





Лучший способ в чём-то наконец разобраться - попытаться объяснить это другому. В благодарной аудитории и сам узнаешь много нового. Темы могут быть самые разнобразные. Начну с простого вопроса - проблема кодировок. Вопрос недавно мимоходом поднимался на АШ. Для затравки утяну целиком статью четвертьвековой давности - любая научная работа начинается с обзора литературы. А там как кривая вывезет, в зависимости от обратной реакции.
Электронная почта по-русски
16.07.1996 Сергей Мелихов
Семь раз отмерь, один отрежь - такова еще недавно была печальная судьба восьмого бита при передаче по электронной почте. Это цветочки, ягодки - отсутствие стандартной общепринятой кодировки русского языка.
Давным-давно, четверть века назад, американцы создали Сеть. Спроектировали они ее для научных целей, то есть для себя, американцев. Компьютеры, которые эта сеть связала между собой, так же были сделаны в Америке и для американцев. И все было хорошо, потому что в Америке одни американцы. Потом Сеть всем понравилась, и ее отдали народу. И компьютеры появились у народа, и не только у американского. А для оборонных целей сделали еще одну Сеть, а потом еще.
ТАБЛИЦА СИМВОЛОВ ASCII
Так вот, в те годы (давным-давно) нормальные американцы, те, что делают компьютеры, еще не знали, что кроме американского народа существуют другие народы. Открытия Европы и других стран тогда еще не произошло. Правда, некоторые американцы по долгу службы, конечно, знали о существовании других частей света, а кое-кто из них даже догадывался о наличии других языков, помимо американского.
Но время шло, число иноземцев, имеющих доступ к компьютерам, росло, и - о ужас - однажды они возжелали общаться между собой через электронные средства коммуникации, причем на своем тарабарском языке! Им, видите ли, так естественней. Тут-то и выяснилось, что американские программы для общения на тарабарском языке не очень-то и годятся, поскольку рассчитаны только на американский алфавит.
Если кто не знает, американский набор символов самый маленький, даже англичанам требуются странные дополнительные значки для обозначения их денег. А французам простых букв-то надо раза в полтора больше. Про нас, русских (или российских?), мы вообще до поры до времени скромно умолчим.
Так вот, когда американцы создавали свои компьютеры, они решили, что для представления всяких печатных символов с лихвой хватит 128 чисел. Ну в самом деле, 27 строчных букв, 27 прописных, 10 цифр, десяток знаков препинания - от силы 80 получается. Так что еще и запас оставался, ничего не скажешь.
Ну дальше понятно, 128 это 2 в степени 7, значит для представления всевозможных символов было достаточно 7 бит. Именно такой, 7-битной, является таблица символов ASCII. Первая буква означает "для Америки".
ТАБЛИЦА СИМВОЛОВ LATIN-1
Иноземцы, недовольные дискриминацией их родных языков какими-то компьютерными железками, стали жаловаться американцам. Последние сначала свои компьютеры защищали и предлагали несчастным бросить мучиться попусту и переходить на нормальный язык. Как всегда бывает, ряды недовольных раскололись, нашлись штрейкбрехеры, и не ясно, чем бы дело кончилось, не вмешайся Правительства иноземцев. Правительства запретили родной язык забывать, а с американцами даже пригрозили поссориться. И те наконец начали шевелить мозгами.
Вообще-то для представления каждого печатного символа с самого начала разработчики компьютеров и программного обеспечения выделяли один байт. В байте всегда несколько бит, в процессе естественного отбора выжили и размножились только байты, состоящие из 8 бит. Лишний бит - это еще 128 символов, и там можно разместить все крючки и завитушки, столь милые сердцу западных европейцев. Так и была создана таблица символов Latin-1. Лучше, однако, не стало. Если бы было хорошо, нечего было бы и эту статью писать.
ПАРТИЗАНЫ НА РЕЛЬСАХ СЕТИ
Появление таблицы Latin-1 решило проблему представления некоторых национальных алфавитов. Но теперь нужны были программы, способные с этими представлениями работать! Программы, которые американцы написали до этого, не подразумевают наличия информации в 8-м бите! Разумеется, программа, нерассчитанная на 8-й бит, может неожиданно заработать и с 8-м битом. Но это некачественная программа. Те программисты, хорошо успевавшие в школе, твердо запомнили: параметры функции следует проверять на область определения, а результат - на область допустимых значений. И проверяли, тем более, что это было элементарно - 8-битные символы выглядели точь-в-точь как отрицательные числа. Сравнил с нулем, и все. То, что выходило за рамки, признавалось мусором. А рамки-то жестко запрограммированы, значит, надо программу переделывать, а программ много, а люди не вечны...
Теперь представим себе европейца, создающего информационную систему для своего предприятия. Ему нужна таблица Latin-1, он ищет ПО, которое ее поддерживает, если чего-то не нашел, то разрабатывает сам. В конце концов проблема решается. Теперь тот же самый европеец решил сообщить о своем успехе другому европейцу посредством крайне удобного способа общения - электронного письма. У каждого из них почтовая система пропускает 8-й бит (предположим). Но пути Господни неисповедимы, и по дороге сообщение попадает на промежуточную почтовую машину, где 8-й бит по старинке считают мусором и обнуляют. Все, господа, приехали.
Хорошо, если упомянутая выше нехорошая машина находится там же, в Европе. Можно, что называется, пойти и договориться. А если не в Европе? А если почтовых машин сто тысяч, и только тысяча из них "режет" (обнуляет) 8-й бит? А письма ходят разными, подчас непредсказуемыми путями? Вы, наверное, согласитесь со мной, если я сравню такие почтовые машины с диверсантами, залегшими возле железнодорожного полотна. И, как и в случае с настоящими диверсантами, борьба с ними была долгой и мучительной.
