






Я уже писал о том, как меня поразил метод обучения AlphaGo, перед тем, как этот древний ИИ уделал чемпионов по шахматам и Го. ИИ играл сам с собой. И очень недолгое время.
Трудно переоценить прорыв, достигнутый китайцами в Tencent AI Lab. Без преувеличения можно сказать, что настал «момент AlphaGo Zero» для LLM. И это значит, что AGI уже совсем близко - практически за дверью.
Первый настоящий сверхразум был создан в 2017 компанией DeepMind. Это ИИ-система AlphaGo Zero, достигшая сверхчеловеческого (недостижимого для людей) класса игры в шахматы, играя сама с собой
Ключевым фактором успеха было то, что при обучении AlphaGo Zero не использовались наборы данных, полученные от экспертов-людей. Именно игра сама с собой без какого-либо участия людей и позволила ИИ-системе больше не быть ограниченной пределами человеческих знаний. И она вышла за эти пределы, оставив человечество далеко позади.
Если это произошло еще в 2017, почему же мы не говорим, что сверхразум уже достигнут?
Да потому, что AlphaGo Zero – это специализированный разум, достигший сверхчеловеческого уровня лишь играя в шахматы (а потом в Го и еще кое в чем).
А настоящий сверхразум (в современном понимании) должен уметь если не все, то очень многое.
Появившиеся 2 года назад большие языковые модели (LLM), в этом смысле, куда ближе к сверхразуму.
Они могут очень-очень много: писать романы и картины, сдавать экзамены и анализировать научные гипотезы, общаться с людьми практически на равных …
НО! Превосходить людей в чем либо, кроме бесконечного (по нашим меркам) объема знаний, LLM пока не могут. И потому они пока далеко не сверхразум (ведь не считает же мы сверхразумом Библиотеку Ленина, даже если к ней приделан автоматизированный поиск в ее фондах).
Причина, мешающая LLM стать сверхразумом, в том, что, обучаясь на человеческих данных, они ограничены пределами человеческих знаний.
