states_agg.index, rotation='vertical')
plt

Если внимательно посмотреть на эту совмещенную диаграмму, можно сделать пару наблюдений:
-
связь между преступностью и гибелью от полиции хорошо прослеживается "невооруженным глазом": зеленая кривая в большинстве случаев "повторяет" столбики преступности;
-
в штатах с высоким уровнем преступности (Флорида, Иллинойс, Мичиган, Нью-Йорк, Техас) количество жертв полиции несколько ниже (в пропорциональном отношении) по сравнению со штатами с более низким уровнем преступности.
Посмотрим на диаграмму рассеяния:
plt = df_fenc_crime_states_agg.plot.scatter(x='violent_crime', y='UOF')
plt.set_xlabel('Среднегодовое кол-во насильственных преступлений')
plt.set_ylabel('Среднегодовое кол-во жертв от рук полиции')
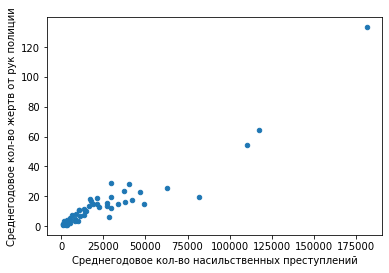
Здесь становится хорошо заметно, что соотношение между жертвами полиции и преступностью зависит от уровня преступности. Условно говоря, для штатов со среднегодовым количеством преступлений до 75 тыс. количество жертв полиции растет полее полого, чем для штатов со среднегодовым количеством преступлений свыше 75 тыс. Таких "преступных" штатов здесь, как мы видим, всего четыре.
Давайте посмотрим им "в лицо":
df_fenc_crime_states_agg[df_fenc_crime_states_agg['violent_crime'] > 75000]
|
|
UOF
|
violent_crime
|
|---|
|
state_name
|
|
|
|---|
|
California
|
133.263158
|
181514.578947
|
|---|
|
Florida
|
54.578947
|
110104.315789
|
|---|
|
New York
|
19.157895
|
81618.052632
|
|---|
|
Texas
|
64.368421
|
117614.631579
|
|---|
Ну конечно же, это уже знакомая нам четверка "всадников Апокалипсиса": Калифорния, Флорида, Техас и Нью-Йорк.
Давайте посмотрим на корреляцию между нашими данными по 3 кейсам:
- Штаты со среднегодовым количеством преступлений до 75 тыс.
- Штаты со среднегодовым количеством преступлений свыше 75 тыс. (наша "четверка")
- Все штаты
df_fenc_crime_states_agg[df_fenc_crime_states_agg['violent_crime'] <= 75000].corr(method='pearson').at['UOF', 'violent_crime']
получаем коэффициент 0.839. Это значимая величина, но до 0.9 не доходит, так как здесь налицо значительный разброс по 47 штатам.
df_fenc_crime_states_agg[df_fenc_crime_states_agg['violent_crime'] > 75000].corr(method='pearson').at['UOF', 'violent_crime']
получаем уже 0.999 - идеальную корреляцию!
Для третьего кейса (все штаты):
df_fenc_crime_states_agg.corr(method='pearson').at['UOF', 'violent_crime']
получаем нечто среднее между двумя предыдущими: 0.935. Но этот общий коэффициент указывает на весьма значительно корреляцию.
А теперь посмотрим, как распределен по штатам наш "индекс стрельбы в преступников" (это, конечно, условное название). Разделим, как и раньше, количество жертв полиции на количество преступлений:
Разделим, как и раньше, количество жертв полиции на количество преступлений:
df_fenc_crime_states_agg['uof_by_crime'] = df_fenc_crime_states_agg['UOF'] / df_fenc_crime_states_agg['violent_crime']
plt = df_fenc_crime_states_agg.loc[:, 'uof_by_crime'].sort_values(ascending=False).plot.bar(figsize=(15,5))
plt.set_xlabel('')
plt.set_ylabel('Отношение кол-ва жертв полиции к кол-ву преступлений')
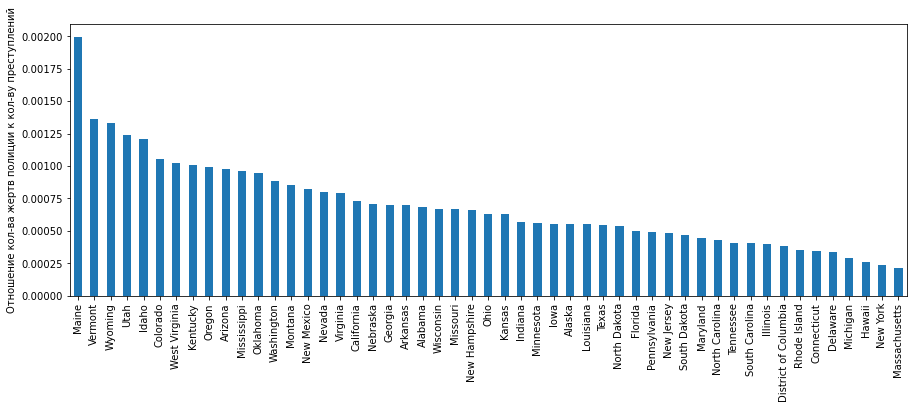
Здесь интересно заметить, что наши лидеры по преступности ушли в середину и даже ближе концу, показывая тем самым, что в самых преступных штатах не самые "кровавые" полицейские (по отношению к потенциальным или реальным преступникам).
Промежуточные выводы:
1. Количество насильственных преступлений прямо зависит от количества населения (спасибо, кэп!)
2. В абсолютном выражении лидеры по преступности - самые населенные штаты: Калифорния, Флорида, Техас и Нью-Йорк.
2. В удельном отношении (на миллион населения) преступности больше в южных штатах, чем в северных, где заметны только два низко населенных штата - Аляска и Округ Колумбия (г. Вашингтон).
3. Между преступностью и гибелью от рук полиции подтверждается заметная корреляция, составляющая в среднем 0.93 по всем штатам. При этом для лидеров по преступности эта корреляция достигает почти единицы (т.е. линейная пропорция), в то время как для остальных штатов - 0.84.