ТАБЛИЦА СИМВОЛОВ КОИ-8
Теперь оставим западных европейцев, не такие уж они, в конце концов, несчастные. Ну потеряли пару завитушек в письме, остальные буквы-то читаются! Неприятно, но понятно. Давайте подумаем о нас, европейцах не просто восточных, а, как бы это сказать... дальне-восточных. Наш алфавит отличается от латинского полностью, символов в нем много (66), поэтому в таблицу Latin-1 вместе с латинскими завитушками он не уместился. Придумали ему отдельную таблицу, она получилась пятой по счету. В результате называться эта таблица стала ISO 8859-5. Кто придумал эту таблицу, неизвестно. ISO 8859-5 - это продукт в чистом виде, вещь в себе, прекрасная в своей чистоте и возвышенности. Создатели ISO 8859-5 абстрагировались от массы технических проблем, способных повлиять на расположение русских букв в таблице. Например, она конфликтует с псевдографикой в DOS, почему-то не подошла для Windows. А тема нашего разговора - электронная почта?
Представьте себе письмо, написанное по-русски, отправленное электронной почтой и нарвавшееся по пути на "диверсанта", срезающего у всех писем 8-й бит. После такого "обрезания" те буквы, что были русскими, становятся латинскими. Теми, чей номер в таблице меньше ровно на 128.
Теперь поставим себя на место разработчиков таблицы символов кириллицы, желающих повысить устойчивость передаваемой текстовой информации к "обрезанию". Наверное, нам захочется сделать так, чтобы адресат смог понять содержание письма, написанного по-русски, пусть и латинскими буквами. К счастью, значительное число букв кириллицы имеет фонетические аналоги в латинском алфавите. Допустим П и P, Р и R. К тому же есть несколько совпадающих и по написанию. Значит, разумно расположить русские буквы таким образом, чтобы они отличались от аналогичных латинских на число 128! Тогда потеря 8-го бита превратит сообщение хоть и в состоящий из одной латиницы, но все равно читаемый по-русски текст. Неприятно, зато понятно.
КОИ-8 как раз и есть такая таблица. И именно она применяется для обмена почтой и новостями в Internet. Надеюсь, я смог доказать вам, что КОИ-8 не блажь, а суровая необходимость. Если же вы полагаете, что с истреблением "диверсантов" КОИ-8 больше не актуальна, приведу один свежий случай.
Одна моя знакомая поехала в качестве аспирантки в Англию. Там была машина и электронная почта. Первое письмо, которое я от нее получил, было на языке "ruglish", том самом фонетическом эквиваленте, когда "здравствуй" выглядит как "zdrawstwuj". Брр... Я, знаете ли, предпочитаю творение Кирилла и Мефодия для общения с соплеменниками, поэтому часть своего ответа написал по-русски, в КОИ-8. Я это сделал в надежде, что мой корреспондент, может быть, просто не знает, что все уже налажено. Если нет, то по симптомам (закорючки таблицы Latin-1 вместо русских букв, например) можно было бы предложить простой выход, допустим прислать правильный экранный шрифт.
Но не тут-то было. Во-первых, в том английском университете, где работает моя знакомая, затаился "диверсант", и он срезал 8-й бит в каждом символе моего послания (вот он, консерватизм!). В результате же письмо было прочитано! Оно стало похоже на близкий сердцу уехавших русских "ruglish", хотя и отличалось в способе имитации ряда букв. Ни о каком использовании кириллицы и речи больше не было, ведь "ruglish" это так удобно - "my vse tak pishem". Но это уже тема для социологической науки.
ДРУГИЕ ТАБЛИЦЫ СИМВОЛОВ
Итак, придумали таблицу символов (мы еще говорим: "кодировку", поскольку с помощью таблицы "закодирован" русский алфавит) для обмена почтой и назвали ее КОИ-8, что означает "код отображения информации 8-битный". И, скажете вы, наконец-то все образовалось. Нет, дорогие читатели, не образовалось (хотя и стало легче, конечно). Потому что случился очередной качественный скачок в наступлении компьютеров на нашу маленькую планету. Недорогие персональные компьютеры сделали огромное количество ничего не подозревавшего народа пользователями. А когда масса народа овладевает какой-нибудь идеей или вещью, эта идея или вешь настолько видоизменяется, что хорошо, если не становится своей противоположностью. Так и с компьютерами. Персоналки перевернули все вверх тормашками.
Раньше компьютерный пользователь кое-что знал о своем компьютере и грамотно его использовал - теперь большинство ожидает от машины, что она сама себя настроит, наладит, договорится с другими машинами, а пользователю останется только получать удовольствие. Просить пользователя прочитать пяток страниц руководства и ввести пару адресов Internet - чуть ли не дурной тон.
Я не хочу сказать, что это плохо - просто это другая жизнь.
Надо ли объяснять, что огромная масса персоналок имела свои собственные проблемы и устанавливала свои собственные стандарты. Одна из таких проблем нас с вами касается - это поддержка русского языка. Электронная почта мало кого тогда волновала, а вот вводить и обрабатывать русские тексты в многочисленных программах для DOS надо было всем. Кодировка КОИ-8 не подходила для этой цели (так же, как и ISO 8859-5), в ее таблице некоторые русские буквы находились на тех местах, которые по разумению зарубежных программ были заполнены графическими символами - вертикальными и горизонтальными черточками, различными уголками, прямоугольниками и т.д. Псевдографические символы были очень важны - с их помощью персоналки делались привлекательными для пользователей. Поэтому была придумана еще одна кодировка кириллицы, в таблице которой русские буквы "обтекали" со всех сторон графические символы. Назвали эту кодировку "Альтернативной", поскольку она была альтернативой официальному стандарту - кодировке ISO-8859-5. Последнюю, чтобы не обиделась, стали величать "Основной". Но ею все равно почти никто не пользовался.