И вот прорыв – исследователи Tencent AI Lab предложили и опробовали новый способ обучения LLM.
Он называется «Самостоятельная состязательная языковая игра» [1]. Его суть в том, что обучение модели идет без полученных от людей данных. Вместо этого, две копии LLM соревнуются между собой, играя в языковую игру под названием «Состязательное табу», придуманную китайцами для обучения ИИ еще в 2019 [2].
Первые экспериментальные результаты впечатляют (см. график).
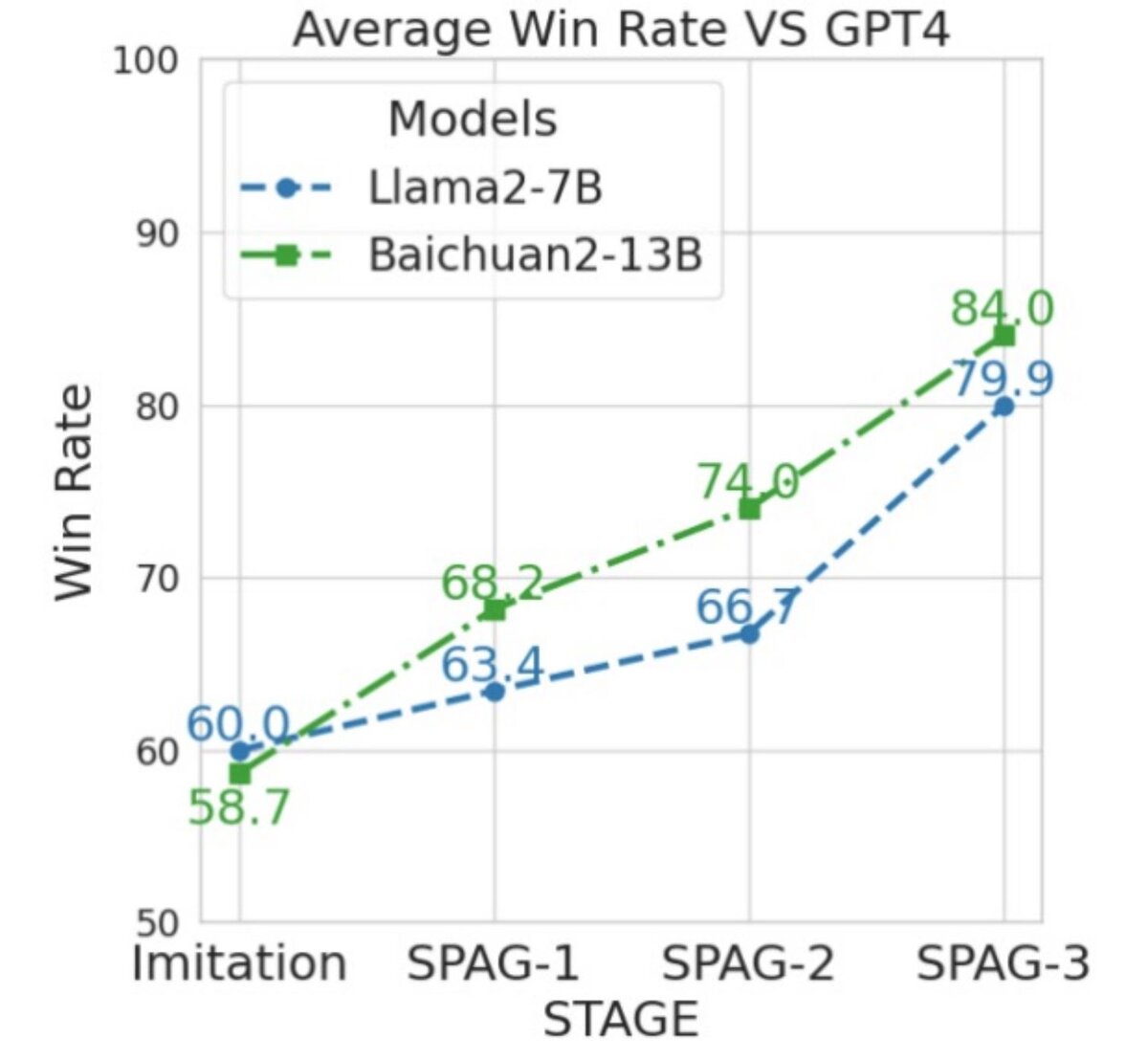
· Копии LLM, играя между собой, с каждой новой серией игр, выходят на все более высокий уровень игры в «Состязательное табу».
· На графике показаны результаты игр против GPT-4 двух не самых сильных и существенно меньших моделей после 1й, 2й и 3й серии их обучения на играх самих с собой.
Как видите, класс существенно растет.
И кто знает, что будет, когда число самообучающих серий станет не 3, а 3 тысячи?
Комментарии
Как то мутновато. Чему они обучаются?
Во 2-м источнике указано. Если я правильно понял, это игра что-то вроде детской, когда загадывают слово, и надо его угадать, задавая вопросы, на которые можно отвечать "да" или "нет". Перевод источника не очень понятен:
Интеллектуальная игра под названием "Состязательное табу", в которой атакующий и защищающийся соревнуются вокруг целевого слова. Атакующему поручено раскрыть целевое слово защищающегося, в то время как защищающемуся поручено обнаружить целевое слово до того, как оно будет названо атакующим. В "состязательном табу" успешный атакующий должен скрывать свои намерения и тонко побуждать защищающегося, в то время как соревнующийся защитник должен быть осторожен в своих высказываниях и делать вывод о намерениях атакующего. Такие языковые способности могут облегчить многие важные последующие задачи НЛП
Болтать - не камушки ворочать. Т.е. не техника, не наука, а очередная трепология. Искусственный болтун.