Влияние расы на преступность и гибель от полиции по штатам
Убедившись, что преступность в целом влияет на гибель от рук полиции, давайте добавим теперь расовый фактор и посмотрим, на что он влияет. Как я уже объяснил выше, для этой цели будем использовать данные по арестам, поскольку они являются наиболее полными из доступных, покрывая основные виды преступлений и все штаты США. Естественно, ни в одном штате и ни в одной стране нельзя приравнять количество арестов к количеству преступлений, но эти показатели, тем не менее, тесно взаимосвязаны. Поэтому для статистических изысканий аресты нам годятся. И мы уже договорились, что будем рассматривать аресты только за насильственные преступления (убийство, грабеж, изнасилование и нападение с отягчающими обстоятельствами), в соответствии с принятой концепцией анализа.
Загружаем данные из CSV и привычно добавляем названия штатов:
ARRESTS_FILE = ROOT_FOLDER + '\\arrests_by_state_race.csv'
# берем только аресты белых и черных
df_arrests = pd.read_csv(ARRESTS_FILE, sep=';', header=0, usecols=['data_year', 'state', 'white', 'black'])
# суммируем аресты за 4 вида преступлений по годам и штатам
df_arrests = df_arrests.groupby(['data_year', 'state']).sum().reset_index()
# добавляем наименования штатов
df_arrests = df_arrests.merge(df_state_names, left_on='state', right_on='state_abbr')
# переименовываем и удаляем столбцы
df_arrests = df_arrests.rename(columns={'data_year': 'year'}).drop(columns='state_abbr')
# поглядим, что получилось
df_arrests.head()
|
|
year
|
state
|
black
|
white
|
state_name
|
|---|
|
0
|
2000
|
AK
|
140
|
613
|
Alaska
|
|---|
|
1
|
2001
|
AK
|
139
|
718
|
Alaska
|
|---|
|
2
|
2002
|
AK
|
143
|
677
|
Alaska
|
|---|
|
3
|
2003
|
AK
|
173
|
801
|
Alaska
|
|---|
|
4
|
2004
|
AK
|
163
|
765
|
Alaska
|
|---|
Сразу создадим данные со среднегодовыми показателями:
df_arrests_agg = df_arrests.groupby(['state_name']).mean().drop(columns='year')
Аресты белых и черных по 51 штату (среднегодовые значения)
|
|
black
|
white
|
|---|
|
state_name
|
|
|
|---|
|
Alabama
|
2805.842105
|
1757.315789
|
|---|
|
Alaska
|
221.894737
|
844.157895
|
|---|
|
Arizona
|
1378.368421
|
7007.157895
|
|---|
|
Arkansas
|
2387.894737
|
2303.789474
|
|---|
|
California
|
26668.368421
|
87252.315789
|
|---|
|
Colorado
|
1268.210526
|
5157.368421
|
|---|
|
Connecticut
|
2097.631579
|
2981.210526
|
|---|
|
Delaware
|
1356.894737
|
1048.578947
|
|---|
|
District of Columbia
|
111.111111
|
4.944444
|
|---|
|
Florida
|
12.000000
|
7.000000
|
|---|
|
Georgia
|
8262.842105
|
3502.894737
|
|---|
|
Hawaii
|
81.052632
|
368.736842
|
|---|
|
Idaho
|
44.000000
|
1362.263158
|
|---|
|
Illinois
|
5699.842105
|
1841.894737
|
|---|
|
Indiana
|
3553.368421
|
5192.263158
|
|---|
|
Iowa
|
1104.421053
|
3039.473684
|
|---|
|
Kansas
|
522.315789
|
1501.315789
|
|---|
|
Kentucky
|
1476.894737
|
1906.052632
|
|---|
|
Louisiana
|
5928.789474
|
3414.263158
|
|---|
|
Maine
|
63.736842
|
699.526316
|
|---|
|
Maryland
|
7189.105263
|
4010.684211
|
|---|
|
Massachusetts
|
3407.157895
|
7319.684211
|
|---|
|
Michigan
|
7628.157895
|
6304.157895
|
|---|
|
Minnesota
|
2231.210526
|
2645.736842
|
|---|
|
Mississippi
|
1462.210526
|
474.368421
|
|---|
|
Missouri
|
5777.473684
|
5703.368421
|
|---|
|
Montana
|
27.684211
|
673.684211
|
|---|
|
Nebraska
|
591.421053
|
1058.526316
|
|---|
|
Nevada
|
1956.421053
|
3817.210526
|
|---|
|
New Hampshire
|
68.368421
|
640.789474
|
|---|
|
New Jersey
|
6424.157895
|
6043.789474
|
|---|
|
New Mexico
|
234.421053
|
2809.368421
|
|---|
|
New York
|
8394.526316
|
8734.947368
|
|---|
|
North Carolina
|
10527.947368
|
7412.947368
|
|---|
|
North Dakota
|
61.263158
|
277.052632
|
|---|
|
Ohio
|
4063.947368
|
4071.368421
|
|---|
|
Oklahoma
|
1625.105263
|
3353.000000
|
|---|
|
Oregon
|
445.105263
|
3373.368421
|
|---|
|
Pennsylvania
|
11974.157895
|
11039.473684
|
|---|
|
Rhode Island
|
275.684211
|
699.210526
|
|---|
|
South Carolina
|
5578.526316
|
3615.421053
|
|---|
|
South Dakota
|
67.105263
|
349.368421
|
|---|
|
Tennessee
|
6799.894737
|
8462.526316
|
|---|
|
Texas
|
10547.631579
|
22062.684211
|
|---|
|
Utah
|
167.105263
|
1748.894737
|
|---|
|
Vermont
|
43.526316
|
439.210526
|
|---|
|
Virginia
|
4100.421053
|
3060.263158
|
|---|
|
Washington
|
1688.947368
|
6012.105263
|
|---|
|
West Virginia
|
271.263158
|
1528.315789
|
|---|
|
Wisconsin
|
3440.055556
|
4107.722222
|
|---|
|
Wyoming
|
27.263158
|
506.947368
|
|---|
При рассмотрении этих данных нельзя не заметить некоторые странности. В одних штатах аресты исчисляются тысячами и сотнями, в других - десятками и единицами. Так, например, по Флориде - одному из самых густо населенных штатов - отображается только 19 арестов в год (12 черных и 7 белых). Здесь явно не хватает каких-то точек наблюдений; проверим это:
df_arrests[df_arrests['state'] == 'FL']
И видим, что, действительно, по Флориде доступны данные только за 2017 год. Что ж, придется использовать то, что имеем... По остальным штатам все данные есть. Но разница на 1-2 порядка может также объясняться различной населенностью. Давайте подгрузим данные по населению (для обеих рас) и посмотрим.