Когда настала очередная революция и все бросились осваивать Windows, выяснилось, что Альтернативная кодировка не подходит - говорят, какую-то ее часть первые версии Windows не обрабатывали ("не пропускали"). Основная тоже не подошла. Ничтоже сумняшеся кто-то подвинул русские буквы в таблице так, чтобы все они "пролезали", благо псевдографика в Windows не требуется, и получилась кодировка "Windows 1251", самая, наверное, теперь распространенная.
А КАК ЖЕ С ПОЧТОЙ?
Итак, мы назвали четыре кодировки кириллицы. Все они объективно существуют, все используются. А почта? Internet - это то место, где вопрос, какую кодировку применять, перестает быть личным делом каждого. Если вы отправляете кому-то сообщение, то, вероятно, затем, чтобы его прочитали. Если ваш получатель работает в DOS, а вы в Windows, то простая пересылка текста вряд ли поможет. Даже если письмо, отправленное в альтернативной кодировке из DOS, дойдет до адресата в неискаженном виде, получателю придется:
- либо также запустить программу для DOS, чтобы его прочитать;
- либо каким-то образом перекодировать полученный текст, чтобы его смогла отобразить программа для Windows;
- либо обучить программу для Windows отображать "неродную" кодировку кириллицы;
- либо любоваться "зюками" на экране.
Проще говоря, для того, чтобы обмениваться почтой по-русски, надо что-то наладить. Об этом мы и поговорим.
Для тех, кто не хочет ничего налаживать, есть готовые решения. Например, для DOS - пакет под названием UUPC. Вам придется его установить и пользоваться только им, и только в DOS, и только в сочетании с модемом. Зато он будет конвертировать отправляемую корреспонденцию в кодировку КОИ-8, а приходящую - в Альтернативную. Вам об этом думать не надо. Если хочется чего-нибудь покрасивее - читайте дальше.
ДЛЯ ОСТАЛЬНЫХ СООБЩАЕМ...
Существует несколько способов обработки передаваемой по Сети электронной почты (аналогичные рассуждения применимы и к новостям, поэтому мы больше не будем их упоминать). Эти способы естественным образом вытекают из того, как организована передача почты.
Пользователь взаимодействует с почтовой программой (user agent), которая позволяет ему вводить и читать письма, организовывать хранение пришедших писем, вести адресные книги и т.д. Можно сказать, что основная функция почтовой программы - предоставить удобный пользовательский интерфейс. Чтобы доставить или получить письмо, почтовая программа обращается к доставщику (delivery agent), пользовательского интерфейса не имеющего, зато владеющего тонкостями маршрутизации корреспонденции. Доставщик напрямую или через промежуточные машины передает письмо другому доставщику, который обслуживает адресата. Тот кладет письмо в персональный почтовый ящик, откуда его забирает почтовая программа получателя. Это схема общая, в реальной жизни пользовательская почтовая программа может выполнять часть функций доставщика. Мы рассмотрим некоторые варианты ниже.
Итак, где-то надо перекодировать письма. Уходящие - в КОИ-8, приходящие - в ту кодировку, которую предпочитает пользователь. Исходя из нашей схемы это могут сделать и почтовая программа, и доставщик.
Рассмотрим каждый вариант.
ПЕРЕКОДИРОВКА В ПОЧТОВОЙ ПРОГРАММЕ
Вообще-то, в идеале почту надо приводить к стандартному виду как можно раньше, еще перед отправкой. В этом случае мы не рискуем нарваться на ошибку или на сбой при доставке, связанные с неправильной кодировкой письма. Однако здесь есть сложности.
Как вы, наверное, заметили, модульность приведенной выше схемы предоставляет нам свободу выбора почтовой программы. Таких программ достаточно много. Их десятки для Unix и сотни для Windows. Сам этот факт должен нас насторожить, если мы собираемся выработать сколько-нибудь общее решение. Ведь все это изобилие создано другими людьми, в большинстве своем американцами (см. выше), которые не подозревали о нашей с вами потребности почту перекодировать. И никак они не приспособили свои (в остальном - просто чудесные) программы к такой перекодировке.
Здесь стоит упомянуть одну замечательную почтовую программу - Zmail компании NCD Software, в которую возможность автоматической обработки приходящей, уходящей и сохраняемой в папках корреспонденции была заложена с самого начала. Однако все усилия автора и его коллег использовать эту возможность для перекодировки пошли в свое время прахом. Этого Zmail не смогла.
Большой выбор означает, что, даже если мы научим конкретную программу перекодировать почту, это все равно будет частное решение - мы не сможем заставить всех пользоваться именно этой программой (даже если мы - Microsoft), а нам ведь с ними (всеми) переписываться...
Тем не менее бывают ситуации, когда оторванный от Родины простой русский человек, не имеющий ни понимающего его проблемы провайдера, ни Unix на своей машине, просто вынужден что-то предпринимать. Давайте сразу дадим таким пользователям пару советов:
- если сможете, найдите почтовую программу, умеющую перекодировать корреспонденцию. Или напишите такую программу сами, если это дело вам по душе;
- если нет, то достаньте русификатор для Windows (пользователи DOS, наверное, уже перестали читать статью, а пользователи Unix и локальных сетей будут обслужены далее по тексту), позволяющий вводить и отображать (то есть имеет соответствующий набор шрифтов) кодировку КОИ-8. Настройте почтовую программу таким образом, чтобы она использовала шрифты КОИ-8, а для ввода текста переключайте клавиатуру не на стандартную для Windows кодировку 1251, а на ту же КОИ-8.