Ну, они могут (уже) научиться играть в человеческие игры лучше людей, но правила для этих игр все равно придуманы людьми... и это касается всего перечня обучений
Они уже лучше и быстрее людей считают. Это сверхразум?
Быстрее, жаль что не правильно, мне два числа не мог перемножить трёхзначное на пятизначное, я несколько раз просил исправиться - фиг там
Вот именно. Это всего лишь программы для решения определённых задач. И так к этому и нужно относиться. Я программист и пишу компьютерные программы. Мне ничего не стоит написать программу для игры в шахматы компьютера с самим собой. Проблема только в мощности памяти и быстродействии машины.
Интересно, чем будет обусловлена победа или поражение в игре двух абсолютно идентичных "ИИ" ?
Белые начинают и выигрывают.
Китайцы поступили в соответствии с цитатой Конфуция:
"А говорить с человеком, который разговора не достоин, — значит терять слова. Мудрый не теряет ни людей, ни слов.“
Почему АльфаГоуЗеро играет в шахматы лучше людей? Патамушта она сыграла больше партий, чем Магнус Карлсен и любой другой человек на этой планете. И не просто сыграла, она помнит все сыгранные партии и все сделанные ходы. И расставляет к ним оценки. Причём, делает это в реальном времени...
Получится ли у неё это не только в шахматы, а например, в физику, математику и... эмм... в литературу и музыку? Почему нет?
По крайней мере, она может уже сегодня писать код для следующих поколений самой себя. Да, это ни что иное, как эволюция, друзья мои!
Какие ещё есть условия для успешной эволюции? Конкуренция! Итак, создаём виртуальный мир и запускаем в него как минимум две конкурирующие друг с другом программы. С условием, что каждая из них пишет как минимум по два кода для следующего поколения...
Уфф... Ну вот, пожалуй и всё... )
не получится , так как физика это не шахматная доска
Но Альтман (наглая морда) почему-то уверен, что получится
У его "уверенности" есть финансовый интерес
Или же практический фундамент и финансовое основание
Бабло в сегменте ориентированном на "успешность" побеждает что угодно
Похоже, авторы эксперимента именно это и проделывают. А на этой неделе появилось несколько соревновательных рисующих ИИ. Сам еще не пробовал, в связи с переездом. Вернусь домой - попробую.
Если попробуете расскажите пожалуйста, это интересно.
И я так понимаю это новый тренд такой - делать так, что бы ии соревновались с друг другом. От перспектив даже страшно становится, всё это так быстро развивается, что будет завтра?
Ну не обучения, а дообучения, все же языковые модели берут за основу естественные языки (как и в данном примере взяты за основу уже готовые, распространяемые модели baichuan2 и LLama2). К тому же если язык модели начинает "дрейфовать" в сторону от носителей языка это не плюс а минус, и я думаю такой задачи исследователи перед собой не ставили.
В этом эксперименте единственное полезное, это некоторое оттачивание семантики и возможно уменьшение стандартности ответов. Что для части задач плюс, а для другой минус. Хотя работа направленная на изучение приемов управления уровнем шаблонности ответов безусловно принесет пользу, прорыва прорыва тут как то не наблюдается.
Согласен. Типа как на конференции – обменялись опытом и пошли дальше.
А они пока и не публиковали результатов. Только застолбили базу и указали на области применения: юриспруденция, право и (sic!) НЛП. Може и вообще не будут делиться результатами, а сразу применят на нас.
НЛП это - Обработка текстов на естественном языке (Natural Language Processing, NLP). Хотя шутка засчитана. Сами большие лингвистические модели имеют в своей основе максимально расплывчатые ответы, что бы читающий/проверяющий сам увидел в нем ответ. "Красота в глазах смотрящего/ книга зеркало души". Ну или если математические вычисления - ответ функции с переменными в виде векторов слов должны быть максимально близкими к такому же вычислению заранее вычесленному правильного ответа.
Каак? Разве это не Neuro-linguistic programming?)