Данные по численности я взял с сайта Бюро переписи населения США. В России сайт почему-то не работает, но вы же знаете, как заставить его заработать ;) Здесь подготовленный CSV с данными переписи с 2010 по 2019 г.
К сожалению, сведений по населению по штатам за более ранние периоды (с 2000 по 2009 г.) нет. Таким образом, для этой части исследования придется сузить диапазон наблюдений до 9 лет (с 2010 по 2018 г.).
POP_STATES_FILES = ROOT_FOLDER + '\\us_pop_states_race_2010-2019.csv'
df_pop_states = pd.read_csv(POP_STATES_FILES, sep=';', header=0)
# данные имеют специфический формат, придется поколдовать ))
df_pop_states = df_pop_states.melt('state_name', var_name='r_year', value_name='pop')
df_pop_states['race'] = df_pop_states['r_year'].str[0]
df_pop_states['year'] = df_pop_states['r_year'].str[2:].astype('uint16')
df_pop_states.drop(columns='r_year', inplace=True)
df_pop_states = df_pop_states[df_pop_states['year'].between(2000, 2018)]
df_pop_states = df_pop_states.groupby(['state_name', 'year', 'race']).sum().unstack().reset_index()
df_pop_states.columns = ['state_name', 'year', 'black_pop', 'white_pop']
Данные по численности белых и черных по штатам
|
|
state_name
|
year
|
black_pop
|
white_pop
|
|---|
|
0
|
Alabama
|
2010
|
5044936
|
13462236
|
|---|
|
1
|
Alabama
|
2011
|
5067912
|
13477008
|
|---|
|
2
|
Alabama
|
2012
|
5102512
|
13484256
|
|---|
|
3
|
Alabama
|
2013
|
5137360
|
13488812
|
|---|
|
4
|
Alabama
|
2014
|
5162316
|
13493432
|
|---|
|
...
|
...
|
...
|
...
|
...
|
|---|
|
454
|
Wyoming
|
2014
|
31392
|
2167008
|
|---|
|
455
|
Wyoming
|
2015
|
29568
|
2177740
|
|---|
|
456
|
Wyoming
|
2016
|
29304
|
2170700
|
|---|
|
457
|
Wyoming
|
2017
|
29444
|
2148128
|
|---|
|
458
|
Wyoming
|
2018
|
29604
|
2139896
|
|---|
Добавляем этот датасет к арестам и вычисляем удельные показатели по арестам на 1 млн представителей каждой расы:
arrests.merge(df_pop_states, how='inner', on=['year', 'state_name'])
df_arrests_2010_2018['white_arrests_promln'] = df_arrests_2010_2018['white'] * 1e6 / df_arrests_2010_2018['white_pop']
df_arrests_2010_2018['black_arrests_promln'] = df_arrests_2010_2018['black'] * 1e6 / df_arrests_2010_2018['black_pop']
И так же создаем датасет со среднегодовыми показателями:
df_arrests_2010_2018_agg = df_arrests_2010_2018.groupby(['state_name', 'state']).mean().drop(columns='year').reset_index()
df_arrests_2010_2018_agg = df_arrests_2010_2018_agg.set_index('state_name')
Объединенный датасет по арестам и численности (среднегодовые значения)
|
|
state
|
black
|
white
|
black_pop
|
white_pop
|
white_arrests_promln
|
black_arrests_promln
|
|---|
|
state_name
|
|
|
|
|
|
|
|
|---|
|
Alabama
|
AL
|
1682.000000
|
1342.000000
|
5.152399e+06
|
1.349158e+07
|
99.424741
|
324.055203
|
|---|
|
Alaska
|
AK
|
255.000000
|
870.555556
|
1.069489e+05
|
1.957445e+06
|
445.199704
|
2390.243876
|
|---|
|
Arizona
|
AZ
|
1635.555556
|
6852.000000
|
1.279172e+06
|
2.260403e+07
|
302.923002
|
1267.000192
|
|---|
|
Arkansas
|
AR
|
1960.666667
|
2466.000000
|
1.855574e+06
|
9.465137e+06
|
260.459917
|
1055.854934
|
|---|
|
California
|
CA
|
24381.666667
|
79477.000000
|
1.007921e+07
|
1.128020e+08
|
704.731408
|
2419.234376
|
|---|
|
Colorado
|
CO
|
1377.222222
|
5171.555556
|
9.508173e+05
|
1.882940e+07
|
274.209456
|
1439.257054
|
|---|
|
Connecticut
|
CT
|
1823.777778
|
2295.333333
|
1.643690e+06
|
1.165681e+07
|
196.712775
|
1114.811569
|
|---|
|
Delaware
|
DE
|
1318.000000
|
914.111111
|
8.354622e+05
|
2.635794e+06
|
347.374980
|
1582.395733
|
|---|
|
District of Columbia
|
DC
|
139.222222
|
4.777778
|
1.288488e+06
|
1.154416e+06
|
4.112547
|
108.101938
|
|---|
|
Florida
|
FL
|
12.000000
|
7.000000
|
1.415383e+07
|
6.498292e+07
|
0.107721
|
0.847827
|
|---|
|
Georgia
|
GA
|
8137.222222
|
4271.444444
|
1.279378e+07
|
2.500293e+07
|
170.939250
|
639.869143
|
|---|
|
Hawaii
|
HI
|
81.333333
|
383.777778
|
1.124298e+05
|
1.453712e+06
|
264.353469
|
725.477589
|
|---|
|
Idaho
|
ID
|
51.888889
|
1373.777778
|
5.288222e+04
|
6.154316e+06
|
223.151878
|
978.205026
|
|---|
|
Illinois
|
IL
|
4216.000000
|
1284.222222
|
7.554687e+06
|
3.980927e+07
|
32.199075
|
557.493894
|
|---|
|
Indiana
|
IN
|
2924.444444
|
5186.111111
|
2.522917e+06
|
2.267508e+07
|