Вам гарантирован успех, если почтовая программа не слишком умная и не пытается анализировать вводимые вами символы на предмет их принадлежности к какому-нибудь алфавиту. В противном случае вам предстоит еще разобраться, каким образом она это делает.
В большинстве случаев почтовые программы пугаются любых 8-битных символов и начинают их шифровать при отправке так, что потом 90% народа прочесть не может. Это гордо называется MIME, "quoted-printable" и проч. Если вы хотите быть понятым, отключайте шифровку 8-битных символов. Далеко не все почтовые программы могут автоматически и корректно восстановить текст из бессодержательного набора букв, цифр и знаков препинания.
Посылая подобные письма неизвестному адресату (с которым вы не успели договориться о вашем общем формате писем), вы проявляете к нему неуважение. Я лично воспринимаю такие послания не как неуважение, а как проявление технической безграмотности, не знаю, что для отправителя лучше. Обычно подобными вещами грешат торговцы, заваливающие наши почтовые ящики своими объявлениями.
Наиболее одиозный случай из моей практики - письмо, содержащее зашифрованный программой UUENCODE
ZIP-архив, в свою очередь содержащий текст в Альтернативной кодировке. Сколько надо потратить времени, чтобы его прочесть пользователю Windows? При этом письмо не очень большое, компрессия дает экономию только отправителю, рассылающему его по сотням, если не по тысячам адресов.
ПЕРЕКОДИРОВКА ДОСТАВЩИКОМ
Итак, не мытьем так катаниьем, почтовую программу для Windows можно заставить отправлять письма в КОИ-8. Но усилия требуются значительные, и не всегда получается удобно.
Гораздо лучше, если программное обеспечение почтовой машины само может перекодировать почту. Тогда вы берете ту почтовую программу, которая вам больше по душе, и все. Только не забудьте отключить шифрование 8-битных символов.
Коль у нас речь все больше идет о персональных компьютерах и их пользователях, необходимо сказать, что им приходится общаться сразу с двумя серверными программами, выполняющими роль доставщика.
Первая служит для отправки почты и называется "служба SMTP". SMTP - протокол передачи писем в Internet. Вообще-то, служба SMTP и принимает письма тоже, а не только отправляет. Однако при приеме корреспонденции пользователям персоналок на SMTP рассчитывать не приходится. Дело тут вот в чем: служба SMTP исходит из того, что машина-получатель всегда готова к приему почты. 24 часа в сутки, 7 дней в неделю. Конечно, она сможет переждать кратковременный сбой, но это уже ненормально, ЧП. Понятно, что постоянная готовность к приему почты по инициативе удаленного сервера не есть свойство персональных компьютеров. Их просто выключают, когда не используют, не говоря уже о низкой надежности, ущербной многозадачности и т.д.
Поэтому почта, предназначенная для пользователя ПК, складируется на почтовой машине. Передается она на персоналку по инициативе пользователя, когда он готов ее принять. Этим заведует служба POP (Post Office Protocol).
Дальше все очевидно: сервер SMTP надо научить переводить письма из той кодировки, в которой, по воле Аллаха, представлено отправляемое письмо, в кодировку КОИ-8. Сервер же POP должен переводить письма из КОИ-8 в ту кодировку, которую сможет понять пользователь. В какую только... И кто будет учить...
КАК НАСТРОИТЬ ПЕРЕКОДИРОВКУ НА ПОЧТОВОЙ МАШИНЕ
Как и в случае с почтовыми программами, доставщики уже написаны. Наиболее известные программы такого рода - sendmail и MMDF. Причем sendmail является стандартом de-facto. Sendmail входит в любой Unix и, кроме того, доступен в исходных текстах.
Мы не будем сейчас говорить о несовместимых с SMTP (то есть с Internet) почтовых системах, таких как Lotus cc:Mail, Microsoft Mail. Внутри сетей, обслуживаемых подобными системами, поддерживающими русский язык, наверняка либо все в порядке, либо безнадежно. Нас это не касается, мы рассуждаем о почте в Сети, с которой несовместимые почтовые системы совмещаются с помощью шлюзов.
Кстати, коль в очередной раз прозвучало слово "Unix", то надо наконец объясниться с теми, кто это имя переносит плохо. Итак, если Unix вызывает у вас аллергию, подставляйте вместо него далее по тексту одно из слов: NT, VMS, DOS, NetWare. Чем дальше выбранное вами слово стоит в списке, тем дороже и неудобнее будет ваше решение.
В оригинальном виде ни sendmail, ни MMDF не предназначены для перекодировки почты. Однако и та и другая имеют модульную структуру, иначе состоят из нескольких самостоятельных программ, каждая из которых выполняет свою задачу. Одна принимает корреспонденцию от локальной почтовой программы (то есть работающий на той же машине, что и доставщик), другая отправляет письма через медленные модемные соединения по протоколу UUCP, третья заведует коммуникациями по SMTP, четвертая кладет почту в почтовые ящики пользователей. И есть центральный распорядитель, который всем управляет. Для того чтобы организовать перекодировку, нужные нам модули надо модифицировать. Для этого вовсе не обязательно их переписывать и перекомпилировать. Модуль можно "обернуть" в универсальный перекодировщик. Такой универсальный перекодировщик вызывается вместо оригинального модуля, принимает за него письма, перекодирует их и передает в обработанном виде оригинальному модулю. Аналогично можно "обернуть" и сервер POP.
Так выглядит решение в целом. Конечно же, если вы начнете реализовывать все это своими руками, то столкнетесь с трудностями. На одной такой сложности мы остановимся, поскольку она имеет принципиальный характер.
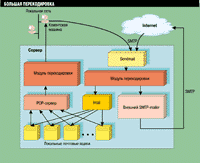 (1х1)
(1х1)
Кириллизация Unix.
Чтобы научить электронную почту говорить по-русски, необходимо использовать универсальные модули перекодировки.