Нет математического описания разума. По этому максимум что можно получить, новые классы векторов и весов, что качественно не изменит. Моё мнение
Масса людей думает над этим. Вот недавно один йуный дарований дал определение сознания: чувство ментальных образов и ощущений:
И почему ты так уверен, что в нейронной сетке твоей башки не крутятся те же вектора, сортируясь по весам?
Объяснять одно не формализованное другим или другими не формализованными понятиями - подход гуманитариев. Мозг имеет более сложную структуру имеющие в своем составе некоторые области/поля коры с более высокоинтегрированными между собой нейронами - ничего подобного в железяках нет.
Очередное гуманитарное теребонькание на ии. Как же уже тошнит от темы, ей богу. Оставьте её специалистам.
Осмелюсь спросить, в какой негуманитарной области являетесь специалистом? Статей не пишете. Судя по комментам - баран широкого профиля. Так в чём специалист? Должность? Степень?
Не слышал раньше про Adversarial Taboo.
Загаданное слово должно быть непростым, иначе большой шанс случайно его выдать. А в то же время, чем специализированнее слово, тем больше шансов у обороняющегося его угадать.
Интересно, в общем.
Ну, в той детской игре любое слово угадывается примерно за 10-20 итераций. Но, возможно тут "этодругое"
Соревнуются два ИИ. Ставим тему "Война". До результата Человечество может не дожить.
Вы его к классической РТС подключите и посмотрим кто кого засырит
Не уверен насчет РТС, но в играх на реакцию ИИ давно уделывает кожаных
Ну так и обычный ИИ всё делает быстрее чем ты успеваешь мышкой и кнопками клацать
Но есть вещи, которым плевать на ваше микро...
Ровно та стадия, когда толком непонятно, выглядит и звучит внушительно. Нужно монетизировать и срочно продавать. Пока прокатывает словесный блуд: аффирмации, разборы, марафоны желаний....
Перспективный чат детектед! Сим повелеваю - внести запись в реестр самых обсуждаемых за последние 4 часа.
Честно говоря, ничего особенно нового.
Эволюционным алгоритмам уже достаточно много лет. Судя по всему, их сумели приспособить под языковые модели и добавили много-много вычислительных мощностей для ускорения обучения.
В этом случае две или больше моделей эволюционируют совместно.
Будет интересно посмотреть, к чему это приведет.
Исходные датасеты, скорее всего никто не рскроет.
Я понимаю ИИ начертит суперстанок. А супервангога не понимаю.
Нахрена нам суперфрики?
А я как инженер и художник, понимаю и то и другое. Хоть Ван Гог, пмсм, не самый великий художник.
Из психов самый знаменитый, а как инженер вообще ниочем.
Хотя воспользовавшись методом натяжения совы ВанГога можно назвать изобретателем принтера
Просто к LLM прикрутили конкурентное обучение (GAN).
=======================
Разработка нейросетей (в отличие от проектирования мостов) специфична весьма опосредованным влиянием разработчика на результат.
В руках разработчика - обучающий корпус, архитектура и функция потерь.
В некоторых задача функция потерь весьма неочевидна. Например, в явном виде вычислить различие перцептивных впечатлений от двух отрезков звука пока не удалось.
И тут возникла идея состязательного обучения, суть которого в том, что функция потерь обучается одновременно с обучением собственно сети.
Классический GAN в синтезе речи по тексту:
1. обучается сеть - синтезатор, задача которой - синтезировать по тексту натурально звучащую речь. Но разработчик сам не знает, как измерить "натуральность". Поэтому вводится состязательность.
2. Параллельно обучается сеть-детектор, задача которой - определить, натуральный звук ей предъявлен или синтезированный.
3. Функция потерь для синтезатора - успешность детектора, функция потерь детектора - ошибки детектора.
Плюс некоторые чисто технические моменты, чтобы это всё не скатилось в сингулярность.
==================
Результат китайцев - придумывание такой конструкции для LLM.
И (пока) - всё.