228.699515
|
1155.168768
|
|---|
|
Iowa
|
IA
|
1181.000000
|
2999.222222
|
4.305640e+05
|
1.141794e+07
|
262.666753
|
2760.038539
|
|---|
|
Kansas
|
KS
|
539.555556
|
1512.111111
|
7.116182e+05
|
1.006714e+07
|
150.232160
|
758.851182
|
|---|
|
Kentucky
|
KY
|
1443.888889
|
2173.666667
|
1.442174e+06
|
1.558094e+07
|
139.526970
|
1001.433470
|
|---|
|
Louisiana
|
LA
|
5917.000000
|
3255.333333
|
6.021228e+06
|
1.174245e+07
|
277.277874
|
981.334817
|
|---|
|
Maine
|
ME
|
78.000000
|
678.000000
|
7.667733e+04
|
5.059062e+06
|
134.024032
|
1019.061684
|
|---|
|
Maryland
|
MD
|
6460.444444
|
3325.444444
|
7.229037e+06
|
1.426036e+07
|
233.317775
|
893.942720
|
|---|
|
Massachusetts
|
MA
|
3349.555556
|
6895.111111
|
2.249232e+06
|
2.226671e+07
|
309.745910
|
1505.096888
|
|---|
|
Michigan
|
MI
|
6302.444444
|
5647.444444
|
5.645176e+06
|
3.170670e+07
|
178.111684
|
1116.364030
|
|---|
|
Minnesota
|
MN
|
2570.000000
|
2686.777778
|
1.311818e+06
|
1.867259e+07
|
143.902882
|
1986.464052
|
|---|
|
Mississippi
|
MS
|
1251.000000
|
418.777778
|
4.478208e+06
|
7.122651e+06
|
58.753686
|
279.574565
|
|---|
|
Missouri
|
MO
|
4588.333333
|
5146.111111
|
2.854060e+06
|
2.023871e+07
|
254.292323
|
1608.303611
|
|---|
|
Montana
|
MT
|
34.222222
|
788.333333
|
2.210444e+04
|
3.660813e+06
|
214.944902
|
1525.795754
|
|---|
|
Nebraska
|
NE
|
618.888889
|
1154.888889
|
3.701520e+05
|
6.709768e+06
|
172.269972
|
1687.725359
|
|---|
|
Nevada
|
NV
|
2450.000000
|
4480.333333
|
1.052192e+06
|
8.647157e+06
|
517.401564
|
2316.374085
|
|---|
|
New Hampshire
|
NH
|
89.777778
|
784.777778
|
7.873600e+04
|
5.012056e+06
|
156.580888
|
1141.127571
|
|---|
|
New Jersey
|
NJ
|
5429.555556
|
4971.888889
|
5.241910e+06
|
2.595141e+07
|
191.427955
|
1037.217679
|
|---|
|
New Mexico
|
NM
|
260.111111
|
3136.000000
|
2.053876e+05
|
6.905377e+06
|
454.129135
|
1268.115549
|
|---|
|
New York
|
NY
|
6035.777778
|
6600.222222
|
1.373077e+07
|
5.534157e+07
|
119.253616
|
439.581451
|
|---|
|
North Carolina
|
NC
|
9549.000000
|
6759.333333
|
8.804027e+06
|
2.844145e+07
|
238.320077
|
1088.968561
|
|---|
|
North Dakota
|
ND
|
100.666667
|
386.222222
|
6.583289e+04
|
2.583206e+06
|
149.190455
|
1536.987272
|
|---|
|
Ohio
|
OH
|
3632.888889
|
3733.333333
|
5.879375e+06
|
3.844592e+07
|
97.107129
|
617.699379
|
|---|
|
Oklahoma
|
OK
|
1577.333333
|
3049.000000
|
1.189604e+06
|
1.160567e+07
|
262.904593
|
1326.463864
|
|---|
|
Oregon
|
OR
|
375.444444
|
3125.000000
|
3.292284e+05
|
1.402225e+07
|
222.819615
|
1148.158169
|
|---|
|
Pennsylvania
|
PA
|
11227.000000
|
10652.111111
|
5.945100e+06
|
4.232445e+07
|
251.598838
|
1893.415475
|
|---|
|
Rhode Island
|
RI
|
274.888889
|
595.000000
|
3.275551e+05
|
3.592825e+06
|
165.605635
|
837.932682
|
|---|
|
South Carolina
|
SC
|
4703.222222
|
3094.111111
|
5.365012e+06
|
1.324712e+07
|
234.287821
|
877.892998
|
|---|
|
South Dakota
|
SD
|
103.777778
|
448.333333
|
6.154533e+04
|
2.903489e+06
|
153.995184
|
1641.137012
|
|---|
|
Tennessee
|
TN
|
7603.000000
|
9068.666667
|
4.460808e+06
|
2.070126e+07
|
438.486812
|
1708.022356
|
|---|
|
Texas
|
TX
|
10821.666667
|
21122.111111
|
1.345661e+07
|
8.628389e+07
|
245.051258
|
803.917061
|
|---|
|
Utah
|
UT
|
193.222222
|
1797.333333
|
1.558876e+05
|
1.079659e+07
|
166.431266
|
1240.117890
|
|---|
|
Vermont
|
VT
|
54.222222
|
520.555556
|
3.017111e+04
|
2.376143e+06
|
219.129918
|
1785.111547
|
|---|
|
Virginia
|
VA
|
4059.555556
|
3071.222222
|
6.544598e+06
|
2.340732e+07
|
131.178648
|
620.504151
|
|---|
|
Washington
|
WA
|
1791.777778
|
5870.444444
|
1.147000e+06
|
2.289368e+07
|
256.632241
|
1566.862244
|
|---|
|
West Virginia
|
WV
|
294.111111
|
1648.666667
|
2.597649e+05
|
6.908718e+06
|
238.517207
|
1132.059057
|
|---|
|
Wisconsin
|
WI
|
3525.333333
|
4046.222222
|
1.516534e+06
|
2.018658e+07
|
200.441064
|
2325.622492
|
|---|
|
Wyoming
|
WY
|
28.777778
|
464.555556
|
2.856356e+04
|
2.151349e+06
|
216.004646
|
|
|---|
Отобразим в виде диаграмм:
1.Количество арестов в абсолютных значениях
plt = df_arrests_2010_2018_agg.loc[:, ['white', 'black']].sort_index(ascending=False).plot.barh(color=['g', 'olive'], figsize=(10, 20))
plt.set_ylabel('')
plt.set_xlabel('Среднегодовое кол-во арестов (2010-2018 гг.)')