ИЗ КАКОЙ ТАБЛИЦЫ И В КАКУЮ ПЕРЕКОДИРОВАТЬ
Тут главное не ошибиться. Если текст представлен в Альтернативной кодировке, а вы его конвертируете, как будто он в Windows 1251, то я вам гарантирую, что информация будет серьезно повреждена, если не уничтожена.
В случае с приходящими письмами (мы предполагаем, что они в КОИ-8, но рассчитывать на это тоже нельзя!) надо знать, какую кодировку использует получатель. Пользователи Windows желают получать письма в 1251, DOS - в Альтернативной, а на Unix вообще могут существовать все кодировки одновременно.
Это была постановка проблемы, теперь решение. Решение называется Cyrillic Support Manager, или сокращенно CSM. CSM - это комплексный кириллизатор Unix; он имеется для всех коммерческих реализаций этой операционной системы, а также для Linux, правда, в неполном объеме. Система перекодировки почты является составной частью CSM. Давайте посмотрим, как она решает поставленную задачу (откуда и во что перекодировать письма).
ОТКУДА
Как всегда, есть несколько подходов к проблеме. Вот некоторые из них:
- брать информацию о кодировке из служебных полей заголовка письма;
- брать информацию из конфигурационных файлов;
- иметь выделенный виртуальный сервер для работы с каждой из кодировок;
- определять кодировку по содержимому письма.
Первый подход перекладывает ответственность на конечного пользователя. Он должен в заголовок письма включить команду на перекодировку. Иногда это бывает полезно, но, как основной режим, такое решение не годится - неудобно.
Второй подход гораздо мощнее. Администратор почтовой машины один раз определяет, что клиентская машина с таким-то сетевым именем или адресом работает в кодировке, скажем, Windows 1251. И теперь вся корреспонденция, отправляемая с данной машины, считается представленной только в этой кодировке. А если у машины нет постоянного адреса? Она может перемещаться по странам и континентам, подключаясь к различным узлам Internet, но все равно обращатся к своему почтовому серверу и почтовому ящику. Даже если пользователь соединяется с одним и тем же провайдером, он может получать на время каждого сеанса другой IP-адрес. Да и в локальных сетях динамическое распределение адресов применяется.
Выделенный виртуальный сервер. Давайте запустим на одной почтовой машине четыре почтовых сервера одновременно, по одному на каждую кодировку. Каждому серверу присвоим отдельное сетевое имя и отдельный IP-адрес, например win.mail.access.ru, alt.mail.access.ru, koi.mail.access.ru, iso.mail.access.ru. Предложим пользователям Windows обращаться со своей почтой на сервер win.mail.access.ru, DOS - alt.mail.access.ru и т.д. Этот вариант не требует фиксировать IP-адрес клиента, не заставляет пользователя в каждое письмо вводить информацию об его кодировке. Пользователю достаточно при конфигурации своей почтовой программы правильно указать адрес почтовой машины. Если он с этим справится, то все ОК. А если нет? Пользователь, он такой. Или включит в письмо, отправляемое из Windows, текст в Альтернативной кодировке? У него же на машине еще и DOS есть! Если бы у нас не было четвертого варианта, мы бы сказали, что это проблемы пользователя. Однако у нас еще четвертый подход есть.
Идея автоматического определения кодировки смотрится существенно лучше, и это решение гораздо ближе к идеальному. Однако необходим хороший алгоритм распознавания, которому мы могли бы доверить свою информацию. Ведь ошибочная перекодировка приводит, как мы уже упоминали выше, к ее потере. Простая проверка байтов на потенциальную принадлежность к той или иной таблице символов не годится. Дело в том, что все четыре кодировки сильно пересекаются между собой, и нужен очень большой текст, чтобы собрать достаточно статистики. Поэтому, если мы хотим надежно определить, в какой кодировке представлен текст, то должны попробовать его прочитать, перебирая все варианты. Именно так поступил бы человек. Но как научить читать компьютер? К счастью, компьютеру в данном случае не надо уметь полноценно читать, достаточно научиться отличать русский язык от абракадабры. Можно было бы попытаться применить одну из программ коррекции правописания, например. Однако что делать с грамматическими ошибками? Есть такие "писатели", что способны свести подобные программы с ума...
В общем, пришлось разработать свой алгоритм анализа текста, простой, неизбыточный (то есть не проверяющий правописание там, где это не требуется) и надежный. Теперь можно ответственно заявить, что автоматическое определение кодировки существует и работает достаточно хорошо (достаточно - это значит, что со сбоями мы не сталкиваемся уже пару лет). Однако, случайно, у кого-нибудь может возникнуть нужда передать по почте ту самую абракадабру. Система распознавания выдаст сообщение о том, что кодировка не определена, и письмо уйдет без перекодировки (или не уйдет вообще, если так установлено администратором). Тем не менее отправлять по почте абракадабру - конституционное право пользователей электронной почты. И поэтому в CSM реализованы все четыре подхода к определению кодировки письма. Основной метод - автоматическое определение. Но всегда есть возможность явно задать кодировку одним из способов.
КУДА
Теперь давайте доставлять письма. Нам нужна информация о том, в какую из кодировок его переводить. Из четырех способов, подробно описанных в предыдущей главе, мы можем использовать первые три:
- брать информацию о кодировке из служебных полей заголовка письма;
- брать информацию из конфигурационных файлов;
- иметь выделенный виртуальный сервер для работы с каждой из кодировок.
Первый вариант в данном случае означает, что отправитель письма или администратор его машины, зная заранее о том, в какой кодировке желает получать письма конкретный адресат, вручную или автоматически внесли в служебный заголовок письма соответствующую запись. Письмо, так сказать, само знает, как его доставлять. Этот механизм является резервным на случай всяких исключений.
Конфигурационные файлы - вещь хорошая, но они не годятся в случае с непостоянными IP-адресами (см. выше). Когда же речь идет о локальных пользователях Unix, это наилучший выход. Рабочая кодировка пользователя или предпочитаемая им кодировка почтового ящика всегда известна из системных или персональных конфигурационных файлов CSM.
Виртуальный POP-сервер (именно по POP-протоколу получают свою корреспонденцию пользователи персоналок) не только дает нам возможность менять IP-адрес клиентской машины по своему усмотрению, но и облегчает администрирование локальной сети. Каждую новую машину в конфигурационном файле описывать не надо. А вводить имя почтовой машины в почтовую программу надо в любом случае.
ЗАКЛЮЧЕНИЕ
Надеюсь, что автор внес некоторую ясность в вопрос о том, как должна передаваться русскоязычная почта. Да, в настоящее время для организации нормальной работы почты требуются дополнительные усилия. Хорошо, если эта работа возлагается на плечи профессиональных (то есть получающих за это плату) администраторов почтовых машин. Хуже, если проблемой перекодировки приходится заниматься конечному пользователю. Это случается редко, в основном за границей, но тем сложнее человеку - не с кем посоветоваться, в конце концов. Может быть, ситуация скоро изменится. Нам очень хочется переписываться с вами по-русски, а не "po-russki".
Сергей Мелихов - технический директор компании DataX/FLORIN. С ним можно связаться через Internet по адресу: melihov@florin.ru.
Комментарии
Эх времена были... помню даже писал перекодировщик (блин, а это и был реально ИИ - в письме с кракозябрами, понять какая таблица использовалась и сколько раз для перекодировки) . для пользователей даже был специальный ящик, куда отправлялось письмо , а обратно в перекодированном виде :))
брать информацию о кодировке из служебных полей заголовка письма;
ВЫ это только M$ Exchange не говорите, они как-только отошли от 1251 (в то время они еще смотрели на заголовки) в сторону UTF, так и забили на эту порочную практику... пофиг что в заголовках - есть только UTF...
Сейчас почтовики, особенно с веб-интерфейсом, вроде перешли на повсеместное использование utf-8 и проблемы с кракозябрами/вопросиками ушли в прошлое. Можно, конечно, откопать с раритетного пиратского СD какую-нибудь "какашку мамонта" и троллить ей собеседника.
Более актуальный на сегодня вопрос - кодировки в именах файлах. На диске в записях файловой системы разные операционки используют одни кодировки, проводник пользователю может показывать в другой, а конкретная версия архиватора - класть имя файла в архив в третьей. Если все дружно используют utf-8, то никаких проблем. А так да, до сих пор, возможны самие разнообразные варианты. Как, например, обсуждается здесь
https://iu5bmstu.ru/index.php/Windows_-_%D0%9A%D0%B8%D1%80%D0%B8%D0%BB%D...
Варианты решения в каждом конкретном случае, конечно есть. Например, если есть необходимость пользоваться именно .zip, то, можно поступить так
Можно, конечно, откопать с раритетного пиратского СD какую-нибудь "какашку мамонта" и троллить ей собеседника.
ну кодировку по-умолчанию никто не отменял, но когда есть в заголовках явное указание кодировки , то тот же екченж 16 кладет с прибором...
а не работает в соответствии с указанным...
согласен какашка, но явно не мамонта :))))
Это уже к программистам. Которым просто лень поддерживать все возможные кодировки.
Сколько их там успело расплодиться до появления utf-8. Кроме английского языка и нескольких вариантов кириллицы - куча национальных чарсетов. И какой программист в здравом уме будет без прямого на то указания поддерживать их ВСЕ?
У меня Вин10 LTSC, проблема такая есть, кракозябры в русских именах части файлов, в другой винде нормально эти файлы отображаются, чего можно накрутить в данном случае??
Хотелось бы поконкретнее, чем именно отличается эта часть файлов. Каким образом они были получены, можно ли смоделировать эту ситуацию на файлах с безобидным содержанием?
Архив RAR, имя папки при распаковке этого архива, внутри этой папки русские имена файлов отображаются правильно, PDF файл. Чем они от аналогичных файлов, русские имена которых отображаются правильно, отличаются, не могу понять.
winrar, в отличие от zip, имена файлов в архиве хранит в utf-8.
Могу предположить, что в новой версии виндов подправили интеллект функции, которая распознаёт, чем является последовательность байт - строкой в utf-8 или в СР-866. На некоторых именах эта функция ошибается, получаются кракозябры. На некоторых нет - всё правильно.
Давно ходила байка, что в Микрософт над разными версиями работают две практические независимые команды. Одна послабее, другая посильнее. Поэтому нечётные версии обычно выходят лучше чётных.
Если выложите архив rar c неправильно отображаемыми именами файлов (если только в них нет никакого секрета), можно сказать что-то конкретнее, покопаться в MSDN.
Спасибо за предложение секретов нет, но не стоит Вам заморачиваться, переименую проще будет
секретов нет, но не стоит Вам заморачиваться, переименую проще будет
Посмотрите здесь, вдруг поможет и в Вашем случае.
Из комментариев
Штирлиц жив
ну реально, был момент когда почта приходила хрен знает а каком виде... :)
но были времена в эпоху UUCP - инет не сколько ограничен, о нем и не знают :))) Ни каких проблем с кодировками :))))
Кроме почты, есть еще веб-страницы. А там и посейчас приходят всякие и, " ...
Даже просто имя web-страницы, когда разрешили нелатиницу - отдельная песня.
Браузер показывает так
https://ru.stackoverflow.com/questions/702821/Кириллица-в-доменном-имени-сайта
При попытке сделат копи-паст имя трансформируется в
https://ru.stackoverflow.com/questions/702821/%D0%9A%D0%B8%D1%80%D0%B8%D...