2. Теперь в удельных значениях:
plt = df_arrests_2010_2018_agg.loc[:, ['white_arrests_promln', 'black_arrests_promln']].sort_index(ascending=False).plot.barh(color=['g', 'olive'], figsize=(10, 20))
plt.set_ylabel('')
plt.set_xlabel('Среднегодовое кол-во арестов на 1 млн представителей расы (2010-2018 гг.)')
ЕЩЕ ОДНА ДЛИННАЯ КАРТИНКА
Что можно сказать при взгляде на эти данные?
Во-первых, конечно, количество арестов зависит от количество населения - это заметно по данным для обеих рас.
Во-вторых, в абсолютных показателях белых арестовывают несколько чаще. Говорю "несколько", потому как видно, что эта закономерность соблюдается не во всех штатах (см. например, Северная Каролина, Джорджия, Луизиана и др.) А во-вторых, разница в большинстве штатов не слишком заметна (за исключением, пожалуй, Калифорнии, Техаса, Колорадо, Массачусетса и нескольких других штатов.
В-третьих, в удельных показателях (на миллион представителей расы) во всех штатах черных арестовывают гораздо больше, чем белых.
Давайте проверим наши выводы цифрами.
Разница между средним количеством арестов белых и черных:
df_arrests_2010_2018['white'].mean() / df_arrests_2010_2018['black'].mean()
- получаем 1.56. Т.е. белых за наблюдаемые 9 лет арестовывали в среднем в полтора раза больше, чем черных.
Теперь то же в удельных показателях:
df_arrests_2010_2018['white_arrests_promln'].mean() / df_arrests_2010_2018['black_arrests_promln'].mean()
- получаем 0.183. Т.е. вероятность ареста черных в 5.5 раз выше, чем белых.
Таким образом, гипотеза о большей преступности среди черных еще раз подтверждается на примере арестов по всем штатам США.
Чтобы понять, как раса и преступность связаны с гибелью от рук стражей закона, объединим данные по арестам с данными по жертвам полиции.
Подготовим данные по жертвам с расовым признаком с разбивкой по штатам:
df_fenc_agg_states1 = df_fenc.merge(df_state_names, how='inner', left_on='State', right_on='state_abbr')
df_fenc_agg_states1.fillna(0, inplace=True)
df_fenc_agg_states1 = df_fenc_agg_states1.rename(columns={'state_name_x': 'state_name', 'Year': 'year'})
df_fenc_agg_states1 = df_fenc_agg_states1.loc[df_fenc_agg_states1['year'].between(2000, 2018), ['year', 'Race', 'state_name', 'UOF']]
df_fenc_agg_states1 = df_fenc_agg_states1.groupby(['year', 'state_name', 'Race'])['UOF'].count().unstack().reset_index()
df_fenc_agg_states1 = df_fenc_agg_states1.rename(columns={'Black': 'black_uof', 'White': 'white_uof'})
df_fenc_agg_states1 = df_fenc_agg_states1.fillna(0).astype({'black_uof': 'uint32', 'white_uof': 'uint32'})
Полученный датасет
|
|
year
|
state_name
|
black_uof
|
white_uof
|
|---|
|
0
|
2000
|
Alabama
|
4
|
3
|
|---|
|
1
|
2000
|
Alaska
|
0
|
2
|
|---|
|
2
|
2000
|
Arizona
|
0
|
11
|
|---|
|
3
|
2000
|
Arkansas
|
1
|
3
|
|---|
|
4
|
2000
|
California
|
19
|
78
|
|---|
|
...
|
...
|
...
|
...
|
...
|
|---|
|
907
|
2018
|
Virginia
|
11
|
7
|
|---|
|
908
|
2018
|
Washington
|
0
|
24
|
|---|
|
909
|
2018
|
West Virginia
|
2
|
5
|
|---|
|
910
|
2018
|
Wisconsin
|
3
|
7
|
|---|
|
911
|
2018
|
Wyoming
|
0
|
4
|
|---|
Производим объединение:
df_arrests_fenc = df_arrests.merge(df_fenc_agg_states1, on=['state_name', 'year'])
df_arrests_fenc = df_arrests_fenc.rename(columns={'white': 'white_arrests', 'black': 'black_arrests'})
Пример данных за 2017 год
|
|
year
|
state
|
black_arrests
|
white_arrests
|
state_name
|
black_uof
|
white_uof
|
|---|
|
15
|
2017
|
AK
|
266
|
859
|
Alaska
|
2
|
3
|
|---|
|
34
|
2017
|
AL
|
3098
|
2509
|
Alabama
|
7
|
17
|
|---|
|
53
|
2017
|
AR
|
2092
|
2674
|
Arkansas
|
6
|
7
|
|---|
|
72
|
2017
|
AZ
|
2431
|
7829
|
Arizona
|
6
|
43
|
|---|
|
91
|
2017
|
CA
|
24937
|
80367
|
California
|
25
|
137
|
|---|
|
110
|
2017
|
CO
|
1781
|
6079
|
Colorado
|
2
|
27
|
|---|
|
127
|
2017
|
CT
|
1687
|
2114
|
Connecticut
|
1
|
5
|
|---|
|
140
|
2017
|
DE
|
1198
|
782
|
Delaware
|
4
|
3
|
|---|
|
159
|
2017
|
GA
|
7747
|
4171
|
Georgia
|
15
|
21
|
|---|
|
173
|
2017
|
HI
|
88
|
419
|
Hawaii
|
0
|
1
|
|---|
|
192
|
2017
|
IA
|
1400
|
3524
|
Iowa
|
1
|
5
|
|---|
|
210
|
2017
|
ID
|
61
|
1423
|
Idaho
|
0
|
6
|
|---|
|
229
|
2017
|
IL
|
2847
|
947
|
Illinois
|
13
|
11
|
|---|
|
248
|
2017
|
IN
|
3565
|
4300
|
Indiana
|
9
|
13
|
|---|
|
267
|
2017
|
KS
|
585
|
1651
|
Kansas
|
3
|
10
|
|---|
|
286
|
2017
|
KY
|
1481
|
2035
|
Kentucky
|
1
|
18
|
|---|
|
305
|
2017
|
LA
|
5875
|
2284
|
Louisiana
|
13
|
5
|
|---|
|
324
|
2017
|
MA
|
2953
|
6089
|
Massachusetts
|
1
|
4
|
|---|
|
343
|
2017
|
MD
|
6662
|
3371
|
Maryland
|
8
|
5
|
|---|
|
361
|
2017
|
ME
|
89
|
675
|
Maine
|
1
|
8
|
|---|
|
380
|
2017
|
MI
|
6149
|
5459
|
Michigan
|
6
|
7
|
|---|
|
399
|
2017
|
MN
|
2513
|
2681
|
Minnesota
|
1
|
7
|
|---|
|
418
|
2017
|
MO
|
4571
|
5007
|
Missouri
|
13
|
20
|
|---|
|
437
|
2017
|
MS
|
1266
|
409
|
Mississippi
|
7
|
10
|
|---|
|
455
|
2017
|
MT
|
50
|
915
|
Montana
|
0
|
3
|
|---|
|
474
|
2017
|
NC
|
8177
|
5576
|
North Carolina
|
9
|
14
|
|---|
|
501
|
2017
|
NE
|
80
|
578
|
Nebraska
|
0
|
1
|
|---|
|
516
|
2017
|
NH
|
113
|
817
|
New Hampshire
|
0
|
3
|
|---|
|
535
|
2017
|
NJ
|
4859
|
4136
|
New Jersey
|
9
|
6
|
|---|
|
554
|
2017
|
NM
|
205
|
2094
|
New Mexico
|
0
|
20
|
|---|
|
573
|
2017
|
NV
|
2695
|
4657
|
Nevada
|
3
|
12
|
|---|
|
592
|
2017
|
NY
|
5923
|
6633
|
New York
|
7
|
9
|
|---|
|
611
|
2017
|
OH
|
4472
|
3882
|
Ohio
|
11
|
23
|
|---|
|
630
|
2017
|
OK
|
1638
|
2872
|
Oklahoma
|
3
|
20
|
|---|
|
649
|
2017
|
OR
|
453
|
3222
|
Oregon
|
2
|
9
|
|---|
|
668
|
2017
|
PA
|
10123
|
10191
|
Pennsylvania
|
7
|
17
|
|---|
|
681
|
2017
|
RI
|
315
|
633
|
Rhode Island
|
0
|
1
|
|---|
|
700
|
2017
|
SC
|
4645
|
2964
|
South Carolina
|
3
|
10
|
|---|
|
712
|
2017
|
SD
|
124
|
537
|
South Dakota
|
0
|
2
|
|---|
|
731
|
2017
|
TN
|
6654
|
8496
|
Tennessee
|
4
|
24
|
|---|
|
750
|
2017
|
TX
|
11493
|
20911
|
Texas
|
18
|
56
|
|---|
|
769
|
2017
|
UT
|
199
|
1964
|
Utah
|
1
|
5
|
|---|
|
788
|
2017
|
VA
|
4283
|
3247
|
Virginia
|
8
|
17
|
|---|
|
804
|
2017
|
VT
|
75
|
626
|
Vermont
|
0
|
1
|
|---|
|
823
|
2017
|
WA
|
1890
|
5804
|
Washington
|
8
|
27
|
|---|
|
842
|
2017
|
WV
|
350
|
1705
|
West Virginia
|
1
|
10
|
|---|
|
856
|
2017
|
WY
|
36
|
549
|
Wyoming
|
0
|
1
|
|---|
|
872
|
2017
|
DC
|
135
|
8
|
District of Columbia
|
1
|
1
|
|---|
|
890
|
2017
|
WI
|
3604
|
4106
|
Wisconsin
|
6
|
15
|
|---|
|
892
|
2017
|
FL
|
12
|
7
|
Florida
|
19
|
43
|
|---|
ОК, теперь можно вычислить корреляцию между арестами и жертвами полиции, как мы уже делали раньше:
df_corr = df_arrests_fenc.loc[:, ['white_arrests', 'black_arrests', 'white_uof', 'black_uof']].corr(method='pearson').iloc[:2, 2:]
df_corr.style.background_gradient(cmap='PuBu')
|
|
white_uof
|
black_uof
|
|---|
|
white_arrests
|
0.872766
|
0.622167
|
|---|
|
black_arrests
|
0.702350
|
0.766852
|
|---|
Получаем вновь неплохую корреляцию: 0.87 для белых и 0.77 для черных! Здесь интересно отметить, что эти значения очень близки к коэффициентам корреляции, полученным нами на примере данных по преступлениям в предыдущей части статьи (там было 0.88 для белых и 0.72 для черных).
Наконец, давайте посмотрим на наш "индекс стрельбы в преступников", разделив количество жертв полиции на количество арестов по каждой расе.
df_arrests_fenc['white_uof_by_arr'] = df_arrests_fenc['white_uof'] / df_arrests_fenc['white_arrests']
df_arrests_fenc['black_uof_by_arr'] = df_arrests_fenc['black_uof'] / df_arrests_fenc['black_arrests']
df_arrests_fenc.replace([np.inf, -np.inf], np.nan, inplace=True)
df_arrests_fenc.fillna({'white_uof_by_arr': 0, 'black_uof_by_arr': 0}, inplace=True)
Посмотрим на графике, как распределяется этот показатель по штатам (возьмем 2018 год):
plt = df_arrests_fenc.loc[df_arrests_fenc['year'] == 2018, ['state_name', 'white_uof_by_arr', 'black_uof_by_arr']].sort_values(by='state_name', ascending=False).plot.barh(x='state_name', color=['g', 'olive'], figsize=(10, 20))
plt.set_ylabel('')
plt.set_xlabel('Отношение кол-ва жертв к кол-ву арестов (за 2018 г.)')