А если дизайнер в имени web-страниц нагородил всяких красивых символов из знаков препинания (< > ! * |), сделать Save Page As, не отредактировав имя самому, то можно получить файл с таким именем, что ни убить, не переименовать. Только format C: Или кто знает способ попроще? Типа diskeditor.
Как вариант, работали DOS-команды DEL *.
Или удалить вместе с папкой верхнего уровня, перенеся все нужное в другую.
Еще эти команды (del * и rmdir <содержащая папка>) можно попробовать выполнить в консоли восстановления или в оболочке WinPE разных версий.
Нужные файлы и папки сначала переместить куда-нибудь, потом вернуть назад.
Спасибо! Чтоб не быть голословным, поищу на работе (на этой неделе я на удаленке) вроде осталась флешка, где такие вот файлы мне не удалось убить rm даже под чистым линуксом - FILE NOT FOUND. А папка не уничтожалась, потому что NOT EMPTY. Найду - отпишусь.
Заодно смешной случай. Вставляю в ноут с убунтой внешний хард на 4Тб, ntfs. А линукс - ваш диск read-only! Что за дела? Вроде поддержку ntfs в линукс ещё при динозаврах добавили! Оказалось, я выдернул до того этот диск из виндового компа в спящем режиме. Помогло вставить в виндовый комп обратно. Честно выключить его (не спящий режин и прочий гипернайт) и только после того вытащить.
C:\>rmdir /?
RMDIR [/S] [/Q] [диск:]путь
/S Удаление дерева каталогов, т. е. не только указанного каталога, но и всех содержащихся в нем файлов и подкаталогов.
/Q Отключение запроса подтверждения при удалении дерева каталогов с помощью ключа /S.
Еще вспомнил, можно попробовать сначала удалить не через длинное имя файла, а через короткое, его можно увидеть через DIR /X.
В старых FAT для того, чтобы имя файла считалось удаленным, достаточно было первый байт имени на специальный код заменить, раньше делал, но как сейчас - не в курсе.
Крайний раз только таблицу разделов HEX-редактором правил, в какой-то утилите для партиций было.
Спасибо, попробую!
Ставите git для воньдовс. У него есть джентельменский набор линуксовых команд. Нужны ls, rm. С помощью ls -l шаблон добиваетесь вывода имени этого "неправильного" файла, ну чтобы только один выводился. Потом заменяете ls -l на rm. В шаблоне нужно использовать . и *
Проблемы кодировок были и в эпохи, когда не то что инета, UUCP еще не было.
ASCII и наследованные от него кодировки - проблемы мелочи пузатой.
Олдскульные посоны воевали с вариациями EBCDIC !
EBCDIC я бритвой на перфокартах вырезал. А кто-то и MTK-2 морзянкой на слух принимал.
Было ведь как, сегодня бланки сдал - завтра перфокарты получил
Кстати о перфокартах, у современных ПК в текстовом режиме BIOS ширина 80 знаков наследована от той самой перфокарты IBM. .
.
А сам этот стандарт перфокарты 12*80 задолго до первого компьютера появился, аж в 1928 году.
Поневоле байку про лошадиную задницу и шаттл вспомнишь
была такая , но писал свою... - и вот вопрос почему это раньше не считали ИИ ???
:)))))
25 лет статье, а проблема до сих пор актуальна.
Например - после установки винды первое, что надо сделать - это завести нового пользователя на латинице и переключиться на него.
Потому что программисты в массе своей - ленивые рукожопые мудаки, и программа при сохранении данных в (например) "C:\Users\Администратор" может вместо "Администратор" насоздавать каталогов из таких странных символов, что ни войти в него нельзя, ни удалить.
В статье кодировка КОИ-8 как бы сама по себе появилась, как решение проблемы русских литер в ASCII.
Это уже позднее решение. Русификация ASCII была проведена еще в семибитном мире кодировкой KOI-7.
Правда, за счет строчных букв, но за неимением места в таблице работали и так, на VAX VMS, например.
Терминал VT100 с escape-последовательностями знакомо (АР2E в ГОСТ 27466-87)? Драйвер ANSI.SYS и комбинация Сtrl-C оттуда пришли.
Вот в графических наследников этого терминала уже можно было загружать свои начертания литер ASCII.
http://consumer.stormway.ru/kod.htm
Вот замечательная старая статья о кодировках.
Я бы сказал, АШ-вский взгляд на кодировки.
Да! Узнаваемый стиль. Политота вместо реального обсуждения истории развития техники, возникающих проблем и путей их решения.
Особенно смешно смотреть, когда некоторые авторы АШ берут на вооружение формулировки из подобных статей
При этом абсолютно не обращают внимание на временные маркеры написания подобных статей
И абсолютно игнорируют тот факт, что проблема кодировок практически решена. utf-8 подерживает достаточное количество символов. Новые символы, которые признаются общеупотребительными, добавляются в список. Например, был добавлен символ русского рубля. ₽, U+20BD.
Отметим, что авторы стандарта категорически отказываются включать в него символы торговых марок, типа откушенного яблока. Максимум, в частных целях можно использовать символы в диапазонах, зарезервированных для частного использования.
Да, остаются проблемы совместимости различных версий различных программ. Но это - отдельный вопрос. Грубо говоря, надо различать информацию и способы представления/обработки этой инфориации.
Хорошая статья именно в техническом плане. А Ваша нелестная оценка основана на эмоциях и штампах.
Это и к Вам относится. UFF-8 принят аж в 1996 году: https://tools.ietf.org/html/rfc2044 В приведённой статье он упомянут несколько раз.
Но какое отношение имеет контейнер (способ кодировки), utf-8 к поднятой в статье проблеме нехватки кодов для азиатов?