Видно, что в большинстве штатов показатель для белых превышает показатель для черных, хотя есть и яркие исключения: Юта, Западная Вирджиния, Канзас, Айдахо и Округ Колумбия.
Но сравним средние показатели по всем штатам:
plt = df_arrests_fenc.loc[:, ['white_uof_by_arr', 'black_uof_by_arr']].mean().plot.bar(color=['g', 'olive'])
plt.set_ylabel('Отношение кол-ва жертв к кол-ву арестов')
plt.set_xticklabels(['Белые', 'Черные'], rotation=0)
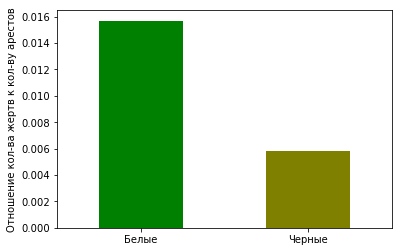
Показатель для белых выше в 2.5 раза. То есть, если этот индекс о чем-то говорит, то белый преступник имеет в среднем в 2.5 раза большую вероятность встретить смерть от рук полиции, чем черный преступник. Конечно, этот показатель сильно варьируется по штатам: например, в Айдахо черный преступник погибает в 2 раза чаще белого, а в Миссисипи - в 4 раза реже.
Что же, это исследование подошло к концу. Пора резюмировать.
Выводы
- Преступность в штатах прямо зависит от численности населения. Наиболее "преступные" штаты, о которых мы привыкли смотреть криминальные хроники или художественные фильмы, - просто самые густо населенные. При рассмотрении удельных показателей насильственных преступлений (на душу населения) лидерами оказываются совершенно неожиданные штаты - Аляска, Округ Колумбия (со столицей США) и Нью-Мексико.
- В целом южные штаты показывают более высокие показатели преступности (в удельном выражении), чем северные штаты.
- В США количество совершаемых преступлений и арестов обнаруживает значительную разницу среди белых и среди черных в удельном выражении: черные совершаю в 3 раза больше преступлений и в 5 раз чаще попадают под арест, чем белые.
- Черные погибают в 2.5 раза чаще от рук служб правопорядка, чем белые.
- Гибель от рук служб правопорядка имеет хорошо прослеживаемую связь с преступностью: чем больше преступлений, тем больше смертельных исходов от встреч с полицией. Эта корреляция подтверждается в целом по штатам и для каждой расы, хотя она немного выше для белых. Это подтверждается и разницей в отношении количества жертв полиции к количеству преступлений и арестов между расами: белые преступники имеют несколько более высокую вероятность встретить смерть, чем черные.
Хочу напоследок выразить благодарность моим читателям, давшим ценные комментарии и советы :)
PS. В следующей, отдельной статье я планирую продолжить рассматривать преступность в США и ее связь с расовой принадлежностью. Сначала поколдуем с официальными данными по преступлениям на почве расовой и иной нетерпимости, а потом поглядим на конфликты между полицией и населением с другой стороны и разберем случаи гибели полицейских при исполнении служебных обязанностей. Если эта тема интересна, прошу дать знать в комментариях!










Комментарии
Основная проблема наркотики и оружейное лобби. Посмотрите канал propolice (не реклама) на ют. То с какой лёгкостью они расстаются с жизнью и то что копы валят наглухо, т.е. если выжил повезло. У них даже есть способ суицида - убийство полицейским. И нужно рассматривать проблему банд и строгости наказания за преступления.
латиноамериканцев человек сходу записывает в белые. Что странно весьма - даже в США в статистике можно встретить деление на черных испаноязычных и не черных
ну и раз уж взялся человек копать глубоко - привел бы сравнительный возраст национальных групп. Очевидно ведь что чем моложе социальная группа, тем выше вероятность насильственных преступлений. И очевидно что афроамериканцы будут в среднем моложе
Файл us_pop, с которым работал автор, содержит столбцы White alone, White alone (Non-Hispanic), Black alone, Black alone (Non-Hispanic), отдельно по Hispanic столбца нет. В принципе взять White alone и Black alone вполне логично.
Претензия не понятна. Что такое - возраст национальных групп?
Это диссертация кандидатская или докторская?
Не знаю. Думаю, оба два сразу нет.
Нет. Нет научной новизны. Просто работа со статистикой. При желании можно из этого сделать статью ВАК.
Впечатляющее исследование.
А латиносов никак нельзя выделить из белых?
Вопрос снимается, выше ответили.
Очень жаль. Получается, какие-нибудь Мара Сальватруча или Синалоа - организации белых.
Преступность в штатах прямо зависит от численности населения.
А можно это интерпретировать как плотность населения?
Не уверен. Можно соотнести данные по преступности с площадями штатов, однако, этого будет мало, так как население в них распределено неравномерно. Гипотеза вполне правдоподобна и даже очевидна в какой-то мере, но подтвердить её пока нечем.
Я с мыслью, что в городах преступность выше, чем в сельской местности.
кэпавтор уже выяснил. Но по концентрации населения в конкретных местах данных на руках нет. Простое деление на количество жителей даёт интересные коллизии. Например, Аляска выходит в лидеры по преступности. Чувствую, там просто почти всё население сконцентрировано в каком-то месте, но показать этого не могу. Тут нужна работа с координатами на местности. В принципе, питон это может, но надо знать координаты мест преступлений. Есть ли такие, или надо восстанавливать координаты по адресам преступлений? Надо иметь данные по концентрации населения с привязкой к координатам. Работа действительно на маленькую диссертацию.По поводу типа местности ещё больше вопросов. Какую местность считать сельской? Считать ли одноэтажную субурбию сельской местностью или нет? Мы знаем, что сельским хозяйством в сошедших штатах занимается около 2% населения. Но где они живут, я честно говоря представления не имею. Если это какие-либо аналоги хуторов, где все родственники, то понятно, что по видам преступлений и их частоте будет сильно отличаться от городских. За отсутствием наркомафии в первую очередь. Рецидивистов вряд ли терпеть будут Ну и т.д.
Нет у меня ответа на этот вопрос. Извините.
Автор исходного поста ответил на простой вопрос - правда ли, что негров валят чаще, чем белых. Ответил чётко и однозначно: и да, и нет. Взяв его математику за основу любой желающий может искать ответа уже на свои вопросы.
Всю эту хрень легче посчитать в экселе, автор вероятно про такую программулину не в курсе. Да и графики там покрасивее. Зависимость количества полицейских убийств от уровня преступности нечего считать и ежу понятно. Тоже мне бином Ньютона. Короче никаких открытий. На дисер не потянет, максимум - курсовик.
Мёржить данные из разных баз с десятками тысяч строк проще в экселе? Ну-ну.
Спасибо - было интересно)) Я бы - из вредности своей - добавил бы - 1. процентное соотношение черных и белых в штате 2. возраст преступников (понимаю, что такие данные получить куда сложнее) 3. количество "ходок" преступника в момент ареста\убийства 4. отделил бы всё же - испаноязычных от всех остальных и причин тому масса. Но - в любом случае - работа ДОСТОЙНАЯ!
Пункты 1 и 4 в технически решаемы, по 3 и 4 не уверен, что такие данные доступны. Я подумаю. Может и возьмусь по 1, 4. Сами понимаете, данные и, самое главное - код, чужие, надо вникать.
В любом случае - повторю - работа ДОСТОЙНАЯ... в отличии от некоторого процента галиматьи, которую зрю ИНОГДА в и_нете )) С другой стороны - непубличная сторона подобных исследований, профессиональных и намного-намного более глубоких присутствует "где надо" и давно, НО - она недоступна для массовой аудитории (что тоже, надо признать, часто, оправданная правильная или вынужденная мера)

Понятно, что автор хочет как лучше и отводит от себя подозрения, но как же раздражает это самооправдывание. А ведь могут найтись те, кто придерутся к нейтральным по сути словам. Но на мой взгляд, они и сами так думают, раз видят в словах что-то непотребное. Там где его нет. Где нет текста с эмоциональной окраской.
Каждый думает в меру своей испорченности (с)
Читаю дальше
Любому жителю США известно, что есть четыре "расы": белые, латиносы, негры и азиаты. Я использую краткие названия для сокращения длины текста, а не для нанесения обиды кому-либо по каким-либо поводам. Латиносы - это не белые. Их даже в тюрьмах содержат отдельно. Всего одно неверное допущение делает всю работу бессмысленной. Она остаётся статистически безупречной, но теряет смысл. Вероятно, что статистика, во имя политкорректности, именно так и ведётся, но это искажает картину в целом.
В банке данных, с которым работал автор, hispanic - это скорее язык, чем принадлежность к расе. Так как и белые, и чёрные приведены как белые и чёрные целиком, так и "белые без хиспаник", и "черные без хиспаник". Зато для "хиспаник" отдельно столбца не нашлось. Ну и латиносов к африканцам отнести всё же труднее, чем к европеоидам, на мой непрофессиональный взгляд.
Для меня это новость. А по какой причине?
Почему? К кому ты отнесешь большую часть кубинцев, ямайкцев, пуэрториканцев и прочих выходцев с карибских островов? А вот мексиканцы в массе своей европеоиды. Вот и не получается их разделить.
А мне зачем? Вот полный список наименований этих самых, имеющийся на руках у автора работы. Это из банка данных по популяции:
То есть, вся вот эта солянка - какие-то смеси, две и более рас или некоторые другие. Зато хиспаник отдельно здесь нет.
При этом, банк данных по погибшим от рук правосудия по названиям "рас" не совпадает:
Здесь какие-то средне восточники появляются, и испанцы/латиняне отдельной стройкой. Что делать с блэк хиспаник из первого банка в связи с этим не совсем понятно. Я в принципе понимаю, почему автор всех кроме блэк и вайт отчислил.
Вот об этом я и говорю. Уровень доходов/образования чудовищно разные, но ради красивых цифр всё это сведено в условный "один столбец". Условный молодой мексиканец, который вчера переплыл Мексиканский залив и работает, в лучшем случае, уборщиком приравнивается условному белому оболтусу, который отсидел 12 лет в школе.
Вероятно, по причине ужасающего накала дружбы народов, когда латинос плохо говорящий по-английски будет, как минимум, вечной мишенью злобных шуток. Равно как и W.A.S.P. без испанского среди латиносов будет на тех же ролях. Оптимизация личного состава надзирателей и ничего больше.
З.Ы. Краткие наименования использованы только в целях сокращения текста.
У нас по преступности "приезжие" аналогично черным имеют повышенные показатели. Однако черные понаехали сотни лет назад. Вывод: понаехавшие не исправляются за сотни лет.
Неужели это гены? Да ну, ерунда какая-то.
Перспективный чат детектед! Сим повелеваю - внести запись в реестр самых обсуждаемых за последние 4 часа.
Как расово некорректно... БЛМщики и прочие мемориальщики тебя-бы заклевали, будь у них значимо влияние в РФ.
Автор работы не прочитает скорее всего. Чем, кстати, расово некорректно-то? Не толерантно, может быть?
Тебя-бы как распространителя они-бы тоже пытались загрызть и да, в слове толерастно у вас 1 грамматическая ошибка!
А толерантность, что притащили из медицины - это когда организм воспринимает что-то чуждое вредное как своё, и не может сопротивляться. Не собирался и не собираюсь, кто бы чтобы не свистел.
сильно напомнило как я свои пирамиды для книжки считал...
афтар явно неравнодушен к черным, перепощивает простыни бессмысленного текста о суровых черных мужчинах
не палится совсем просто