Ага :)
Не знал. Достойно уважения.
В техническом плане к этой статье у меня претензий нет. Те выводы автора, что я процитировал, сейчас смотрятся, назову так, наивно. Но это не вина автора, а его беда - он оперировал той информацией. которая была актуальна на момент написания. У меня вопросы к сегодняшним авторам АШ, которые берут тогдашние выводы и тащат их в сегодня, не разбираясь в технической сути, что уже изменилось за это время.
Я, поиском по странице, нашел одно упоминание
Я что-то пропустил?
Да, моя некоторая небрежность. Есть таблица Unicode, а есть способ представления этой таблицы. Встречный вопрос, какая таблица Unicode была стандартизована на момент написания статьи, а какая действует сейчас? Где не хватало символов для азиатов и что с этим сейчас? 多謝 - какие это символы? В utf-8 вроде трёхбайтовые. Когда они появились?
Почему я написал так вольно? Когда в браузере кликнуть правую кнопку и выбрать "View Page Source" (у меня FireFox), что Вы увидите. Что-то такое
Никакой оговорки про версию стандарта unicode здесь не вижу.
Так я и писал "Вот замечательная старая статья о кодировках."
Я не знаю точно, когда написана статья. Судя по отсылке к версии Юникода 3.0 - между 09.1999 и 03.2001. Дата последнего RFC к UFT-8 - 11.2003.
Вы невнимательно прочитали статью. Я не изучал вопрос и пример не приведу. По поводу приведённых Вами пары иероглифов - ясно же написано:
Как сейчас дела обстоят - не интересовался. Судя по версии Юникода 13.0 - гораздо лучше :)
Гуглится за 2 мин: https://tools.ietf.org/html/rfc2044:
https://tools.ietf.org/html/rfc3629:
Char. number range | UTF-8 octet sequence (hexadecimal) | (binary) --------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxxСкажу честно, беседа начинает меня утомлять. Я был рад Вашей статье, с интересом прочитаю продолжение, если будет. Желаю успехов и внимания к деталям.
Спасибо! Подумаю, о чем интересно будет поговорить дальше. Надеюсь, уже не о кодировках. Тему кодировок постараюсь закрыть в этой теме - пока осталось разобраться, что случилось с кодировками имён файлов в этом случае https://aftershock.news/?q=comment/8677035#comment-8677035
Выполняю просьбу Дмитрия Михайловича aka blkpntr:
Огромное спасибо ему за интересные факты.
Спасибо за вопросы! Я как раз собирался следующую статью посвятить именно UTF-8. В том числе и про китайский язык.
Забегая вперёд:
Шрифты это вообще отдельный вопрос. Я бы не стал называть отличие traditional/simplified различием в шрифте. Соответствующие иероглифы, вообще говоря, состоят из разных элементов, несущих разный смысл. Примеры приведу. В будущей статье, спасибо на дополнительный поворот сюжета.
В гугле переводчике можно выбирать между упрощенными и традициоными иероглифами.
Например ,
дракон в традиционом написании - 龍 , в упрощенном 龙
черепаха龜 и 龟 соответственно.
Всё это - символы юникода, в чём легко убедиться, открыв файл в шестнадцатеричном виде. Первые два байта - как раз BOM.
Три
https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%80%D0%BA%D0%B5%D1%80_%D0%B...
Спасибо. Это я по привычке из UTF-16 сказал. Там BOM FE FF для UTF-16 BE,
либо FF FE для UTF-16 LE, всё логично - в каком порядке байты бома, в таком порядке и байты самих символов в тексте.
Для utf-8 вариант один EF BB BF, 3 байта. Расписываем его, как Вы сами же описали тут https://aftershock.news/?q=comment/8677781#comment-8677781
1110 1111, 10 111011, 10 111111 Что получаем? 16 бит - 1111 111011 111111, два байта - FE FF!
Так что мы оба правы!
Согласен!
Я нашел на хабре статью, о том, что не каждый человек может написать своё имя в Юникоде
https://habr.com/en/post/253381/
Со ссылкой на статью индийского IT-специалиста Адитья Мукереджи.
by Aditya Mukerjee on March 17th, 2015
Ещё раз спасибо. Для начала скормил "Адитья" гугл-переводчику. Указал с русского на бенгальский. Да. Получил আদিত্য
Открываю учебник бенгальского языка.
http://www.ukindia.com/zip/zben05.htm
А - вижу. ИT.. - можно найти (mIss the) д - идентифицировать пока не могу. И ... не могу понять, что это за недостающая буква.
Первая половинка "недостающей буквы" похожа на t'.
А что такое в бенгальском алавите "я" ?
Стало закрадываться сомнение, что статья - фейк. Или у парня свой диалект бенгальского. Попробую разобраться.
Зачем такую седую древность вынимать из личных закромов? Используйте кодировку UTF8. Это наше все, и никаких проблем с кракозябрами не будет, если только какой-нибудь древний "мамонт" до сих пор принимает почту на замшелый почтовый агент времен очаковских и покоренья Крыма.
Почтовик - всего лишь повод для разговоров.
Виндовс до сих пор для кириллических имен файлов в FATе (и коротких в VFATе) использует даже не СР-1251, а досовскую СP-866. Что у отдельных индивидумов может порождать проблемы. например, при переносе туда-обратно zip-ов на компы с макосью и линуксом, где имена файлов уже в UTF-8.
Пара вопросов из шуточного опросника на несколько сотен вопросов. По памяти, самого опросника под руками нет и поисковик тоже не находит :(
- Вы храните документацию на выведенные из эксплуатации системы?
- Вы её иногда читаете?
Вот и статья из того же материала :)
Мне больше понравилась другая пара вопросов из подобного теста:
По существу Вашего замечания ответил комментарием выше.